UNet++
참고
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
2018
Introduction
Segmentation에 사용하는 encoder-decoder 구조는 skip-connection 적용하여 decoder sub-network에서 나온는 deep, semantic, coarse-grained feature map과 encoder에서 나오는 shallow, low-level, fine-grained feature map을 결합함
Skip connection을 이용하면 fine-grained한 디테일을 잘 잡아낼 수 있음
의학 쪽에서는 일반적인 image segmentation보다 더 효과적으로 세부적인 디테일을 잘 segmentation 하는 모델 요구함
이를 위해, 더 정확한 의학 이미지 segmentation 모델인 UNet++ 을 제안함
이 네트워크는 중첩되고 dense한 skip connection을 이용한 새로운 segmentation 구조
이 아키텍쳐의 기본 가설은 encoder에서 얻는 고해상도의 feature map이 decoder 네트워크와 대응되는 풍부한 semantic 정보를 가지는 feature map과 합쳐지기 전에 점차적으로 풍부해질 때, 모델이 효과적으로 object의 fine-grained한 디테일 얻을 수 있음
또한 encoder와 decoder에서 얻어지는 feature map이 의미론적으로 (semantically) 비슷하기 때문에 네트워크의 학습이 더 쉬워짐
실험 결과에 따르면, 이 모델은 U-Net과 wise U-Net보다 더 좋은 성능을 얻음
Proposed Network Architecture: UNet++
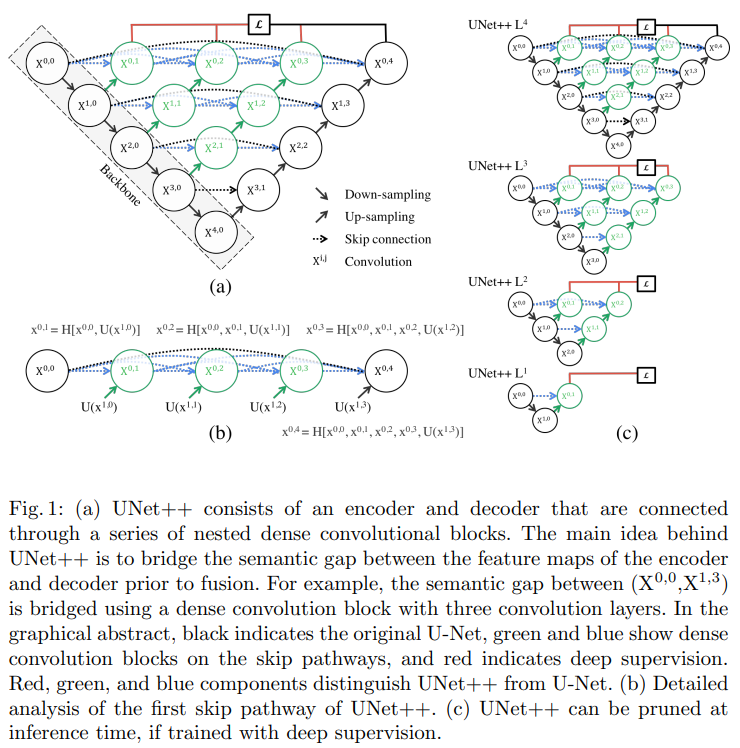
Fig. 1 (a)를 통해 UNet++의 전체적인 구조와 U-Net과의 차이를 확인 가능
U-Net (검은색 요소) 과의 차이는 re-designed skip pathways (초록, 파란색 요소)와 deep supervision (빨간색 요소) 가 있음
Re-designed skip pathways
UNet++는 convolution layer의 수가 피라미드 레벨에 따라 달라지는 dense한 convolution block으로 skip connection이 구성됨
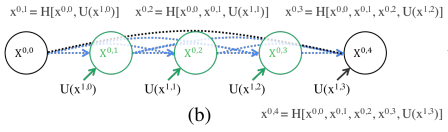
$\text{X}^{0,0}$와 $\text{X}^{1,3}$ 사이에는 3개의 convolution layer를 가지는 dense convolution block으로 구성
각 convolution layer 앞에는 같은 dense block의 이전 convolution의 출력과 하위 dense block 결과를 upsampling 한 출력을 concat
Dense convolution block은 encoder feature map의 semantic 레벨을 decoder에서 대기중인 feature map에 더 비슷하게 만듦
