2D Human Pose Estimation 개요
참고
2D Human Pose Estimation
입력 이미지로부터, 여러 사람의 관절을 2D 공간에 위치화 시키는 모델
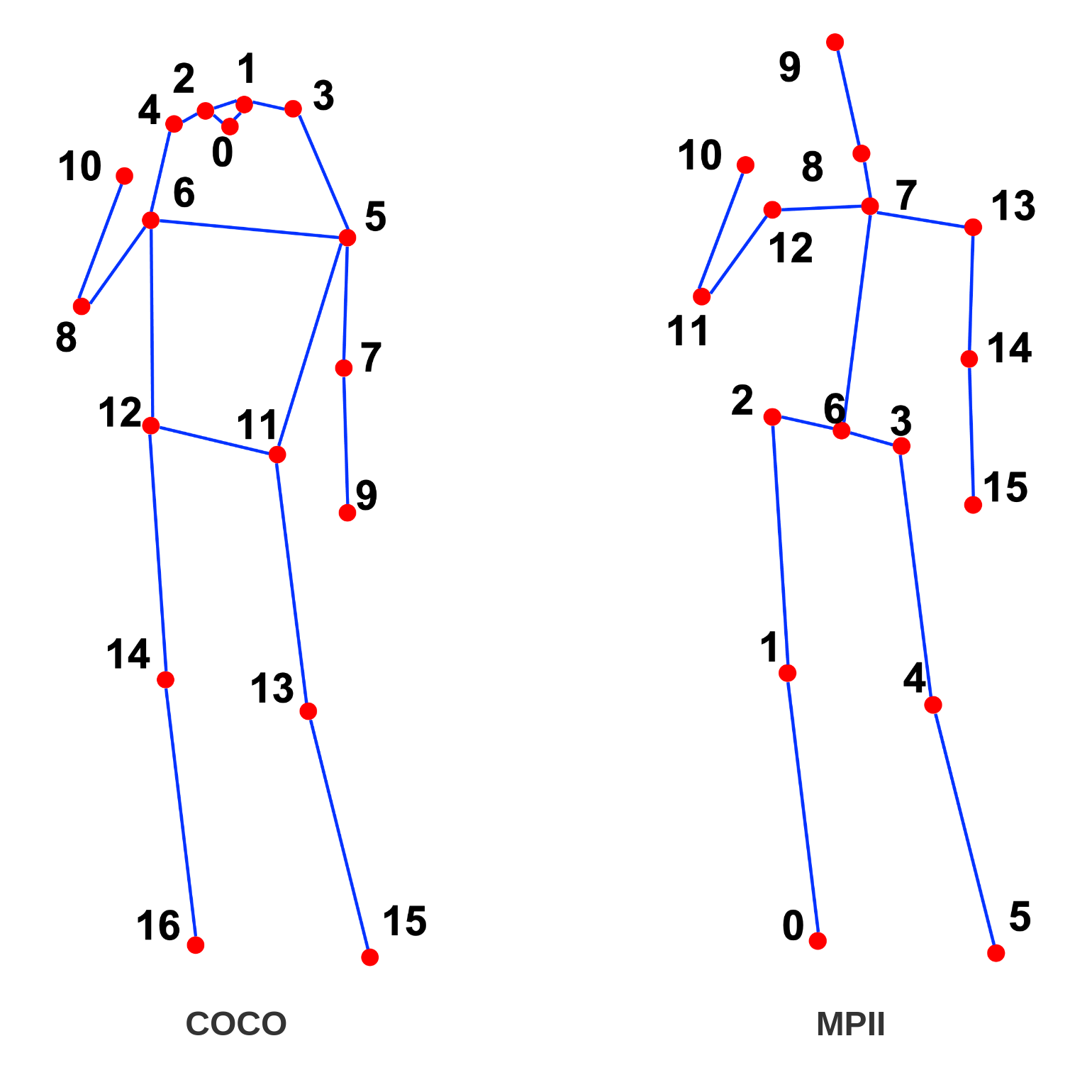
찾을 관절은 dataset 마다 정의가 되어 있음

입력 이미지 ($\text{H} \times \text{W}\times 2$)으로부터 관절 좌표를 추정
출력은 보통 $\text{N} \times \text{J}\times 2$로 구성
- $\text{N} $ : Detection 한 사람
- $ \text{J}$ : 정의 된 관절의 개수
가장 대표적인 MSCOCO dataset은 17개의 관절을 정의($ \text{J}=17$)
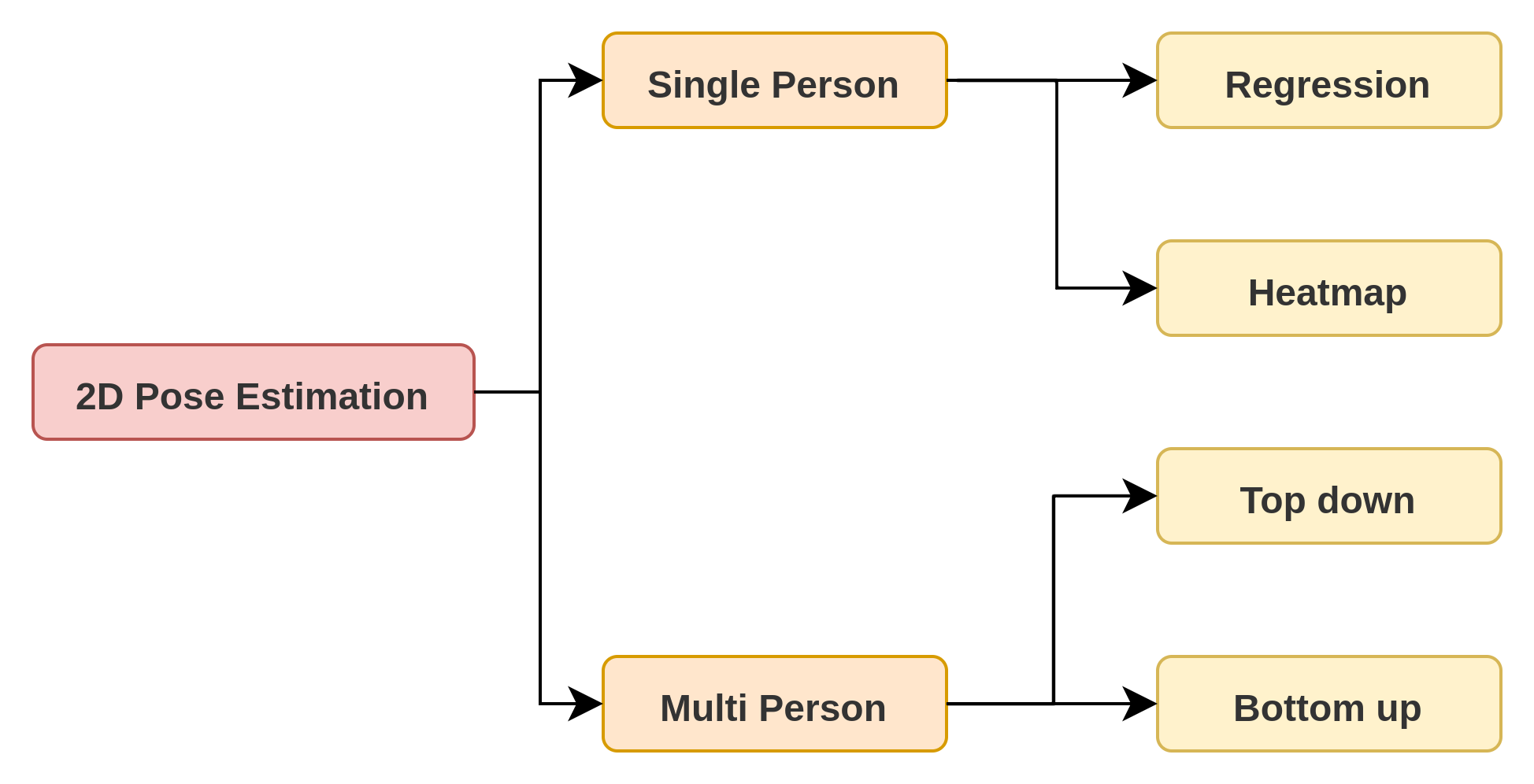
2D Human Pose Estimation 분류
Single Person
이미지 내의 한 사람이 존재할 때 몸의 관절을 localization 하는 과정
Regression based
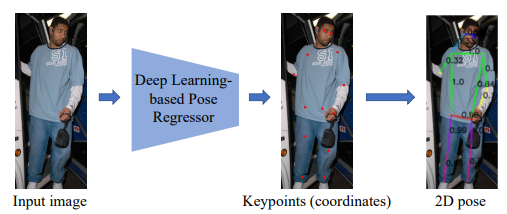
네트워크 모델을 통해 관절 좌표의 위치를 regression 하여 직접적으로 구하는 방법
이 방식은 가장 간단하고, 빠른 속도를 가지지만 최근에는 많이 사용하지 않음
Heatmap based
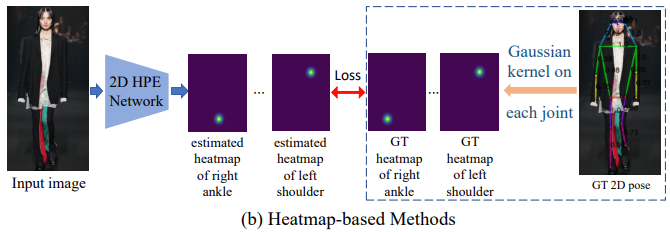
입력 이미지가 딥러닝 네트워크를 통과하여 출력으로 2D heatmap ($\text{J} \times \text{H}\times \text{W}$)
