Deeplabv3+
참고
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
ECCV 2018
Introduction
Neural network를 이용하는 Segmentation 에는 spatial pyramid pooling module을 이용하는 방법과 encoder-decoder를 이용하는 방법 2가지로 크게 나눌 수 있음
전자는 다른 해상도에서 feature를 pooling 하기 때문에 풍부한 contextual 정보를 얻을 수 있고, encoder-decoder를 사용하면 object의 경계를 정확하게 얻을 수 있음
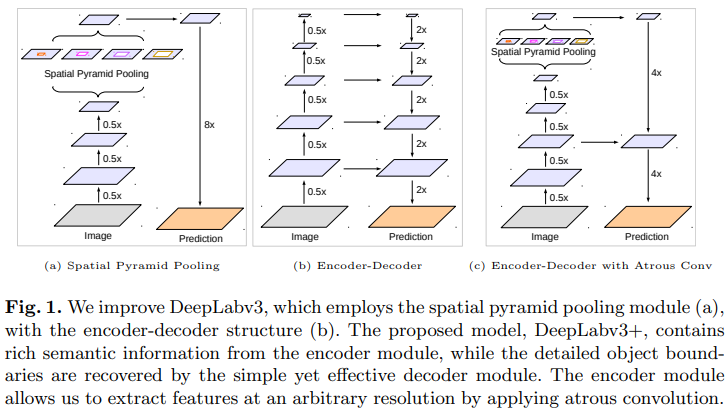
Contextual한 정보를 다양한 scale에서 얻기 위해 DeepLabv3는 병렬적으로 다른 비율의 atrous convolution을 적용 (Atrous Spatial Pyramid Pooling, ASPP)
이렇게 얻은 풍부한 semantic 정보는 마지막 feature map에서 인코딩되지만 pooling과 stride 연산을 사용하는 convolution을 사용할 때 발생하는 object의 경계 등의 디테일한 정보가 사라지는 문제는 존재
이런 문제는 atrous convolution을 사용하여 조금 더 dense한 feature map을 얻으면 완화할 수 있으나, 현재 SOTA 모델의 네트워크 디자인과 GPU 메모리 한계를 고려하면 계산 상 불가능
하지만, encoder-decoder를 사용하면 encoder에서 더 빠른 계산이 가능하며, decoder에서 object의 경계를 잘 찾을 수 있음
이런 두 가지 방법의 장점들을 사용하기 위해, multi-scale contextual 정보를 통합하여 encoder-decoder 네트워크에서 encoder 모듈을 더 풍부하게 할 것을 제안
DeepLabv3를 확장한 DeepLabv3+ 는 object의 경계를 잘 찾을 수 있는 효과적이고 간단한 decoder module을 제시함
