DeepSort
참고
SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC
2017
Abstact
Simple Online and Realtime Tracking (SORT)는 간단하고, 효과과적인 알고리즘에 중점을 둔 실용적인 Multiple Object Tracking(MOT) 방법
이 논문에서는 SORT의 성능이 높이기 위해 appearance 정보를 함께 활용
이로 인해 오래 occlusion 된 object들을 ID switching이 효과적으로 줄이면서 tracking 할 수 있음
대규모의 person re-ID 데이터를 이용하여 deep association metric를 학습하는 off-line pre-training 단계에 더 많은 계산 복잡도가 존재
Online 단계에서는, appearance 공간에서 neariest neighbor query를 사용하여 measurement-to-track associations을 설정
실험 결과에서 ID switching의 수가 45% 정도 감소시켜 빠른 속도로 좋은 성능을 보임
Introduction
MOT에는 크게 2가지 방식이 존재하는데 detection-free-tracking과 tracking-dy-detection
Tracking-by-detection에서는 frame 간 동일한 object에 대한 association 하여 전체 궤도를 생성
Tracking-by-detection은 association 방식에 따라 batch tracking 과 online tracking 으로 나뉨
- Batch tracking : 전체 tracking 궤도 만들기 위해 전체 frame의 detection 결과에서 association 수행, 성능이 좋지만 실시간으로 사용할 수 없음
- Online tracking : 현재 frame과 과거의 frame을 사용하여 association을 수행하여 trakcing 하는 방법
즉, Tracking-by-detection 에서는 객체의 일반적으로 전체 비디오 batch를 한 번에 처리하는 global optimization 문제 존재
Batch processing 으로 인해, 각 time-step에서 target ID를 사용할 수 있어야하는 온라인 시나리오 에서는 적용되지 않음
SORT는 image space에서 Kalman filter를 사용하고 Hungarian 방법과 bounding box의 overlap을 측정하여 association metric을 계산하여 프레임 간 data-association 정보를 얻음
위의 방법은 높은 frame-rate에서 좋은 성능 획득
SOTA가 tracking의 precision, accuracy 관점에서 전체적으로 좋은 성능을 가지지만, ID switching 현상이 자주 발생한다는 문제가 존재하는데 이는 SOTA에서 사용하는 association metric는 state estimation uncertainty가 낮을 때만 정확하기 때문
그래서 카메라에서 occlusion이 발생하는 동안 tracking 성능이 좋지 않음
- Occlusion이 발생하면, 가려져서 보이지 않기 때문에 state estimation uncetainty가 높아짐
이러한 SOTA 단점을 해결하기 위해 기존의 association metric 대신, motion 정보와 appearance 정보를 같이 사용하는 metric을 사용
특히, 대규모의 Re-ID 데이터 셋에서 pedestrain을 잘 구별하도록 학습한 CNN을 활용하여 occlusion과 miss에 대한 강건함을 높임
SORT WITH DEEP ASSOCIATION METRIC
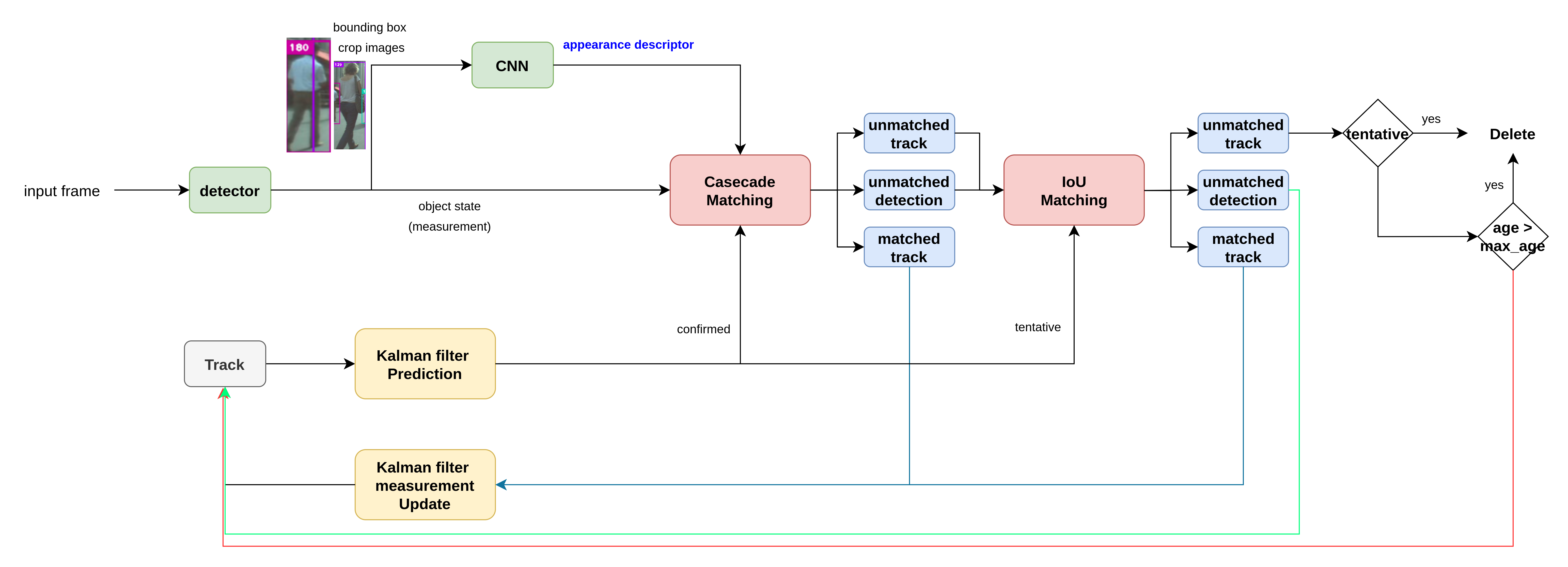
위의 그림이 전체적인 Deepsort의 flow
Track Handling and State Estimation