- $\text{J}$ : Dataset에 정의된 관절 개수
- $\text{H}$ : Heatmap 높이
- $\text{W}$ : Heatmap 너비
즉, 좌표를 직접적으로 구하는 것이 아닌 관절이 존재할만한 위치를 확률을 구함
Ground truth에도 gaussian kernel을 적용하여 2D heat map 생성하고 네트워크를 통해 예측한 heatmap과의 loss를 계산하여 학습
참고로, 보통 학습할 때, 입력 이미지에 정의가 되어있지 않는 관절의 경우 (Occlusion 등) loss를 0으로 두고 학습을 진행
직접적으로 좌표를 추정하지 않고 2D heatmap을 추정하는 이유는 크게 2가지
- 높은 성능
- 2D 좌표의 비선형적 연산 요구
이미지는 높이와 너비의 개념이 존재하고 pose estimation의 네트워크 또한 convolution을 이용하기 때문에 이미지의 높이와 너비를 보존 할 수 있음
하지만 좌표 이미지를 구하기 위해서는 보통 GAP (Global Average Pooling)을 사용하여 벡터화 시킨 후 좌표를 추정하기 때문에, 입력 이미지의 높이, 너비 개념이 사라지고 비선형적인 연산을 요구하여 낮은 성능이 나온다는 것이 실험적으로 알려짐
2D heatmap은 이와 다르게 convolution 연산만으로도 좌표값을 추정할 수 있기 때문에 성능이 더 좋음
물론, 2D 좌표를 직접적으로 regression 경우 computational cost가 적게 들지만, 정확도 차이가 많이 남
Multi Person
