YOLOv8
참고
논문의 세세한 내용보다는 네트워크 구조 등을 정리해야지..
YOLOv8
YOLO의 흐름
- YOLO
- 24 CNN, 2FC, leakyReLU
- YOLOv2
- Darknet-19, Batch Normalization 적용, Anchor box 사용, Multi-scale training
- YOLOv3
- Efficient backbone, SPP (Spatial Pyramid Pooling)
- YOLOv4
- Mosaic data augmentation, anchor-free detection
- YOLOv5
- 수정된 CSPDarknet53 backbone 사용, SPPF 사용, 다양한 data augmentation 사용
- YOLOv6
- RepVGG backbone 사용, self-distillation, VariFocal, SIoU, GIoU 사용
- YOLOv7
- pre-trained 된 backbone 사용 안함, Pose estimation과 같은 추가적인 task 실행
YOLOv8 architecture
Yolov8의 전체적인 대략적인 구조
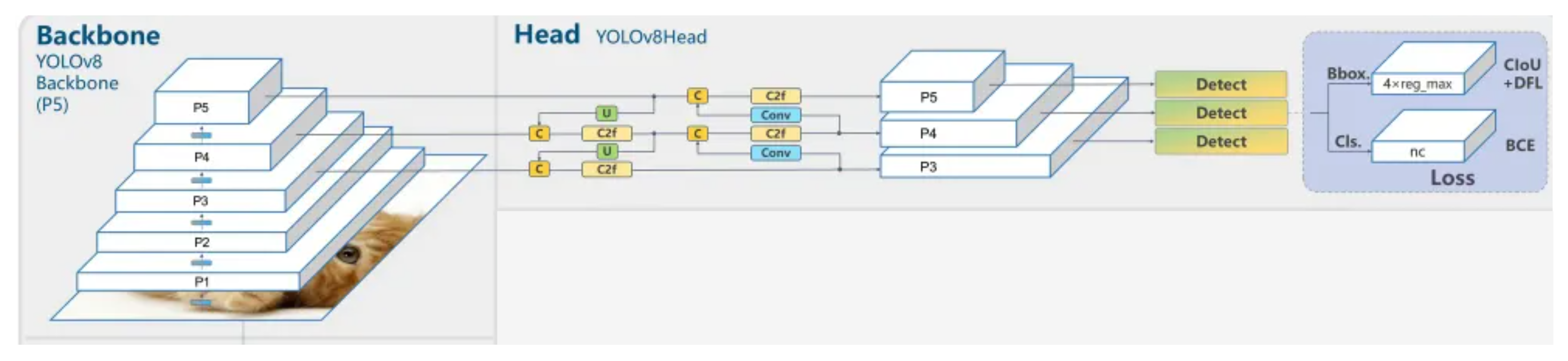
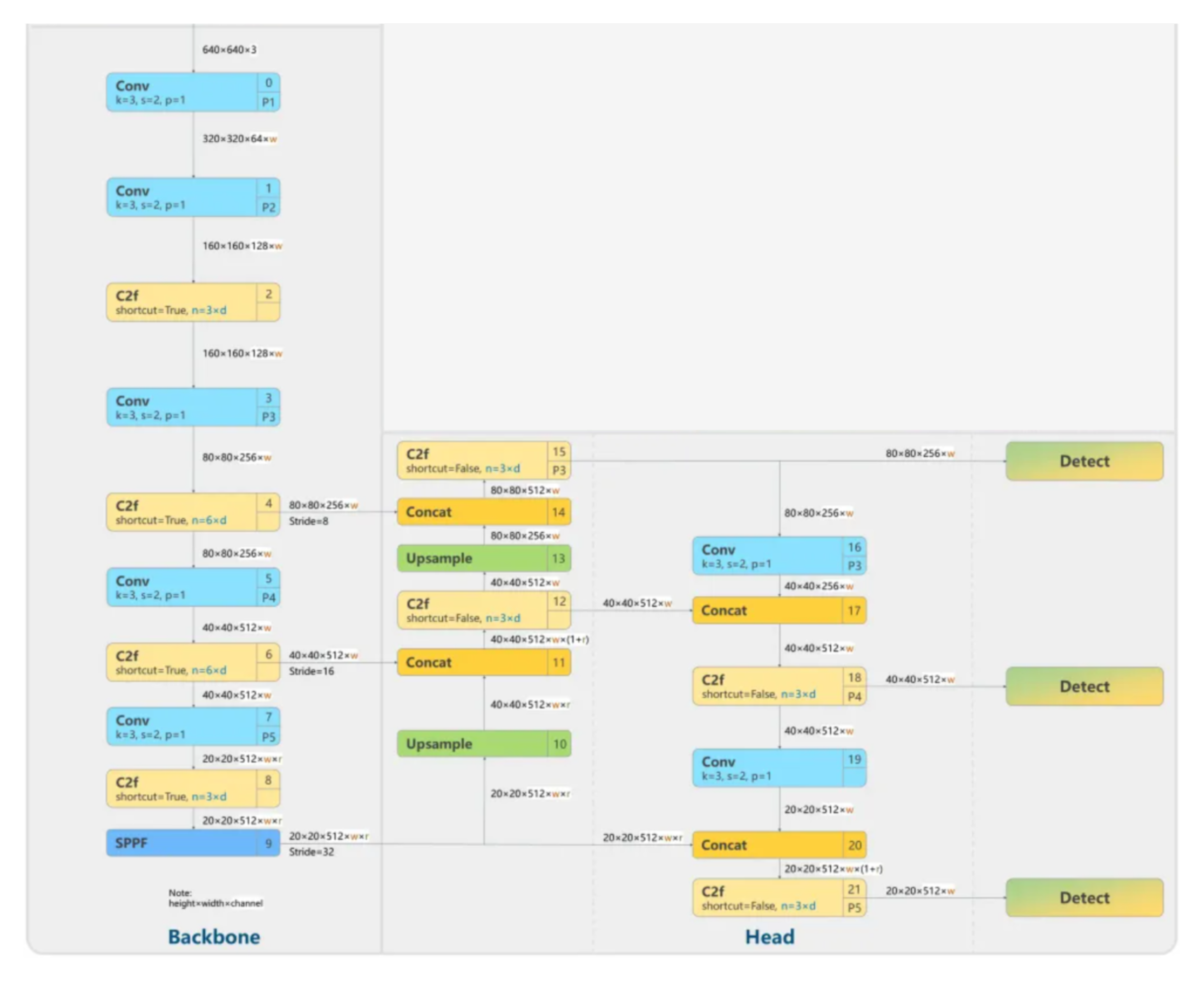
위의 전체적인 구조를 자세히 살펴보면 아래와 같음
Conv
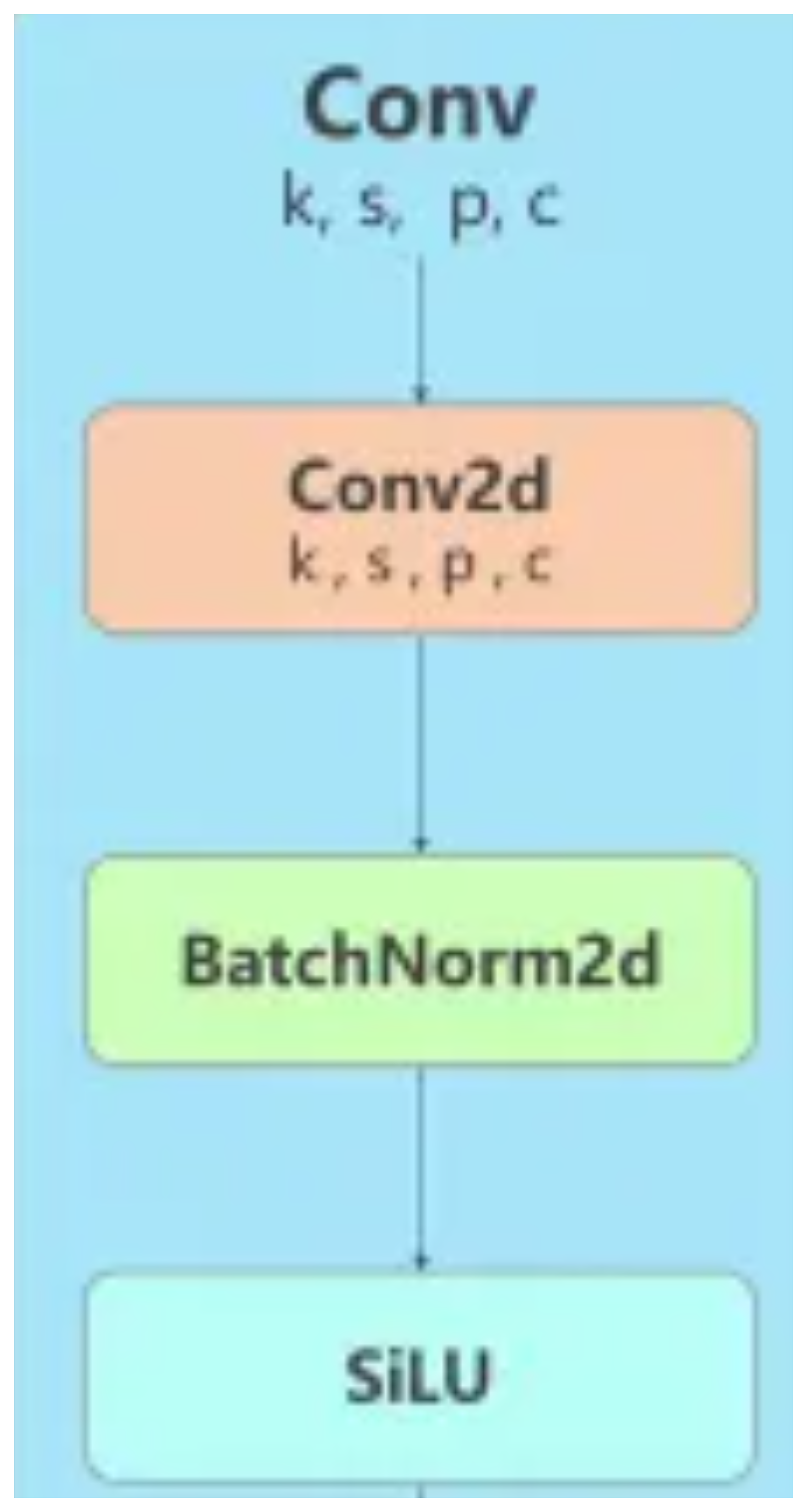