카메라가 보정되지 않은 경우나, 이용할 수 있는 ego-motion 정보가 없는 일반적인 tracking 시나리오를 가정
- ego-motion은 카메라의 이동을 이미지를 사용하여 추정하는 것
이런 상황은 filtering framework에 어려움이 있지만, 최근 MOT benchmark에서 가장 많이 고려되는 일반적인 설정
Tracking 시나리오는 아래의 8차원의 state space를 가짐
\[(u,v,\gamma,h,\dot{x}, \dot{y},\dot{\gamma},\dot{h})\]- Bounding box center position : $(u,v)$
- Aspect ratio : $\gamma$
- height : $h$
- velocity : $(\dot{x}, \dot{y},\dot{\gamma},\dot{h})$
등속 운동과 선형 관측 모델을 가지는 일반적인 Kalman Filter를 사용
이 때, bounding box 좌표 $(u,v,\gamma,h)$는 object state를 직접 관측하여 얻음
각 track인 $k$가 detector 결과로 나온 bounding box와 마지막으로 association $a_{k}$ 된 이후의 frame의 수를 계산
- track은 우리가 추적하고 있는 object들이라고 생각
이 수는 Kalman filter 예측 동안 증가가 되고, track이 measurement, 즉 boudning box와 association 발생하면 0으로 리셋
사전에 미리 정의한 최대 age $A_{age}$를 초과한 track은 scene을 떠났다고 간주하여 track set에서 삭제
- 즉, track이 최대 정의한 frame 수보다 더 오랫동안 detector가 찾은 bounding box와 association이 발생하지 않으면 이미 화면에서 사라졌다고 생각
현재 존재하는 track들과 association되지 않은 bounding box는 새로운 track이 될 가능성이 있기 때문에 track에 추가
이 때, 새로운 track은 처음 등장하고 나서 3개의 프레임까지는 잠정적 (tentative)인 상태로 분류하고 이 동안 3개의 프레임동안 연속적으로 bounding box와 association이 되지 않으면 track에서 삭제
Assignment Problem
Kalman Filter로 예측한 state와 detector로 검출한 새로운 measurement 사이의 association을 해결하는 가장 기본적인 방법은 Hungarian algorithm을 적용하는 것
해당 공식 안에서, 우리는 적절한 두 가지의 metric를 결합하여 motion과 appearance 정보를 통합
Motion 정보를 통합하기 위해서 Kalman filter로 예측한 state와 새로 얻은 measurement 사이의 Mahalanobis 거리를 측정
- Mahalanobis 거리는 평균과의 거라기 표준 편차의 몇 배인지를 나타냄
이 때, 예측한 motion 값을
\[d^{(1)}(i, j)=(\textbf{d}_{j}-\textbf{y}_{i})^{T}\textbf{S}_{i}^{-1}(\textbf{d}_{j}-\textbf{y}_{i})\]-
\(\textbf{d}_{j}\) : $j$ 번째 bounding box 값
- \(\textbf{y}_{i}\) : $i$ 번째 track 분포에서의 평균 값, Kalman filter로 예측한 값
- \(\textbf{S}_{i}\) : $i$ 번째 track 분포에서의 공분산 행렬
Mahalanobis 거리는 state estimation uncertatinty를 detection이 평균 위치으로부터 표준편차의 몇배 만큼이나 떨어져 있는가로 표현
이를 이용하면 역 $ \chi $ 분포에서 계산된 Mahalanobis 거리의 신뢰도 95% 구간을 threshold 값으로하여, association이 아닌 것 같은 것을 배제 할 수 있음
