3D Human Pose Estimation 개요
참고
3D Human Pose Estimation
입력 이미지로부터 사람의 관절을 3D 공간에 위치화 시키는 알고리즘
2D와 3D의 차이
임의의 시점 (view) 으로 대상을 표현할 수 있는지가 근본적인 차이
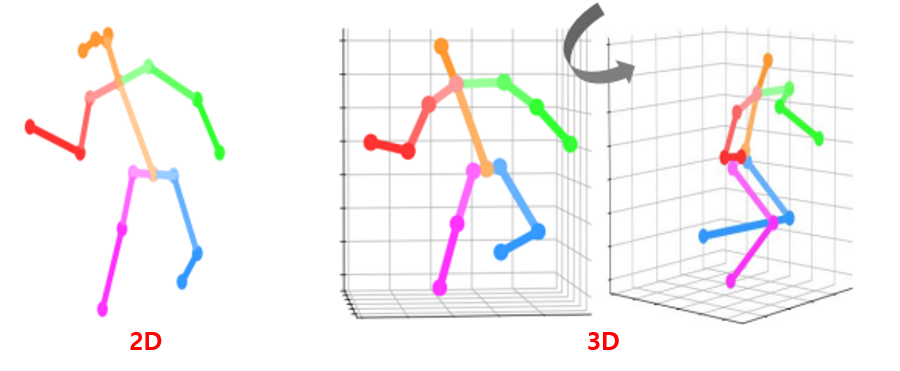
2D는 다른 view에서 pose를 볼 수 없음
3D는 다른 view의 pose를 보는 것이 가능 (시점의 변경이 가능)
즉, 시점을 변경하여 다른 view에서의 pose를 볼 수 있기 때문에 3D는 더 풍부한 정보를 가지고 있음
3D human pose
2D human pose estimation에서 pose 란 2D 관절 좌표를 의미하기때문에 따로 언급하지 않았지만 3D에서의 pose는 모호함
3D human pose estimation에서는 pose는 관절 좌표, 관절 회전 둘 다 사용
따라서 3D human pose estimation은 크게 3D 관절 좌표를 구하는 방법 관절 회전을 구하여 3D mesh를 구하는 방법 2가지로 나뉨
관절 좌표는 우리가 2D pose estimation에서 구한 것 처럼 3D 관절 좌표를 구하는 방법이고 3D mesh를 구하는 방법은 3D mesh의 좌표를 구하는 방법
3D human mesh
3D object를 표현하는 가장 standard한 자료 구조
다른 3D 데이터 표현법에 비해 효율적이고 직관적이기 때문에 가장 많이 사용

3D object를 많은 수의 작은 삼각형의 모음으로 3D 물체의 표면을 표현
내부와 외부는 비어있고 표면만을 나타냄
Vertex (꼭지점) 와 face (면) 으로 구성이 되는데 vertex는 삼각형의 각 꼭지점을 의미, face는 한 면을 어떤 삼각형 index가 이루는지 의미함
이 떼, 삼각형의 vertex의 개수와 index들을 mesh topology라고 하고 이는 미리 정해져있음
예를 들어, 몸을 구성하는 삼각형의 수는 1000개, vertex index 0, 1, 2 는 왼쪽 눈을 의미하고 vertex index 3, 4, 5는 오른쪽 눈을 구성
이 때, 3D 좌표를 구하는 것이 mesh를 구하는 3D human pose estimation의 목표
3D Body Model
여러 파라미터들을 입력으로 받아 3D mesh를 만드는 모델을 의미