Contribution은 아래와 같음
- DeepLabv3의 encoder 모듈과, 간단하지만 효과적인 decoder 모듈 사용한 새로운 encoder-decoder 구조 제안
- Atrous convolution을 사용하여 feature 해상도를 조절할 수 있도록 함
- Precision과 runtime의 trade-off
- Segmentation을 위해 Xception 모델을 채택하고 depthwise seperable convolution을 ASPP 모듈과 decoder 모듈에 적용하여 빠르고 강력한 encoder-decoder 네트워크 만듦
- PASCAL VOC 2012와 Cityscape dataset에서 SOTA 성능 달성하였고 디자인의 선택과 모델의 변화에 대한 다양한 분석 제공
Related Work
Spatial pyramid pooling
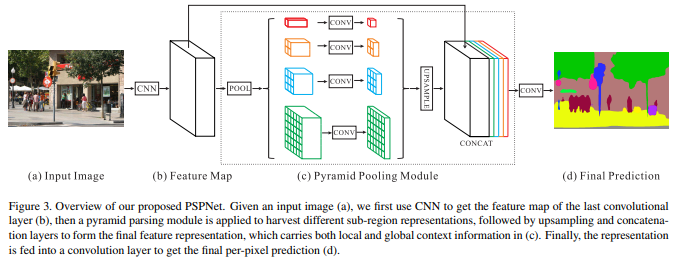
모델들은 여러 grid scale에서 Spatial Pyramid Pooling (SPP)를 수행하거나 병렬적으로 atrous convolution을 다른 비율로 적용하는 Atrous Spatial Pyramid Pooling (ASPP)를 수행함
이런 모델들은 multi-scale 정보들을 사용해서 segmentation에서 좋은 성능을 보여줌
Encoder-decoder
Encoder 모듈은 feature map의 해상도를 점차적으로 줄이고 semantic 정보를 얻음
Decoder 모듈은 점차적으로 spatial 정보를 얻음
Deeplabv3의 encoder 모듈을 사용하고, 더 날카로운, 즉 정확한 object의 경계를 획득하기 위한 간단하고 효과적은 decoder 모듈 사용
Depthwise separable convolution
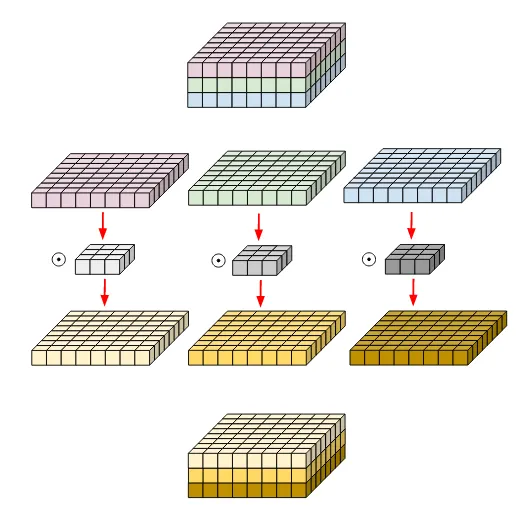
