PL-BERT
- Phoneme-Level BERT for Enhanced Prosody of Text-to-Speech with Grapheme Predictions
- PL-BERT Official Github
StyleTTS2 한국어 버전으로 학습하기 위해서
PLBERT
Abstract
Large-scale pretrained 언어 모델들은 TTS 모델이 더 자연스러운 prosodic 패턴을 만들 수 있도록 해서 자연스러운 음성 합성을 도움
일반적으로 기존 TTS에서 사용되는 모델들은 word-level, sup-phoneme-level로 학습하거나 기존 입력에 phoneme를 추가하여 함께 학습
하지만 phoneme 정보만 입력으로 사용되는 TTS에는 적합하지 않음
따라서 마스킹 된 phoneme을 예측하면서 해당 phoneme에 대응되는 grapheme을 같이 예측하는 Phoneme-Level BERT (PL-BERT)를 제시
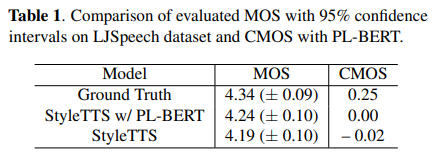
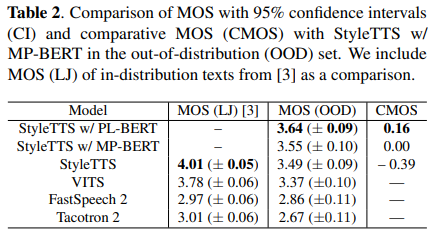
주관적인 평과 결과, PL-BERT encoder가 SOTA 모델인 StyleTTS와 비교했을 때, out-of-distribution (OOD) 텍스트에 대해서 음성 합성의 자연스러움을 평가한 MOS 가 향상함을 확인
Introduction
TTS의 발전에도, 사람 음성에 존재하는 prosody와 emotion과 같은 풍부한 정보들 때문에 사람과 같이 자연스럽고 감정적인 음성을 만드는 것은 어려움
기존의 많은 TTS 모델들이 위와 같은 어려움을 가지는 이유는 아래와 같음
- 가존의 많은 TTS 모델들은 음성에서 tone이나 prosody를 잘 찾지 못함
- 외국어의 정확한 intonation, emotion 학습하기 위해서 수백 시간의 입력 데이터가 필요
- 이런 많은 데이터에도 원어민이 아닌 사람은 intonation (억양) 과 prosody (운율)의 차이로 쉽게 원어민과 구별됨
- Annotation이 필요하기 때문에 이런 수백 시간의 데이터는 거의 존재하지 않음
몇 시간의 데이터를 사용하여 학습한 모델이, phoneme만을 입력으로 받아서 자연스러운 prosody 패턴을 포착하는 것은 쉽지 않음
이런 문제는 large-scale pretrained 모델을 사용하면 완화가 되고, 특히 BERT는 word level, character level, sentence level에서 TTS 성능 향상에 효과적인 것이 증명이 됨
이 논문에서는 Phoneme-level로 연구된 BERT 모델을 제시
이 모델은 단어 전체를 마스킹 한 phoneme을 예측하는 것과 그 phoneme의 grapheme 예측하는 것을 결합
- Grapheme 이나 sup-phoneme 단위의 입력이 사용되지 않음
이 연구의 contribution은 각 phoneme에 대응되는 grapheme들을 예측하는 추가적인 pretext 작업에 있음
- P2G (Phoneme-to-Grapheme)
언어 모델이 phoneme-level을 직접적으로 학습하면서, 모델은 phoneme, word, semantic 간의 상호 작용을 깊이 이해하는 representation을 생성할 수 있고, 이로 인해 후속 TTS 작업의 성능을 향상시킴
주관적인 평가의 결과, PL-BERT를 이용하여 out-of-distribution (OOD) 텍스트를 합성한 음성이 SOTA 모델인 StyleTTS 모델보다 더 자연스러움
- OOD : 분포에 벗어난, 즉 학습에 사용되지 않은 데이터
In-distribution 텍스트에 대한 평가 결과는 OOD 텍스트 만큼 효과적이지 않음
TTS 연구에서 in-distribution, out-of distribution 텍스트 간의 성능 차이를 줄일 수 있는 연구를 진행하기를 제안함
Phoneme-Level BERT
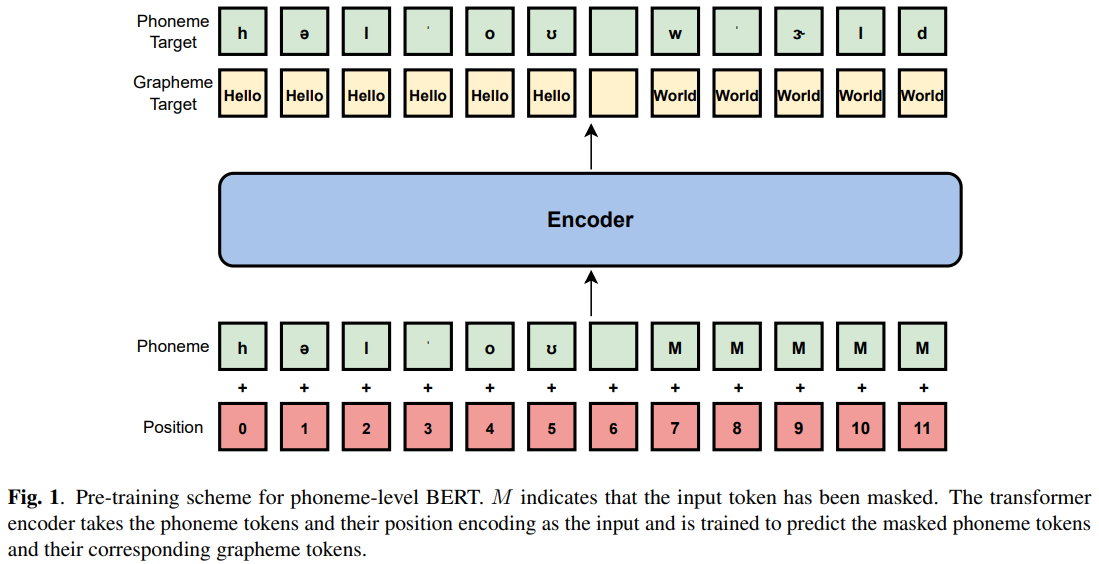
PL-BERT는 입력으로 phoneme 만 사용하하고 grapheme과 sup-phoneme을사용하지 않기 때문에 학습과 추론 속도를 빠르게 할 수 있음
- 한 언어에서 사용되는 phoneme의 수는 제한적, 영어는 약 4~50 개의 음소 존재