일반적으로 2개의 orthogonal한 입력이 사용됨
- Pose 파라미터 $\theta$ (3D 괸절 회전)
- Shape 파라미터 $\beta$ (3D 체형)
하지만 다양한 입력이 존재할 수 있음
Pose parameter $\theta$
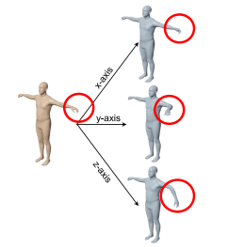
같은 shape 일 때 관절 위치 회전을 나타내는 파라미터
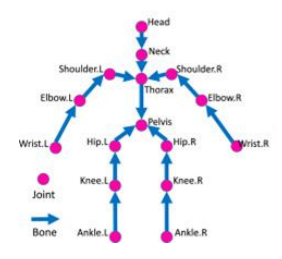
위의 그림처럼 human kinetic chain 존재하고, tree 구조를 가짐
- Pelvis는 root joint이고 hip, thorax는 pelvis의 child joint
관절의 회전은 각 관절마다 정의가 되는데 해당 관절의 부모 관절에 대한 상대적인 3D 회전
즉, 팔꿈치의 3D 회전은 부모 관절인 어깨의 상대적인 3D 회전
상대적인 회전이기 때문에 부모 관절의 회전과, 위치에 상관없이 독립적으로 pose 모델링 가능
회전으로 인해 모든 자식 관절들이 이동
어깨를 움직이면 어깨의 child node 들인 팔꿈치와 손목만 이동하고 어깨를 포함한 parent node들의 위치는 변하지 않음
따라서 leaf node에 해당하는 관절들은 child node가 없기 때 3D 회전이 정의되지 않음
- Leaf node는 마지막으로 존재하는 child node이고 이 그림에서는 wrist, ankle, head
Root node에 해당하는 관절의 회전은 global rotation(전신의 3D 회전)에 해당
회전을 구할 관절이 $\text{J}$ 개 이면 관절 회전에 대한 파라미터인 $\theta$는 $\text{J}\times 3$
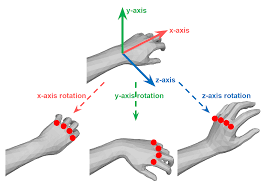
위의 손 그림을 예시로 하면, 손목을 parent node 손등의 뼈들을 child node 라고 하면
손목을 움직이면 손목 아래에 있는 손등의 뼈들은 움직이지만, 손목을 포함한 팔꿈치와 부모 관절은 움직이지 않음
Shape parameter $\beta$
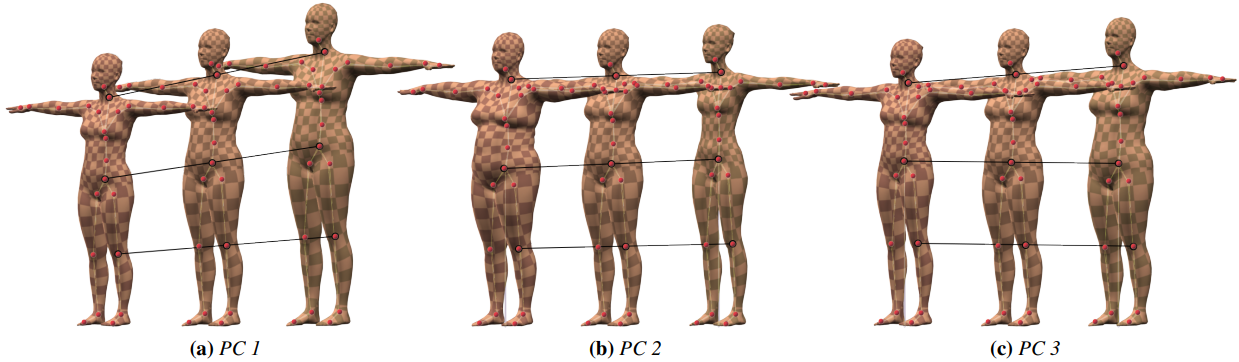
같은 T-pose(zero 3D 관절 회전)를 취한 사람의 길이와 체형에 대한 파라미터