Depthwise seperable convolution (위의 그림) 과 group convolution은 성능을 유지하면서 계산 비용과 파라미터의 수를 줄일 수 있는 효과적인 방법
Xception을 이용하여 semantic segmentation task에서 정확도와 속도 측면에서 좋은 성능을 보임
Methods
Encoder-Decoder with Atrous Convolution
Atrous convolution
일반적인 convolution 연산과는 다르게, 커널 픽셀간 사이의 빈 공간이 존재하는 구조를 가짐
빈 공간의 크기를 조절하여 필터가 보는 영역을 조절
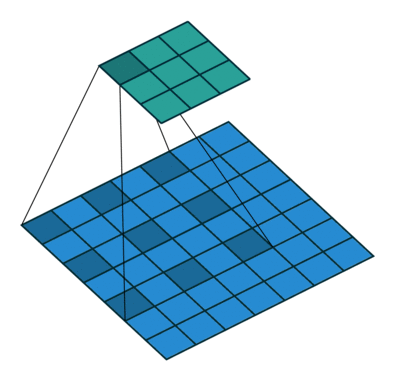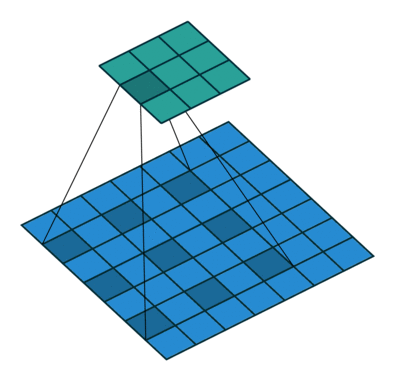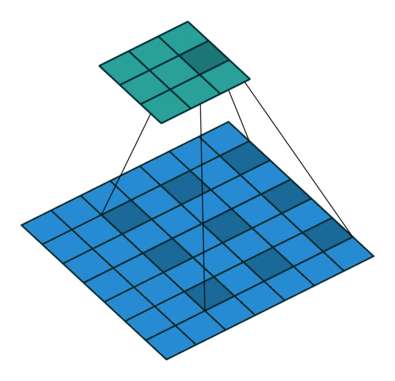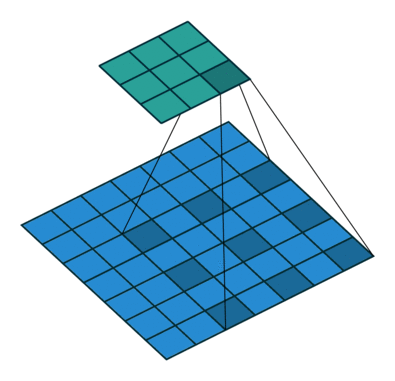
Astrous convolution을 이용하면 feature의 해상도 (resolution) 을 조절할 수 있고, 다양한 scale의 정보를 얻기 위해 convolution filter의 field-of-view 조절 가능하고, convolution 연산을 일반화 가능
- \(\mathbf{y}[\mathbf{i}]\): \(\mathbf{i}\) 위치에서의 output feature map
- \(\mathbf{w}\) : convolution filter
-
\(\mathbf{x}\) : input feature
- $r$ : atrous rate, dilation rate
$r=1$이면 일반적인 convolution 연산이고, 이 비율을 조절하면서 필터의 field-of-view를 조절 가능
동일한 계산량과 파라미터 수를 유지하면서 convolution 연산을 하면서 디테일한 정보가 줄어들고 추상화 되는 것을 어느정도 방지할 수 있음
Depthwise separable convolution