Encoder와 decoder의 feature map이 의미론적으로 유사하기 때문에 최적화 하기가 더 쉬워짐
- $x^{i,j}$는 노드 $\text{X}^{i,j}$의 결과
- $i$는 downsampling layer의 index
- $j$는 skip path에 존재하는 dense blockdml convolution layer의 index
- $H(\cdot )$ : convolution 연산과 activation 연산
- $U(\cdot )$: Upsamping layer
- \(\left [ \right ]\) : concatenation layer
레벨 $j=0$의 노드는 encoder의 이전 layer의 값 하나만을 입력으로 가짐
레벨 $j=1$의 노드는 encoder의 연속된 두 레벨의 encoder sub-network 값 두 개를 입력을 받음
$j>1$인 노드들은 $j+1$ input을 받는데, $j+1$input은 같은 skip pathway에서의 이전 $j$의 output과 하위 skip pathway에서 upsampling 한 output을 받음
Deep supervision
모델이 2가지 모드로 연산 가능
- Accurate mode
- Fast mode
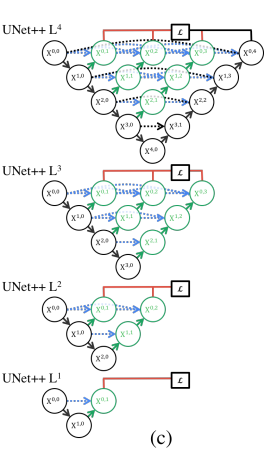
Accurate mode는 모든 segmentation branch의 결과를 평균한 값
Fast mode는 하나의 segmentation branch에서 segmentation map을 선택하고, 이에 따라 모델의 pruning과 속도가 결정이 됨
중첩된 skip pathway로 인해, UNet++는 다양한 semantic 레벨에서의 full resolution feature map이 생성됨 \(\{ x^{0,j} , j\in {1, 2, 3, 4} \}\).
Loss function으로 binary cross-entropy와 dice coefficient를 각 4개의 semantic 레벨에 적용함
\[L(Y,\hat{Y})=-\frac{1}{N}\sum_{b=1}^{N}\left (\frac{1}{2}\cdot Y_{b}\cdot log{\hat{Y}_{b}} + \frac{2\cdot Y_{b} \cdot \hat{Y}_{b}}{Y_{b} +\hat{Y}_{b}} \right )\]- $N$ : batch 크기
요약하자면 UNet과 UNet++는 세 가지 점에서 다름
- Skip pathway에 convolution layer 존재 (Fig. 1 (a) 초록색)
- Encoder와 decoder feature map semantic gap 연결, 즉, 줄여줌
- Skip pathway에서 dense skip connection을 가짐 (Fig. 1 (a) 파란색)
- Gradient 흐름을 향상, 즉 학습이 잘 되게 만듦