일반적으로 PCA (Principal Component Analysis) 를 통해 사람의 체형과 길이에 대한 latent space를 찾고 PCA의 coefficient를 $\beta$로 사용
T-Pose를 취한 큰 규모의 3D scan dataset에 PCA 알고리즘 적용하여 Principal component 얻음
PC (Principal Component)들은 사람 체형을 구분하는 가장 주된 기준 제시
- PCA component에 \(\beta\) (weights)를 곱한 후 더해서 최종 t-posed 3D mesh를 획득
위의 그림을 예시로 하면 PC1, 2가 가장 큰 영향을 주는 것을 확인 할 수 있음
- PC 1
- 기준이 키인 component
- beta 값이 달라지면 키가 달라짐
- PC 2
- 기준이 체형인 component
- beta 값이 달라지면 체형이 달라짐
3D body model basic process
기본적인 3D body model의 과정은 아래의 그림과 같음
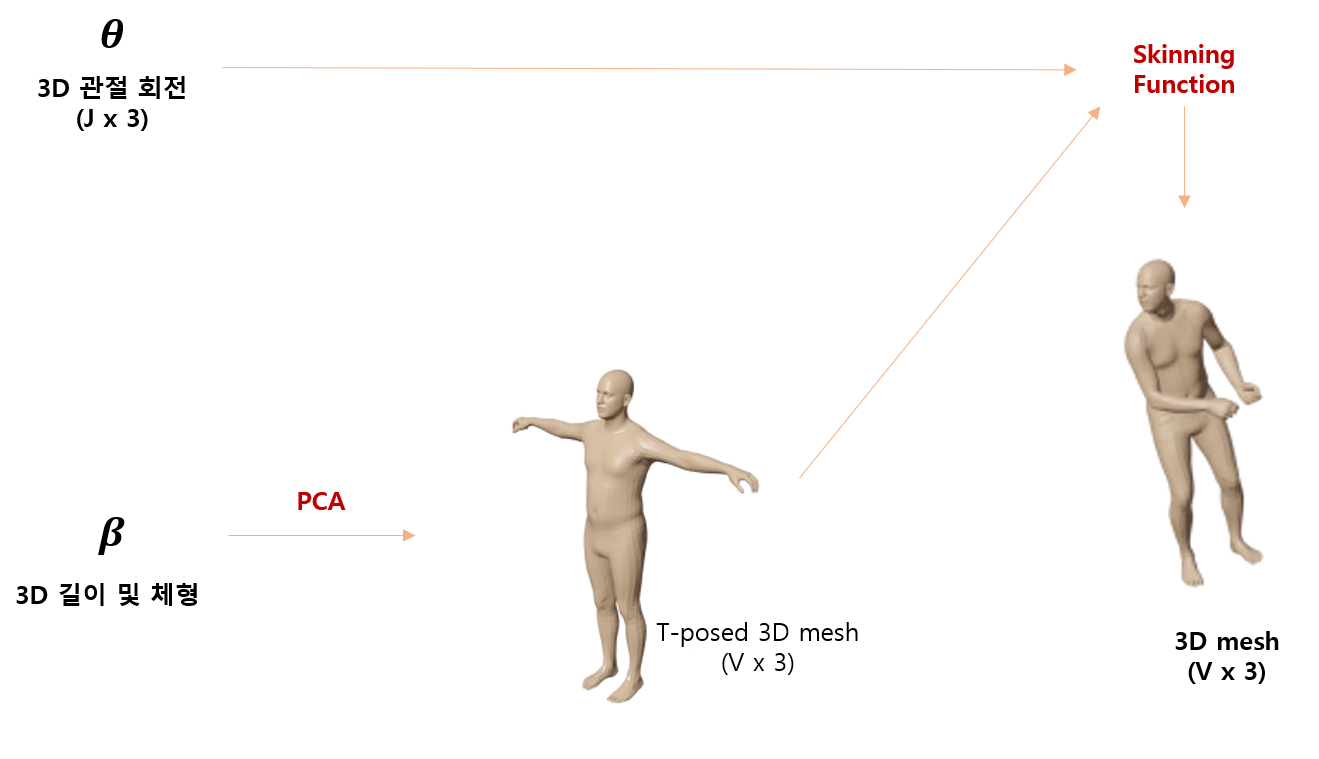
PCA를 통해 3D 사람의 길이 및 체형을 결정하고 T-posed 3D mesh 생성
이 때, $\text{V}$ 는 vertex의 개수이고 각 vertex는 $x, y, z$ 좌표를 가짐
T-posed 3D mesh와 pose 파라미터부터 skining function을 통해 pose를 취한 특정 체형의 3D mesh 획득
Skinning function
-
관절들의 위치로부터 피부를 입히는 역할
-
관절 좌표는 몇 개 존재하지 않기 때문에 모든 수의 vertex의 위치를 알아낼 수는 없기 때문에 Skinning function 이용
- 대표적인 알고리즘으로는 LBS (Linear Blend Skinning) 존재
- Skinning function을 이해하기 위해서는 Skinning weight를 알아야 함
Skinning Weight
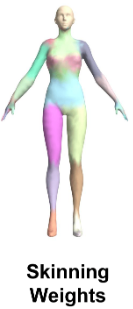
각 mesh vertex가 각 관절에 영향을 받는 정도를 의미
- 팔꿈치 근처에 있는 vertex들은 팔꿈치의 회전에 가장 큰 영향을 받음
각 3D human model 마다 미리 만들어 놓는 weight 존재하나 데이터에 맞춰 optimize 하는 경우도 있음