conv2d, BatchNorm2d, SiLU 가 연속되어있는 모듈
C2f
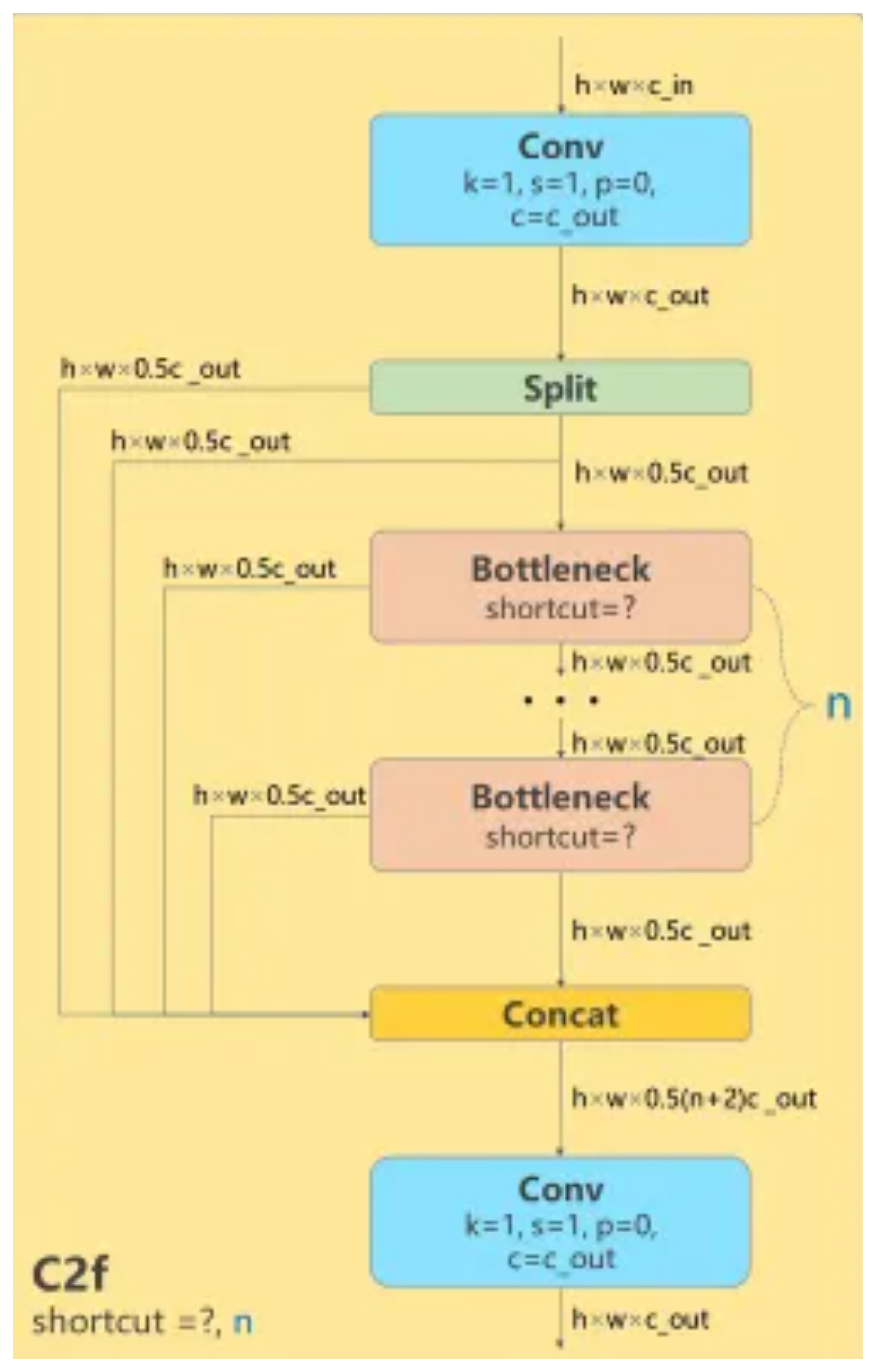
Yolov5에서 사용했던 C3 모듈이 아닌 C2f 모듈 사용
Conv 모듈과 Bottleneck 구조를 거치는 모듈
Conv 모듈과 Bottleneck의 output을 concat했기 때문에 정보 손실을 줄일 수 있음
Bottleneck 구조는 아래와 같음

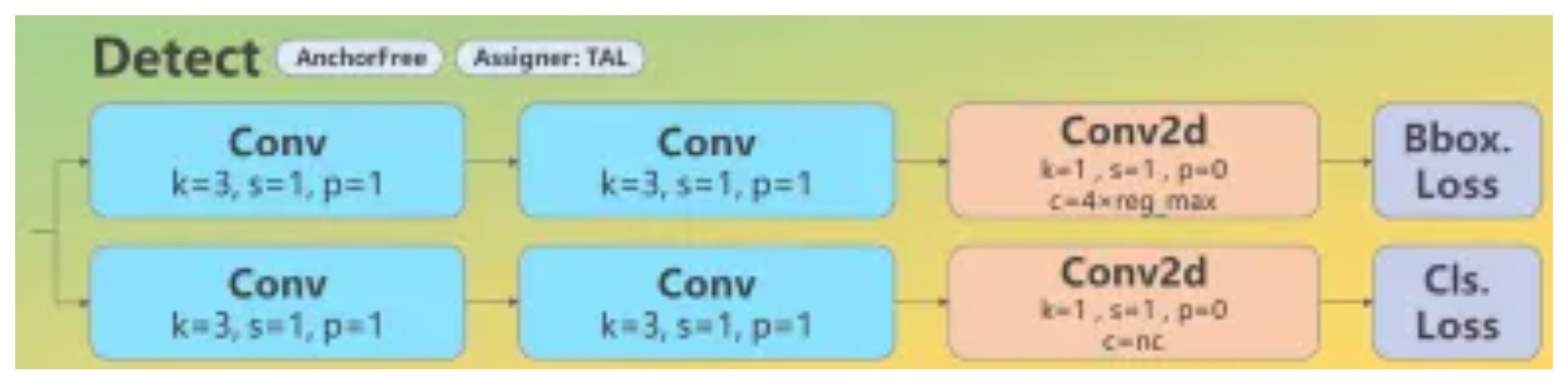
Decoupled Head
Anchor free 모델
One-head 에 비해 속도와 AP 성능이 좋음
Class error를 구하는 branch와 box에 대한 error를 구하는 branch로 나뉨
Training
Loss
\[L_{Total}=\lambda_{bbox}\cdot L_{bbox}+ \lambda_{cls}\cdot L_{cls}+\lambda_{cls}\cdot L_{cls}+\lambda_{dfl}\cdot L_{dfl}\]- $L_{bbox}$ : Bounding box loss
- IoU 기반의 Loss 사용
- $L_{cls}$ : Class loss
- $L_{dfl}$ : Bounding box loss
- Distribution Focal Loss
- 더 정확한 위치를 측정하기 위해 사용
- 필수 사항은 아님