\[b_{i,j}^{(1)}=\mathbb{1}[d^{(1)}(i,j)\le t^{(1)}]\]$i$ 번째 track와 $j$ 번째 detection의 association 인정되면 1로 평가
우리의 4차원 measurement space에서는, Mahalanobis threshold 값 $ t^{(1)}$은 9.4877
즉, Mahalanobis거리가 특정 거리보다 멀어지면 사용하지 않음
Motion uncertainty가 낮을 때, Mahalanobis 거리는 적절한 association metric
하지만 Image space problem formulation에서는Kalman filter 에서 얻어진 예측된 state 분포는 매우 대략적인 object 위치의 추정값을 제공
특히, 설명되지 않은 카메라의 움직임은 image plane에서 급격한 이동이 생기기 떄문에, Mahalanobis 거리는 occlusion 이 존재할 때는 tracking 하기에는 적절하지 않음
이를 위해 두 번째 metrix를 assignment 에 통합하여 이용
각 bounding box \(\mathbf{d}_{j}\)에 대하여, 크기가 1인 appearance descriptor \(\mathbf{r}_{j}\) 계산
- 즉, CNN 네트워크를 통과시켜 appearance descriptor 얻는 과정
각 track $k$에 대한 마지막 100개 ($L_{k}=100$)의 연관된 appearance descriptor를 gallary $R_{k}$에 보관
\[R_{k}= \{r_{k}^{(i)}\}^{L_{k}}_{k=1}\]그 후, $i$ 번째 track과 $j$ 번째 detection 사이의 가장 작은 cosine 거리를 측정
\[d^{(2)}(i,j)=min\{ 1-r_{j}^{T}r_{k}^{(i)} | r_{k}^{(i)}\in R_{i} \}\]그 후, 앞에서와 같이 association이 인정되는 것을 확인하는 이진 변수 사용
- 즉 , cosine 거리가 특정 값보다 작거나 같은 경우 일 때의 detection에만 indicator 값으로 1을 할당
적절한 threshold $t^{(2)}$ 값을 학습 데이터셋에서 찾음
Assignment 관점에서 두 matrix는 몇 가지 점에서 서로의 문제를 보완
Mahalanobix 거리는 motion을 기반으로 가능한 object위치에 대한 정보를 제공하며, short-term 예측에 적절함
Cosine 거리는 오랜 occlusion 이 발생하여, motion을 이용한 방법이 변별력이 없을 때, appearance 정보를 활용하여 ID를 회복할 수 있도록 함
- 즉, ID switching을 방지
가중합 방식을 이용하여 두 metric을 합친 값을 association problem의 loss로 사용
\[c_{i,j}=\lambda d^{(1)}(i,j)+(1-\lambda)d^{(2)}(i,j)\]이 때, 두 metric 모두 gating 영역 안에 있으면 association을 인정
- 즉 mahalanobis, cosine 거리 둘 다 정해진 각 threshold 값보다 작거나 같은 boundinb box의 경우에만 association 인정
카메라 움직임이 많은 경우 $\lambda=0$ 으로 설정하는 것이 합리적
즉, appearance 정보만 사용하고, Mahalanobis 거리는 Kalman filter에 의해서 예측한 물체의 위치에 기반해서 assignment 제거하는데 사용
Matching Cascade
앞에서 구한 거리 metric을 통해서 연관성을 정량화했다고 생각하면 좋음
이제, 정량화 한 값을 바탕으로 데이터를 연결해주는 과정이 필요하고 아래는 이에 대한 설명
Object의 occlusion이 긴 시간동안 지속이 되는 상황에서는, 뒤이어 Kalman filter가 예측한 위치값의 불확실성은 증가함.