3D Human Pose Estimation 분류
Skeleton-only
입력 이미지로부터 3D 관절 좌표들을 최종 output으로 예측하는 방법
Direct estimation
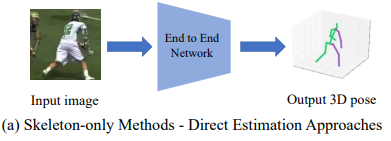
입력 이미지로부터 직접적으로 3D 관절 좌표를 구하는 방법
2D to 3D lifting
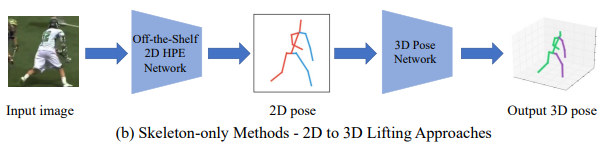
입력 이미지에서 2D human pose estimation 네트워크를 통해 2D 관절 좌표를 구하고 이 좌표를 이용하여 3D 관절 좌표를 추론하는 방법
성능이 좋은 2D human pose estimation의 이점을 이용하기 때문에 직접적으로 3D 좌표를 구하는 방법보다 성능이 좋음
Human Mesh Recovery
입력 이미지로부터 3D mesh 좌표들을 최종 output으로 예측하는 방법
Model-base
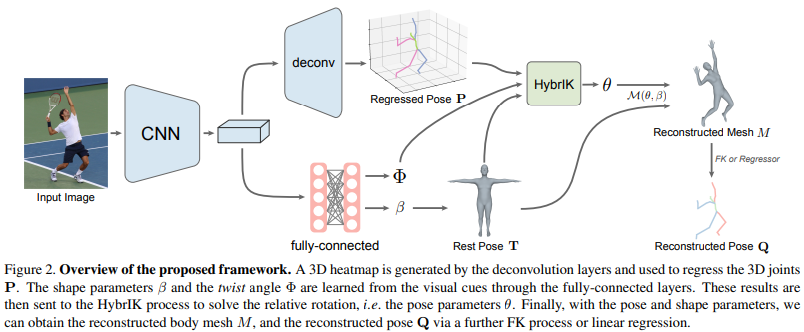
입력 이미지로 부터 3D body model 파라미터 ($\theta$, $\beta$, .. ) 를 추정하는 방식
찾은 파라미터들을 3D body model의 입력으로 넣어 3D human mesh 얻음
파라미터를 찾는 모델들을 학습하고, 3D body model은 고정되어 있고 학습하지 않음
Human kinematic chain을 따라 상대적인 회전이 이 누적되어 적용되기 때문에 부모 joint의 3D rotation이 잘못 예측되면, 자식 joint들에도 영향이 감
특히, 끝 단으로 갈 수록 error가 누적이 되는 현상 발생 (error accumulation)
이로 인해 model-free 방식보다 정확도가 낮을수 있음
하지만 3D body 파라미터를 얻으므로 여러 방면으로 활용 가능
학습할 때 skinning function을 이용하기 때문에 관절에만 loss를 주어도 관절로부터 떨어져있는 mesh vertex들도 loss에 영향을 받게 되므로 모든 vertex의 loss를 구할 필요 없이 관절 좌표만 이용하여 loss 계산
하지만 in-the-wild 이미지 데이터 셋과 MoCap 이미지 데이터 셋에 차이가 존재하기 때문에 학습 방법에 차이가 존재
In-the-wild 이미지 셋은 2D pose 정보만 존재하고 3D pose annotation은 존재하지 않음