이미지 내에 여러 사람이 존재하는 할 때 모든 사람의 관절을 localization 하는 방법
Top-Down
Human detection + Single person pose estimation
이미지에서 사람을 먼저 찾고, 찾은 각 사람의 영역 안에서 관절을 찾는 방법

최근에 발표된 yolo 등의 매우 정확하고 빠른 human detection 방법 존재하기 때문에 bottleneck은 single person pose estimation에서 발생
Human detection이 실패하면 아예 single person pose estimation이 불가능하다는 단점이 존재하나 detector의 성능이 좋아져 어느정도 해결
Human detection 한 후 resize 하기 때문에 해상도가 낮아 손목, 발목 등이 잘 안보이는 경우에도 좌표를 잘 찾을 수 있음
일반적으로 Bottom-up 방식보다 더 좋은 성능 가짐
대표적인 방식은 아래와 같은 방법들
- Mask R-CNN (ICCV 2017)
- Simple Baseline (ECCV 2018)
- HRNet (CVPR 2019)
Bottom-Up
Joint detection + Grouping
이미지에서 존재하는 관절을 먼저 찾고, 그 관절들을 각 사람으로 그룹화 해주는 방법

일반적으로 Top-Down 방식보다는 낮은 성능을 보임
Top down 방식처럼 resize하지 않기 때문에 Human pose estimation에 쓰이는 사람 입력 이미지가 저해상도일 가능성 존재
여러 scale의 사람 이미지를 다뤄야하기 때문에 네트워크에 부담이 될 수 있음
대표적인 방식은 아래와 같은 방법들