Depthwise convolution 연산 후에, pointwise convolution을 하는 연산이고 계산 복잡도를 많이 줄일 수 있음
Depthwise convolution은 각 channel 별로 독립적으로 spatial convolution 실행
Pointwise convolution은 depthwise convolution 결과를 합쳐주는 역할
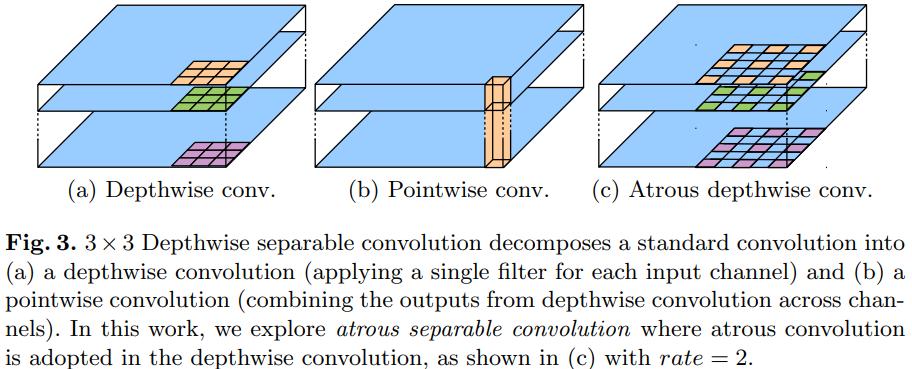
이 논문에서는 atrous separable convolution 사용하는데 이는, depthwise convolution 연산에서 atrous convolution 연산을 적용한 방법
이를 통해서 성능을 유지하면서 계산 복잡도를 줄일 수 있음
DeepLabv3 as encoder
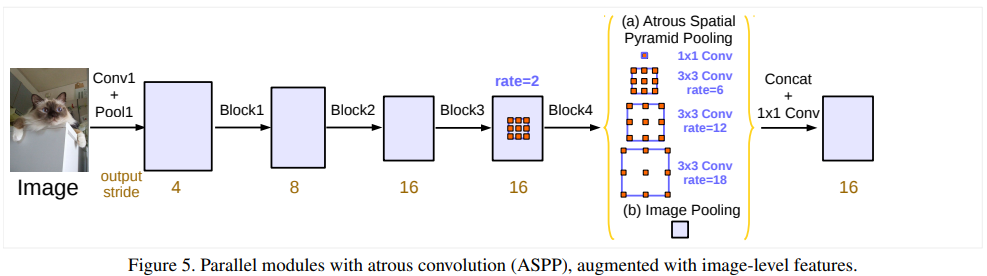
DeepLabv3는 atrous convolution을 이용하여 feature를 추출
Output stride는 input image와 output의 resolution 비율 의미
- Output stride가 4이면 input image보다 4배 줄어든 것을 확인
또한 DeepLabv3는 ASPP (Atrous Spatial Pyramid Convolution) 모듈을 사용하여 다른 rate의 atrous를 사용하여 다양한 scale의 image-level feature를 얻을 수 있음
Encoder-decoder 구조의 encoder 출력으로 기존의 DeepLabv3 에서 logit 전의 마지막 feautre map 사용
Encodr의 output은 256개의 풍부한 semantic 정보를 가짐
Proposed decoder
DeepLabv3에서 나온 encoder feature의 output stride는 보통 16, 즉
이 feature는 factor 16으로 bilinearly upsampling하는 naive 한 decoder 모듈을 사용 가능
하지만, 이는 object의 segmentation 디테일이 사라짐
