YOLOv5
참고
YOLOv5
YOLO의 흐름
- YOLO
- 24 CNN, 2FC, leakyReLU
- YOLOv2
- Darknet-19, Batch Normalization 적용, Anchor box 사용, Multi-scale training
- YOLOv3
- Efficient backbone, SPP (Spatial Pyramid Pooling)
- YOLOv4
- Mosaic data augmentation, anchor-free detection
YOLOv5 architecture
Backbone, Neck, Head 세 부분으로 구성
아래 그림은 yolov5l 의 구조
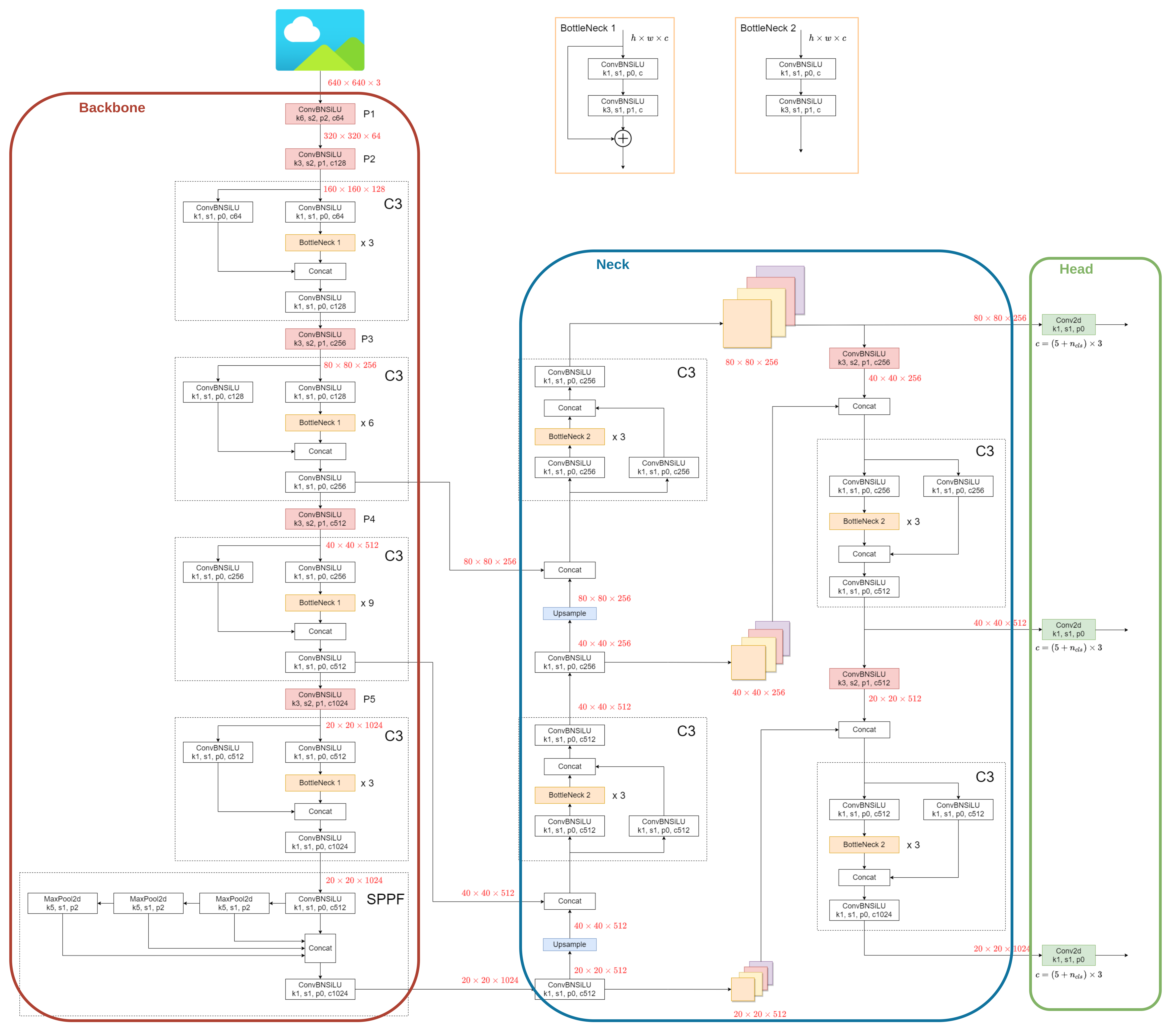
Backbone