- Associative Embdeeing
- HigherHRNet
평가 지표
PCP (Percentage of Correct Parts)
Limb (팔, 다리) 의 위치 정확도를 측정하기 위한 방법
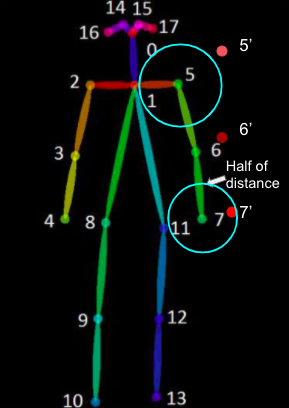
그림과 같이 ground truth에서 7번 keypoint 기준 6번과의 거리의 절반을 반경으로 잡고 해당 반경 내에 예측값이 들어오면 올바르게 예측 (이런 경우 PCP@0.5)
\[\text{PCP}=\frac{\text{correct 관절 }}{\text{전체 데이트 세트 총 관절}}\]PCPm
PCP 방법 사용하면 사람이 작게 나오는 경우 원이 작아져 올바르다게 판정하기 힘듦
원의 반경을 테스트 데이터 전체의 평균치로 변경하여 사용
PCK (Percentage of Correct Keypoints)
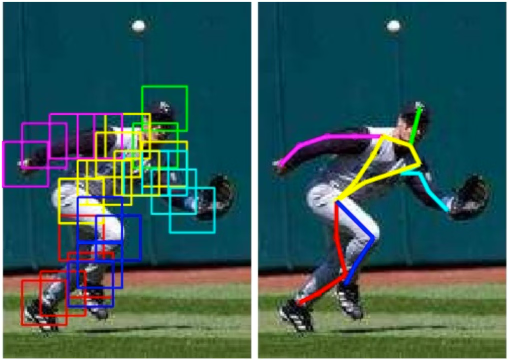
Ground truth의 관절 좌표 값과 네트워크로 예측한 관절의 좌표가 threshold 값 보다 작으면 그 관절을 올바르게 예측했다고 판단
보통 torso 지름을 기준으로 함
예를 들어 PCK@0.2 = 0.2 * torso diameter
PCKh
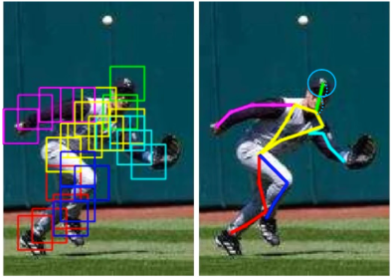
몸통이 아닌 머리를 기준으로 threshold 값을 설정
많이 사용하는 평가 지표
PDJ (Percentage of Detected Joints)
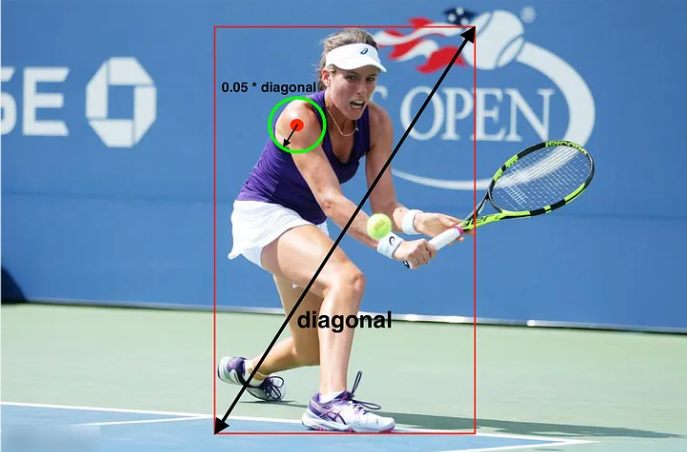