아래의 그림 Fig. 2에서 보여주는 간단하지만 효과적인 ecoder 모듈 사용
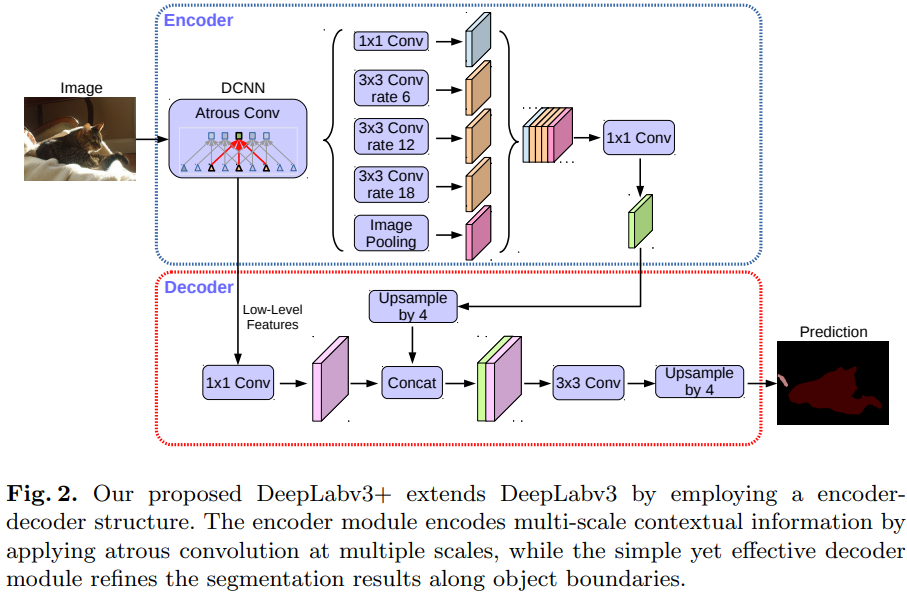
Encoder feature는 factor 4의 bilinearly upsampling을 수행
그 후 같은 spatial resolution을 가지는 backbone의 low-level feature와 concat
Concat 하기 전, low-level feature에 $1\times 1$ convolution을 적용하여 channel 줄임
Low-level feature는 많은 수의 channel 수 (256 또는 512)를 가지는데 이는 정보가 풍부한 encoder feature보다 더 중요하게 여겨 학습을 어렵게 할 수 있기 때문에 channel 수를 줄임
Concat 한 후, $3\times 3$ convolution을 적용하여 feature들을 정제하고, factor가 4인 bilinear upsampling을 거침
이 때 , $3\times 3$ convolution 을 적용하여 더 정확한 segmentation 결과를 얻을 수 있음
Modified Aligned Xception
Segmentation task를 위해 Xception 모델을 수정
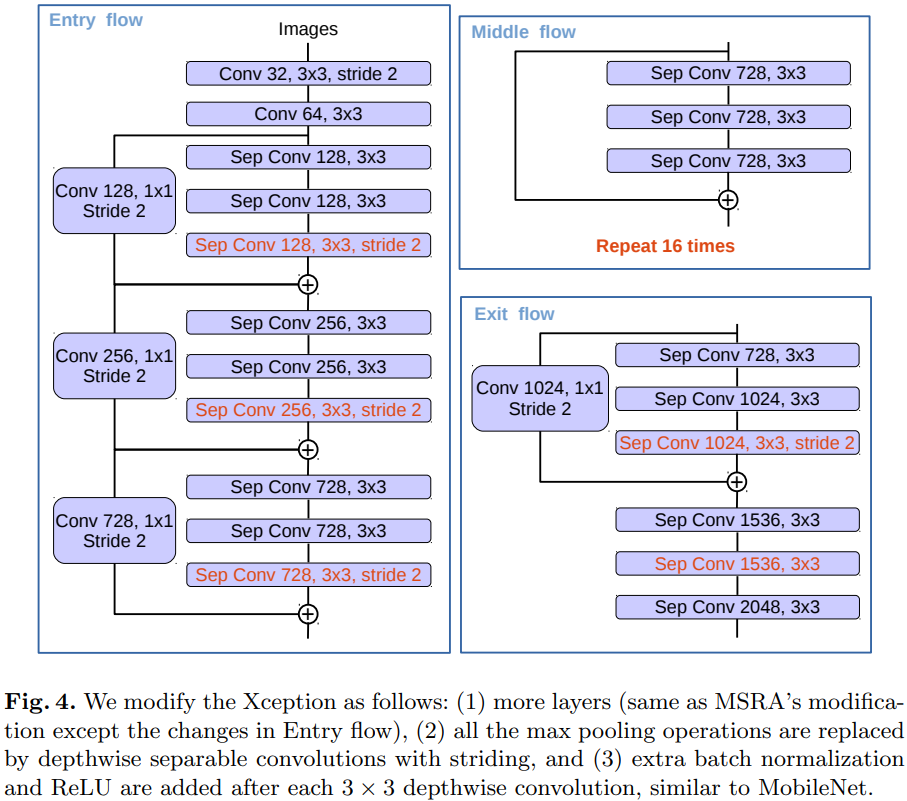
Xception을 더 깊게 만들었지만 빠른 계산과 메모리 효율성을 위해 entry flow는 수정하지 않음
모든 max pooling 연산은 stride를 가지는 depthwise separable convolution로 대체함
- 원하는 해상도로 feature map을 얻을 수 있는 atrous separable convolution 적용 가능
$3\times 3$ convolution 을 적용한 후에 batch normalization과 ReLU를 거침
Experimental Evaluation
Decoder Design Choices