- Grapheme 나 sup-phoneme 사용하면 다양한 조합이 생성되어 매우 많은 v 또는 phoneme 단위 필요
Phoneme 외의 추가적인 representation은 학습되지 않은 단어 또는 sup-phoneme 단위가 추론 중에 발생할 수 있는 out-of-vocabulary 문제 해결 가능
- Phoneme 수는 상대적으로 제한적이고, 모든 단어나 발음이 결국 phoneme으로 구성
- 새로운 단어가 등장해도 안정적으로 처리가 가능
Pre-traiend 된 인코더를 모든 TTS 시스템의 텍스트 인코더에 즉시 대체하여 적용 가능
Pre-training
BERT와 마찬가지로, phoneme-grapheme 짝을 이룬 데이터 셋을 이용하여 self-supervised learning 방식으로 학습
- 레이블이 없는 데이터에서도 일부를 마스킹하여 모델이 스스로 예측하도록 학습하는 방식
외부의 G2P 툴을 이용하여 grapheme과 대응되는 phoneme 데이터 쌍 생성
Grapheme은 character에서 sub-word 단위 , whole word까지 다양한 범위로 나타낼 수 있음
일본어와 같은 언어에서는 문맥에 따라 문자의 발음이 변할 수 있기 때문에, 동적 프로그래밍 알고리즘을 이용한 추가적인 grapheme-phoneme alignment 필요할 수도 있음
그러나 추가적인 grapheme-phoneme alignment를 피하기 위해서 전체 단어(whole words)를 토큰으로 사용
Training objectives
BERT와 마찬가지로, 마지막 layer의 hidden state로부터 linear projection과 softmax를 통과한 값을 사용하여 마스킹 된 phoneme과 grapheme을 예측
이 때, 예측한 각 값에 대한 loss 존재하고 두 loss 모두 cross entropy 사용
-
MLM Loss
- 마스킹 된 입력 phoneme을 예측할 때 사용하는 loss
- 마스킹 된 token에만 적용
-
P2G Loss
- 모든 입력 phoneme에서 입력으로 들어갔을 때, 해당하는 grapheme 예측할 때 사용하는 loss
Masking Strategy
Phoneme-level 언어 모델을 학습하는 것이 목표이기 때문에, 모델이 의미있는 semantic representation을 학습할 수 있도록 word-level로 마스킹
- Whole-word masking 이라고 불리며, phoneme이 입력으로 들어가는 BERT 모델에 가장 효과적
각 sequence에서 15%의 grapheme에 해당되는 phoneme들이 랜덤으로 마스킹
Graphem 가 선택되면 phoneme token은 80% time (확률인가…?) MSK token 으로 대체
10%의 time으로 랜덤한 phoneme token으로 대체
10%의 time으로 변경되지 않음
EXPERIMENTS
Datasets
Text Pre-training Data
영어 Wikipedia 말뭉치 데이터로 학습
- 6,280,802 개의 글들로 구성이 되어있고 대략 74M 개의 문장이 존재
텍스트는 NeMo를 사용하여 각 단어의 발음과 일치하도록 normalization
Phonemizer를 사용하여 텍스트를 IPA 형식으로 변환
- eSpeak backend
TTS Fine-tuning Data
StyleTTS2 논문 참고
Results
TTS Performance
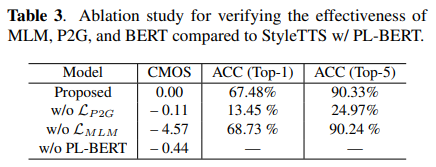
Ablation Study
Conclusion
phoneme-level BERT 모델을 제시
이 언어 모델은 문맥을 고려한 임베딩을 생성하여 TTS의 결과가 자연스럽고 prosody를 잘 반영하도록 함
Phoneme이 입력으로 사용되기 때문에 학습과 추론 시에 필요한 리소스를 줄일 수 있음
BERT 인코더가 TTS 모델에 맞춰 fine-tuning 되지 않더라도 baseline StyleTTS보다 좋은 성능을 냄
Pre-training을 진행하여 MP-BERT보다 OOD 텍스트에 대해서 좋은 성능을 보임
기존에 존재하는 TTS 모델들이 in-distribution과 OOD 텍스트에 대한 성능 차이를 보임을 확인했고, 실제 상황에서는 in-distribution 텍스트가 많이 사용되지 않기 때문에, 추후의 연구가 OOD 텍스트에 대한 성능 개발에 맞춰 진행되어야 함