결과적으로, 확률 질량은 state space에서 퍼지는 모양을 가지게 되고, 관측 가능성이 덜 뾰족해짐
- 확실하게 한 위치를 정답이라고 할 수 없다는 의미이기 때문에 분산이 커지게 되고, 이는 퍼지게 되는 것과 같음
직관적으로, associtation matrix는 measurement와 track의 거리를 증가시켜 확률 질량이 퍼진 것을 설명해야 함
기존의 Kalman filter prediction만을 이용한 mahalanobis 방법은 두 개의 track이 동일한 detection에 대해서 경쟁을 할 때, 불확실성이 더 큰 track이 선택됨
-
Detection이 해당 track의 평균에 대한 표준편차 거리를 효과적으로 감소시켜주기 때문
-
불확실성이 크다는 것은 분산이 크다는 것을 의미
이는 track fragmentation이 일어나 tracking이 불안정해짐
- Track fragmentation이란, tracking 하던 하나의 object가 occlusion이나, ,misdetection 등의 현상으로 여러 개의 track으로 나뉘어지는 현상을 의미
따라서, 이전 프레임에서 자주 관측되었던 object에 더 높은 우선 순위를 부여하여 association 가능성에서 확률 확산의 개념을 인코딩
- 즉, association을 결정할 때, 확률 분포의 개념을 활용하는데, 이전에 자주 관측되었던 object과 associtaion 될 확률이 높다는 의미..
아래와 같은 과정을 거쳐 matching이 됨

-
Detection과 track 사이의 cost matrix 계산
- 위에서 설명한 mahalanobis, cosine 거리를 계산하고, 가중합하여 계산
- Detection과 track 사이에서 metric 를 기반으로 threshold를 적용하기 위한 mask 계산
- Detection과 track의 matching set을 $M$을 공집합으로 초기화
- Match되지 않은 detection set $U$를 $D$으로으로 초기화
- 1부터 age까지의 값이 할당된 변수 n으로 for문 수행
- $n=1$ 부터 실행한다는 의미는 바로 이전 frame 부터 살펴본다는 의미
- 마지막 $n$ 프레임에서 detection과 association 되지 않은 $age=n$ 인 track들을 부분 집합으로 $T_{n}$으로 설정
- Track_{n}과 매칭되지 않은 detection $U$ 사이의 min-cost-matching 실행하여 matching 결과 반환
- 여기서 hungarian 알고리즘이 사용
- Mask의 threshold 적용 후, matching 된 detection 값은 matching되었다고 생각하고 $M$에 추가하고
- $U$에서 제거
- age_max까지 반복
- 반환
이런 방법은 최근데 발견된 track들에 대해 우선순위를 부여하여 matching을 진행
Matched track 은 계속 추적 중인 object이고, Kalman filter를 업데이트 (파란선)
Unmatched detection은 새롭게 등장한 object이고, 새로운 track으로 추가하여 tentative 상태로 설정 (초록색 선)