- Low level feature를 decoder에서 사용할 때, $1\times 1$ convolution 을 사용하여 channel 수를 줄이는데 channel 을 얼마나 줄일 때 가장 성능이 좋은지 확인하기 위함
- 채널을 48로 줄였을 때의 성능이 가장 좋음
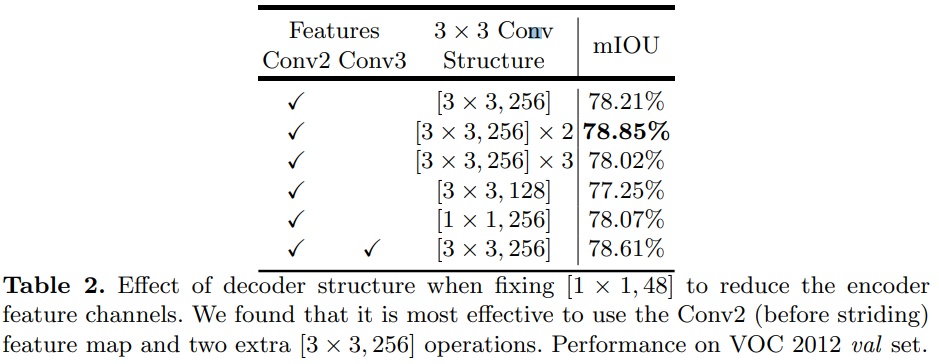
- Low-level feature로 Conv2에서 나오는 feature를 사용할 것인지 Conv3에서 나오는 feature를 사용할 것인지 둘 다 사용할 것인지를 나타냄
- $3\times 3$ Conv는 decoder에서 concat 후 object의 경계를 선명하게 나타내기 위해 사용하는 convolution의 구조
- 결과를 보니, Conv2에서 나오는 low-level feature를 이용하고, $[3\times 3, 256]$ 을 두 번 연속 연산해준 결과가 가장 좋은 성능을 보임
ResNet-101 as Network Backbone
첫 번째 architecture에 대한 실험 결과
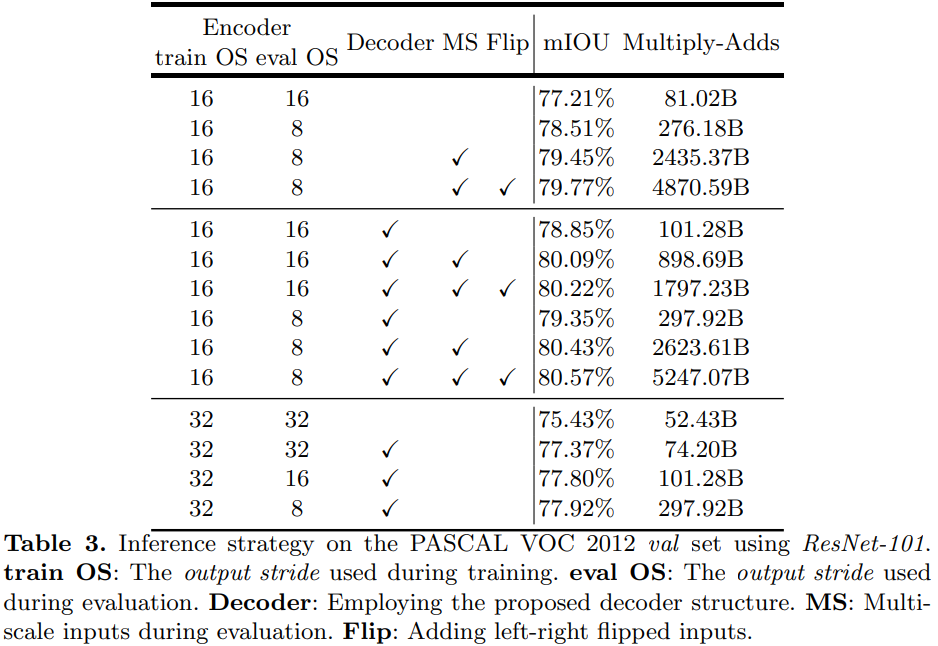
-
Decoder는 bilinear upsampling을 이용할 것인지, 여기서 말하는 decoder를 사용할 것인지를 의미
- 가장 높은 성능을 가지는 것은 training,과 eval의 output stride를 각각 16, 8로 설정하고, decoder와 multi-scale input을 사용하는 경우
- 이 때, Flip을 사용하면 성능이 80.43%에서 80.57%로 오르는데, 연산량이 2배로 증가하는 것을 확인
- 성능 향상 대비, 너무 많은 연산량 필요
Xception as Network Backbone
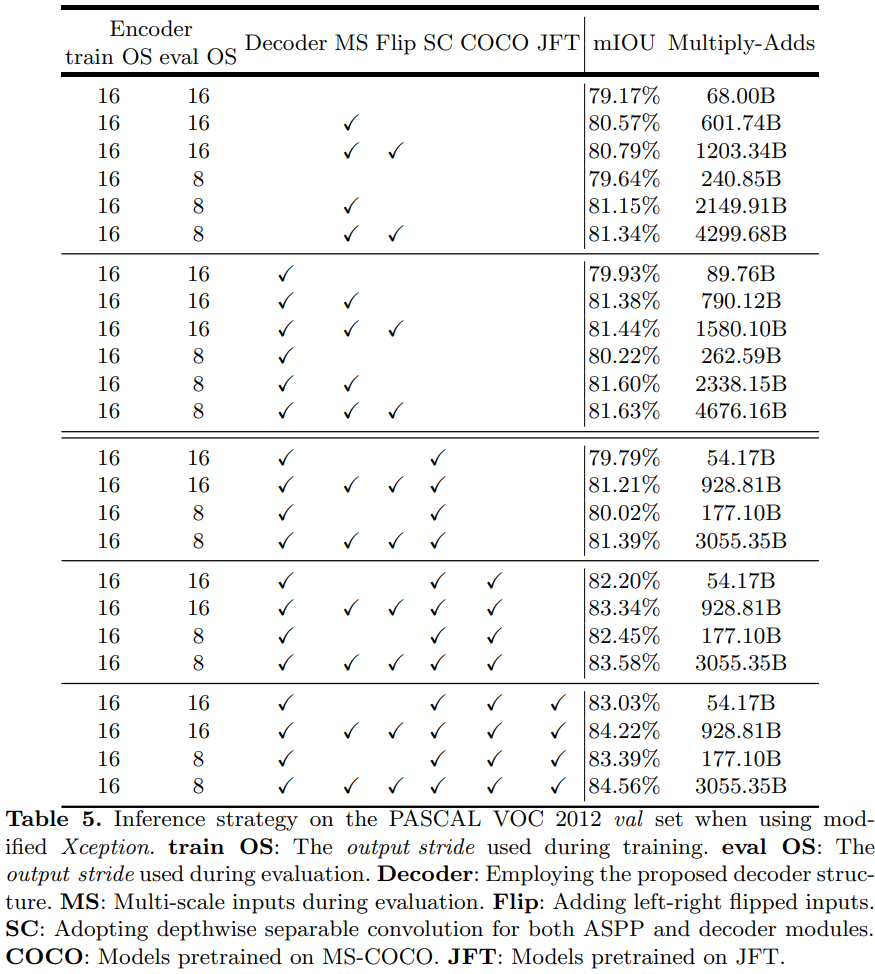
- Depthwise seperable convolution을 사용하는 경우 성능이 비슷한데 연산량이 많이 줄어드는 것을 확인