입력 이미지의 feature map 추출
이전 버전에서 사용된 Darknet 아키텍처를 수정한 New CSP-Darknet53
Neck
Backbone과 head를 연결
Feature map들을 적절하게 조화하여 더 정교한 feature map 생성
Head
Neck에서 얻은 다양한 scale의 feeature map을 사용하여 각각의 map에서 localization과 classification 실행
물체의 크기에 상관없이 객체를 잘 찾을 수 있음
위의 그림을 조금 더 단순화하여 나타내면
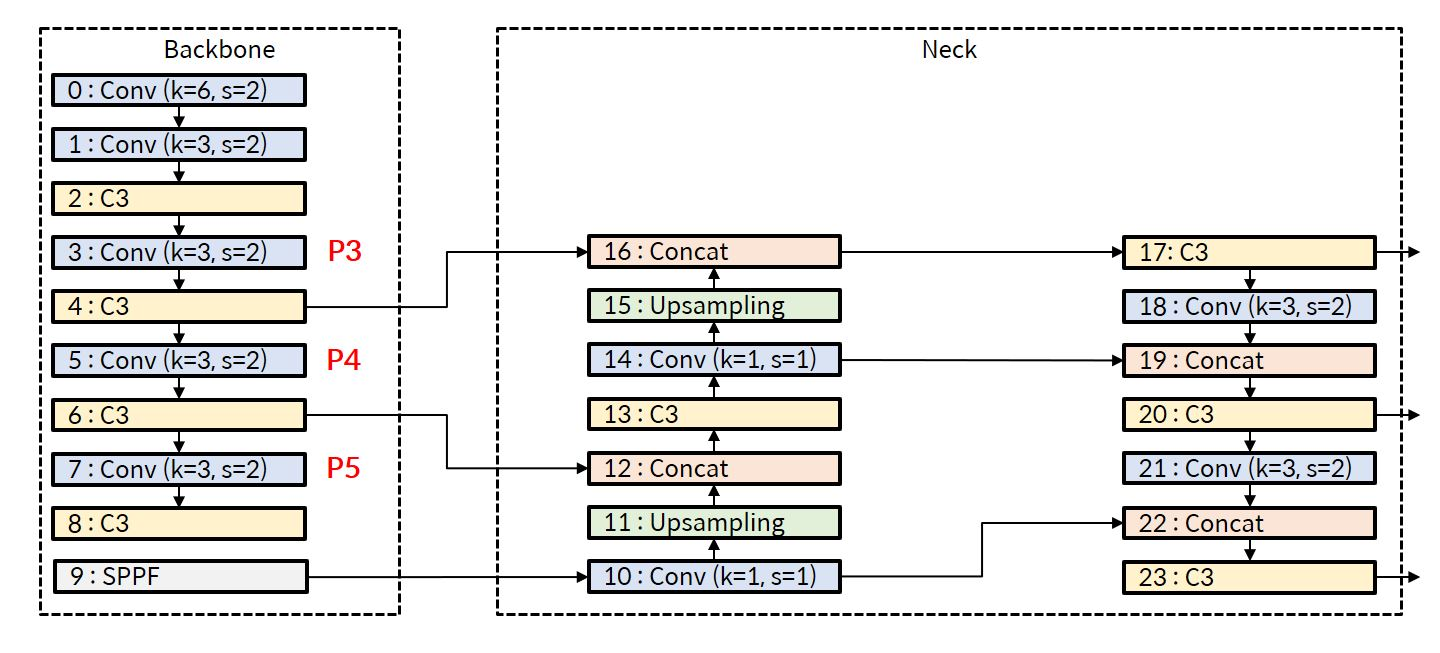
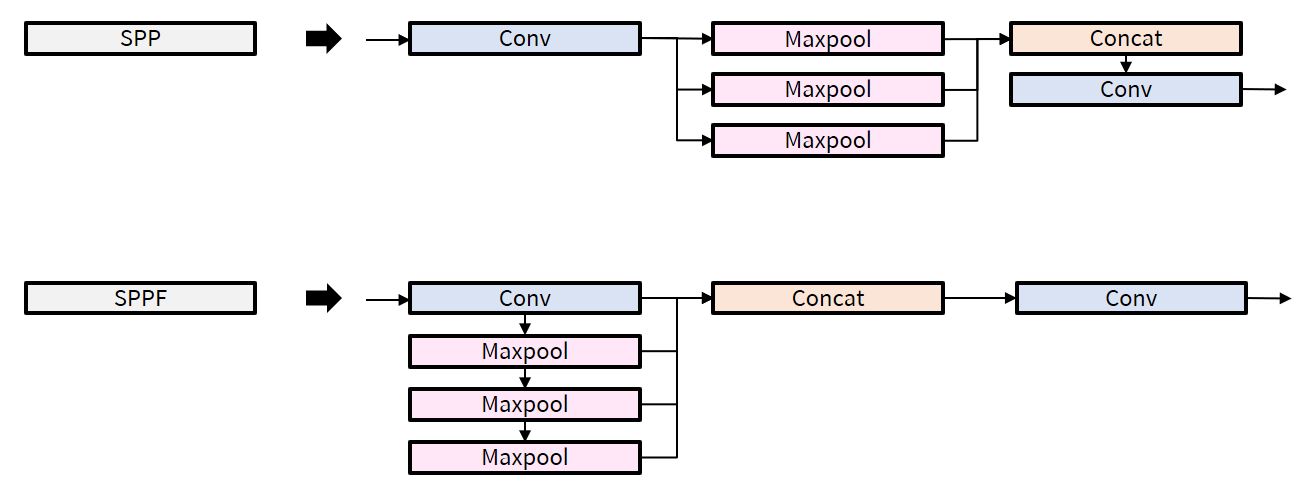
SPP 보다 속도가 더 빠른 SPPF (Spatial Pyramid Pooling Fast) 사용