Unmatched track 은 추적하던 object를 발견 못했을 때이고, 바로 삭제되는 것이 아니라 occlusion등의 상황에 의해 matching을 못했을 수도 있기 때문에 일정 기간 동안 확인 (빨간선)
Deep Appearance Descriptor
추가적인 metric learning 없이, 간단한 nearest neighbor query를 사용하여 논문에서 제시한 방법을 성공적으로 적용하기 위해서, 실제 online tracking에 적용하기 전에 offline 상에서 특징을 잘 구별할 수 있는 feature embedding이 잘 학습되어야 함
이를 위해 ReID dataset MARS을 사용하여 아래와 같은 구조의 CNN 모델 학습
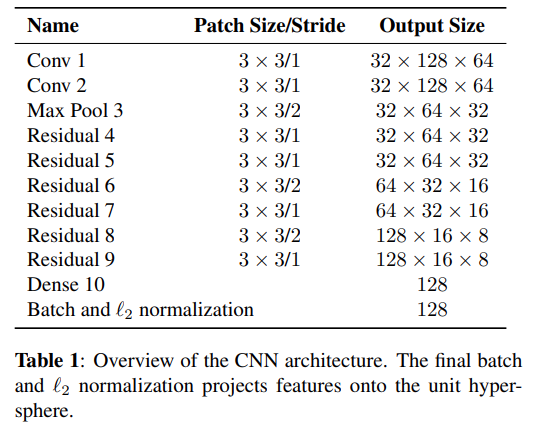
output으로 생성된 1차원의 128 vector가 appearance descriptor가 되고 이를 이용하여 cosine 거리를 계산함
EXPERIMENTS
MOT16 benchmark로 우리의 tracker인 deepsort의 성능을 평가
이 실험의 detector로는 faster R-CNN을 사용하고, 공정한 비교를 위해 동일한 detector롤 사용
평가를 진행할 때, $\lambda$의 값
은 0으로 설정하였고, $A_{max}$ 는 30 설정
Detection에서 confidence threshold는 0.3
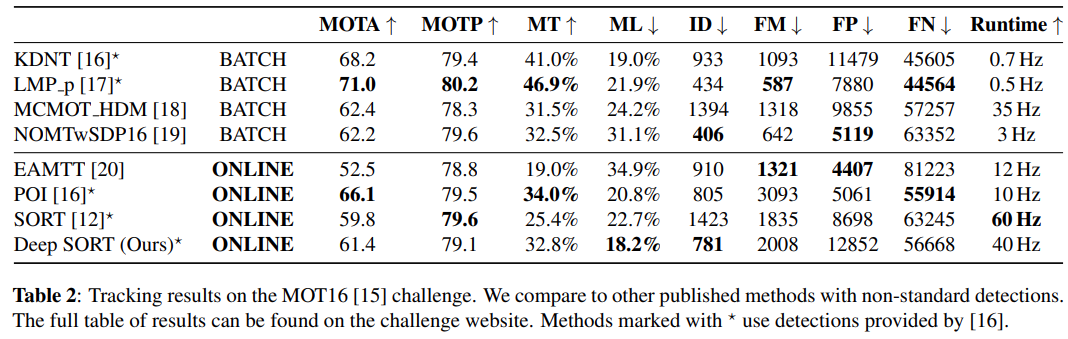
- Multi-object tracking accuracy (MOTA) : FP, FN, ID switching 관점에서의 전체적인 tracking 정확도
- Multi-object tracking precision (MOTP): Bounding box와 기록된 location 사이의의 overlap측면에서의 전박적인 tracking 정밀도
- Mostly tracked (MT): 생명 주기의 최소 80% 동안 동일한 label 가진 GT track의 비율
- Mostly Lost (ML) : 생명 주기의 최대 20%만 추적된 ground-truth track의 비율
- Identity Switches (ID) : ground-truth track의 기록된 identity switch 횟수
- Fragmentation (FM): missing detection에 의해 track이 방해를 받은 횟수
DeepSORT ID switch 수를 감소시켰고, 기존의 SORT와 비교해보면 1423에서 781로 대략 45% 감소함을 확인
MT와 ML 성능도 SORT에 비해 좋아지는 것을 확인
다른 online tracking 방식들과 비교를 해보아도 경쟁력있는 결과를 얻은 것을 확인
특히나, 좋은 MOTA, track fragmentation, FN 성능을 유지하면서도 ID switching 현상이 현저하게 적은 것을 확인 할수 있음
Conclusion
미리 학습한 association metric으로 얻은 appearance를 정보를 함께 활용하는 확장된 SORT 알고리즘 제시
이 확장로 인해, occlusion에서도 성능이 좋은 tracking 성능을 획득
또한 알고리즘은 SORT와 마찬가지로 구현이 쉽고 실시간으로 동작이 가능함