- COCO 로 모델 전체를 pretrain 하니 성능이 향상되는 것을 확인
- COCO, JFT로 모두 pretrain 하면 3% 정도의 성능 향상 확인
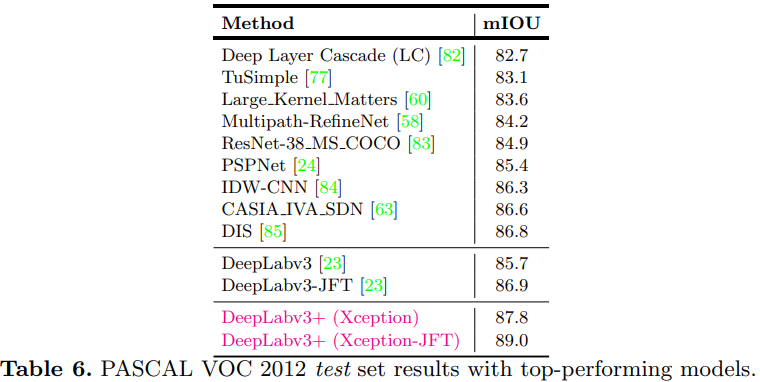
- 다른 Segmentation 모델들과 비교했을 때, DeepLabv3+의 성능이 가장좋은 것을 확인

Improvement along Object Boundaries

- 이 논문에서 제안한 decoder가 mIOU 성능도 좋고, object의 경계도 잘 찾아냄을 확인
Experimental Results on Cityscapes
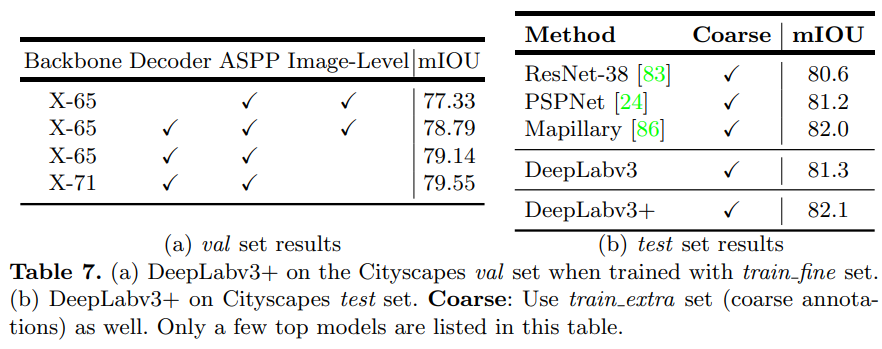
-
더 깊은 Xception 모델 사용할 수록 성능이 좋음
-
PASCAL VOC 2012와는 다르게 image-level feature (Low-level feature )를사용하지 않는 것이 성능이 더 좋음을 확인
Conclusion
DeepLabv3+는 풍부한 contextuaal 정보를 얻을 수 있는 DeepLabv3의 encoder를 사용하고 object의 경계를 잘 찾을 수 있는 간단하지만 효과적인 decoder 사용
Atrous convolution을 사용하여 계산 resource에 따라서 encoder feature의 해상도 조절 가능
Xception과 atrous convolution 을 이용하여 빠르고 강력한 네트워크 만듦
DeepLabv3+ 학습 결과
segmentation_models.pytorch 를 코드를 사용하여 학습 진행
학습 데이터는 kaggle에 있는 Massachusetts_Buildings_Dataset
Test dataset으로 학습 결과를 확인했을 때
Mean IoU Score: 0.7990 Mean Dice Loss: 0.1265
위와 같은 결과를 얻음
아래는 결과 예시이며, 차례대로 이미지, GT map, predicted map
건물의 모서리 부분이 둥글게 나오는 것을 확인