Activation 함수로 SiLU (Sigmoid Linear Unit) 사용
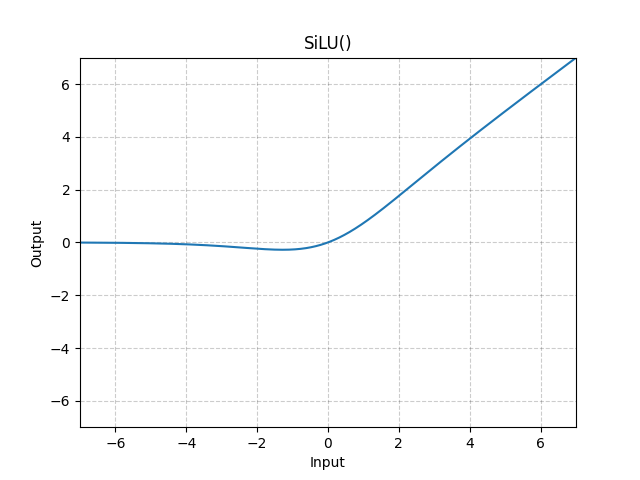
-
Unbounded above (input이 0보다 크거나 같을 때)
-
Bounded below (input이 0보다 작을 때)
Data Augmentation
일반화 성능을 높이고 overfitting을 줄이기 위해서 다양한 data augmentation 사용
- Mosaic Augmentation
- Copy-Paste Augmentation
- Random Affine Transformations
- HSV Augmentation
- Random Horizontal Flip