- Deep supervision (Fig. 1 (a) 빨간색)
Experiments
Datasets
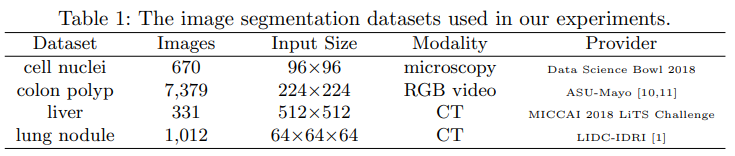
4개의 데이터 셋 이용
Baseline models

비교를 위해, U-Net과 wide U-Net을 사용
U-Net은 segmentation 성능 비교에 기본적으로 사용되고, wide U-Net은 UNet++와 비슷한 파라미터 수를 가지고 있기 때문에 선택
Results
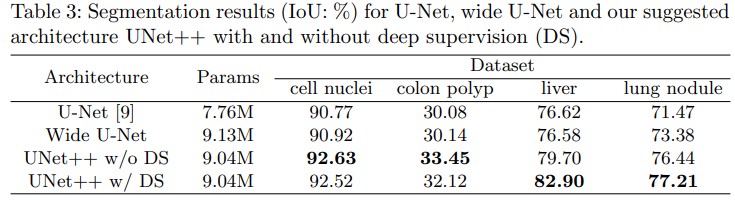
Wide U-Net은 liver segmentation을 제외하고 U-Net보다 성능이 좋음
- 성능 향상의 이유는 parameter 수가 늘어났기 때문
Deep supervision을 사용하지 않은 UNet++는 U-Net과 wide U-Net보다 평균적으로 IoU 성능이 각각 2.8, 3.3 정도 향상됨
Deep supervision을 사용한 UNet++는 deep supervision을 사용하지 않을 때 보다 평균적으로 0.6 정도 성능이 향상
Deep supervision을 사용한 경우에는, liver와 lung nodule segmentation 에서는 사용하지 않았을 때 보다 성능이 높았지만 cell nuclei과 colon polyp segmentation에서는 사용하지 않은 경우에 성능이 더 좋음
polyp과 liver는 비디오 프레임과 CT에서 다양한 크기로 나타나기 때문에 모든 segmentation branch를 사용하는 (deep supervision) multi-scale 방식이 더 정확한 segmentation을 위해서 필요함
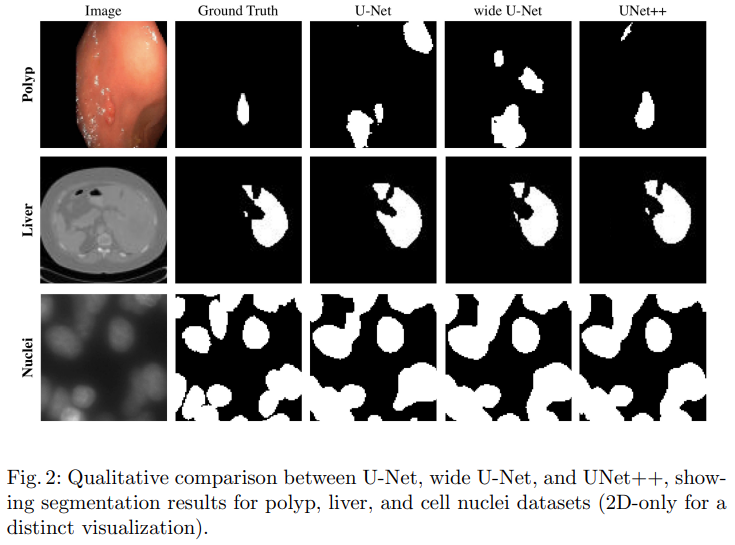
Model pruning
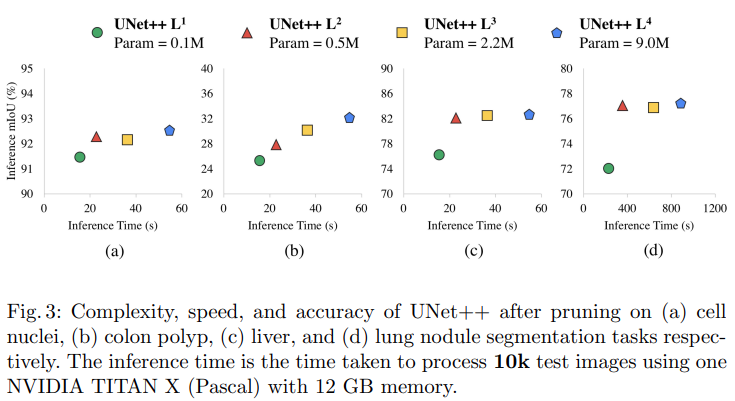
UNet++ $\text{L}^{3}$은 평균적으로 inference 시간을 32.2% 줄이면서 IoU는 0.6 point 정도 밖에 손실이 생기지 않음
더 많이 pruning을 진행하면 속도는 빨라지나 정확도가 많이 떨어짐
Conclusion
더 정확하게 medical image를 segmentation 하기 위해서 UNet++ 를 제시
제시한 architecture는 re-designed skip pathway와 deep supervision을 이용
Re-designed skip pathway를 사용하면 encoder와 decoder 사이의 semantic gap을 줄일 수 있고 이로 인해 최적화 문제를 간단하게 함
Deep supervision를 사용하면 다양한 크기의 object를 정확하게 segmentation 할 수 있음
4개의 medical image dataset을 이용하여 평가를 진행함
실험의 결과로 deep supervision을 사용한 UNet++가 U-Net과 wide U-Net보다 평군 IoU 성능이 각각 3.9, 3.4 포인트 증가함을 확인