따라서 예측한 3D mesh에 joint regression matrix (3D human model에 정의)를 곱해서 3D 관절 좌표 획득
3D 관절 좌표를 2D 이미지 공간으로 projection 시킴
이렇게 해서 얻은 2D 관절 좌표와 GT 관절 좌표의 loss 계산하여 학습
MoCap 이미지 데이터 셋은 3D pose에 대한 annotation이 존재하기 때문에 조금 더 간단하게 학습 가능
추정된 3D mesh에 joint regression matrix (3D human model에 정의)를 곱해서 3D 관절 좌표 획득
예측한 3D 관절 좌표와 GT 3D 관절 좌표의 loss를 계산하여 학습
Model-free
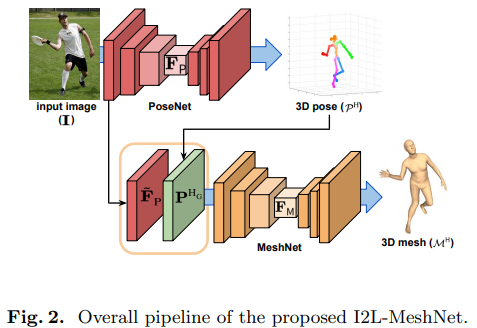
입력 이미지로부터 3D human mesh vertex들의 좌표들을 직접적으로 추정
추정한 3D human mesh는 3D human model의 topology와 같다고 가정
- 좌표만 추정하고 mesh의 topology는 3D human model과 같다는 의미
- 이로 인해 완전한 model-free는 아님
SMPL은 6980개의 vertex로 구성되어 있어 6980개의 vertex의 3D 좌표를 모두 추정해야 함
관절과 다르게 vertex는 개수가 매우 많기 때문에 computational overhead 발생
추정된 mesh vertex들이 3D human model에서 얻는 것처럼 자연스럽게 이어지지 않을 수 있음
또한, 3D human body parameter를 얻을 수 없기 때문에 다른 방법으로 활용할 수 없음
하지만 Error accumulation 현상이 없기 때문에 정확도는 model-base 보다 높을 수 있음
학습할 때, model-free 방법론들은 skinning function을 사용하기 때문에 관절 위치에 대한 loss를 계산하면 되지만 model-free는 모든 vertex에 대한 loss를 구해야 함
학습을 위해 GT 2D / 3D 관절 좌표로부터 3D pseudo GT mesh를 얻음
- In the wild 이미지 데이터는 2D 좌표가 GT, MoCap 데이터는 3D 좌표가 GT
네트워크를 통과하여 예측한 mesh 와 pseudo GT mesh 의 loss를 계산하여 학습