Ground truth의 관절 좌표 값과 네트워크로 예측한 관절의 좌표가 threshold 값 보다 작으면 그 관절을 올바르게 예측했다고 판단
모든 관절은 같은 threshold 값을 가짐
이론적으로는 torso, 즉 몸통의 지름을 기준으로 threshold 값을 정해야하지만, 2D 이미지에서 사람이 옆으로 돌 때, 몸의 지름이 0이 될 수 있음
- 양 어깨의 두 관절의 수평 거리가 0에 가까워 질 수 있음 (양 쪽 골반도 마찬가지)
이를 위한 해결책으로 bounding box의 대각을 기준으로 사용
OKS (Object Keypoint Similarity)
주로 COCO dataset을 평가할 때 사용하고 아래의 식과 같음
- $d_{i}$ : $i$ 번째 keypoint의 예측값과 ground truth 값 사이의 거리
- $s$ : 사람의 크기
- $k_{i}$ : 각 keypoint (관절) 마다 가지는 상수값
- $v_{i}$ : Grount truth의 visibility flag
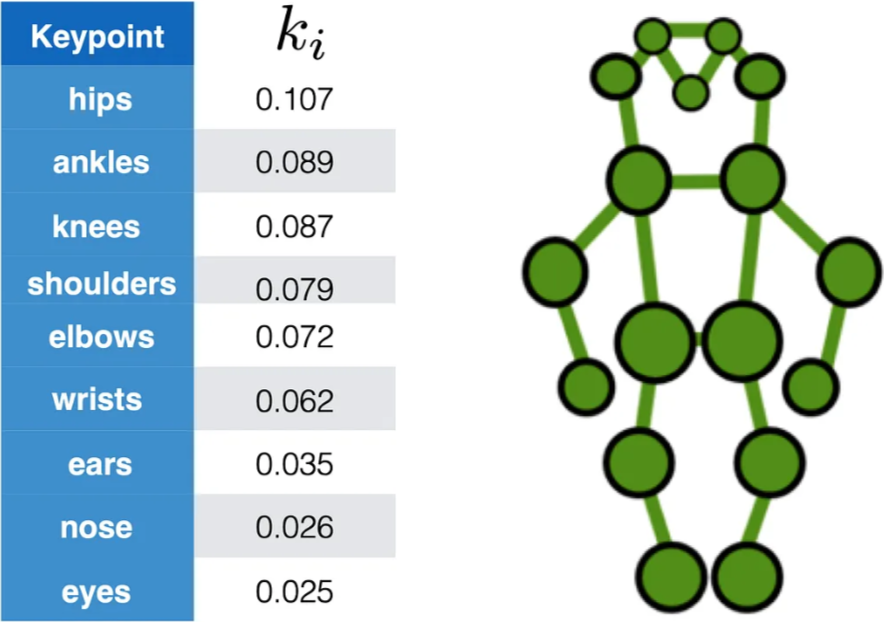
예측한 keypoint와 ground truth keypoint와의 거리를 사람의 크기로 정규화한 값
이 때, 각 관절에 다른 계수 $k_{i}$ 가 적용됨
0과 1 사이의 값으로 예측값이 정답과 얼마나 가까운지 알려줌
AP
OKS 값을 이용하여 AP를 계산함
Threshold 값과 OKS 값을 비교하여, 값이 크면 keypoint가 detect 되었다고 판단
보통 논문에서 threshold 값을 0.5 또는 0.75를 사용