2D object detection 개요
참고
2D Object detection
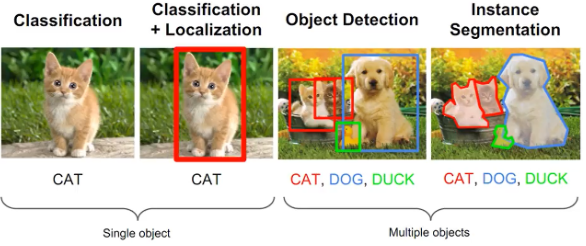
Object Detection = Localization + Classification (Multiple Object)
- 이미지에 존재하는 Object(물체, 객체)들의 위치를 찾기(Localization)
- 찾은 위치에 대한 class를 분류(Classification)
하나의 object가 아닌 여러 개의 object를 찾고 class를 분류
보통 이미지가 입력으로 들어가면 출력으로 detection 된 객체의 위치, 각 class 별 확률, confidence score가 나옴
이 때 confidence score은 이미지에서 찾은 Bounding box 안에 물체가 있을 확률 (있을 것이라고 확신하는 정도)
Architecture
Backbone + ( Nect ) + Head 로 구성
Backbone
여러 layer를 통과하여 이미지의 feature를 추출
기존에는 CNN을 이용한 방법을 많이 사용했지만 transformer을 backbone으로 이용하기도 함
Neck
계층적 구조의, multi-resolution feature를 효과적으로 사용하기 위해 사용
이 구조는 성능을 위해 선택으로 적용 가능
Head
특정 task, 여기서는 2D object detection에 맞춰 생성한 Layer
Branch 라고도 부르기도 함
Object Detection 분류
여러 기준에 따라 모델을 분류 가능
One stage vs Two stage
Architecture의 head 관점
One Stage detection
Localization과 classification을 하나의 네트워크에서 처리하는 detector
즉, feature map에서 한 번에 bounding box 예측
대표적으로 Yolo, SSD와 등의 모델
Two stage Dectector
각각의 네트워크에서 순차적으로 localization과 classification 실행
대표적으로 RCNN, FastRCNN, FasterRCNN 등의 모델
Anchor-based vs Anchor-free
Anchor box는 특정 사이즈나 비율로 미리 정의된 box를 의미
Anchor-based
보통 데이터 셋의 ground truth 분포를 이용하여 Anchor 계산하고 Anchor에 대한 상대적은 크기 비율 예측하는 방법
즉, object 에 대한 아무런 전제 조건 없이 Regression 하는 것이 아닌, Object 크기에 대한 사전 정보(Prior) 이용하는 방법
대표적으로는 YOLOv3, SSD, Faster R-CNN 등
Anchor-free
미리 정의한 Anchor 없이 픽셀 단위에서 bounding box를 바로 regression 하는 방법
대표적으로는 CenterNet, FCOS 등 ,..
Transformer-based Head
Object detection task를 set prediction으로 정의하여 학습
NMS와 같은 heuristic algorithm 제거 할 수 있음
Object Detection 성능 평가 지표
Object Detection 관점에서 TP, FP, FN, TN은 다음과 같음
아래의 사진을 예시로 살펴보면
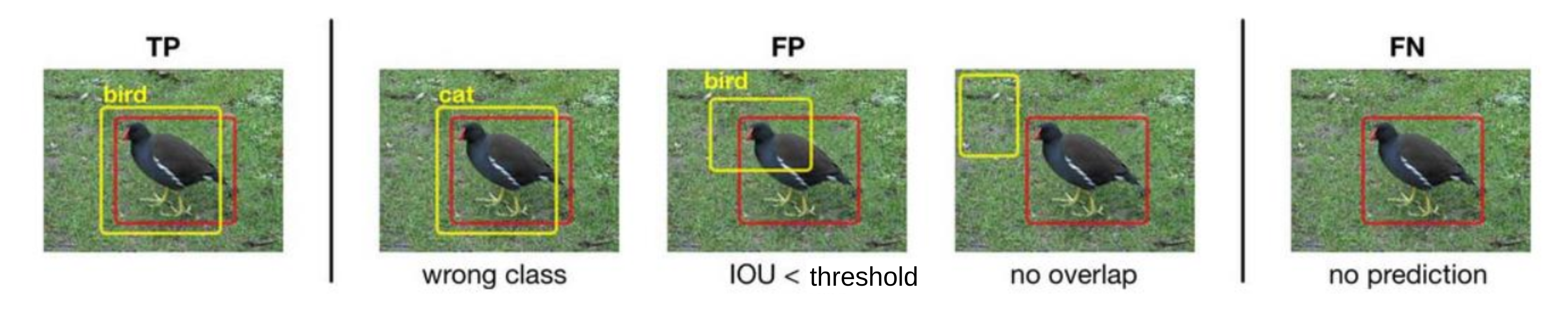
- TP
- 검출한 객체의 bounding box와 groundtruth의 IoU가 특정 threshold 이상이고, 객체의 class를올바르게 예측한 경우
- FP
- 검출한 객체의 bounding box와 groundtruth의 IoU가 특정 threshold 미만이거나 객체의 class를 잘못 예측한 경우
- 즉, 예측은 했는데 잘못 예측한 경우
- FN
- 객체가 존재하는데 객체를 예측하지 못한 경우
- TN
- Object Detection에서는 사용하지 않음
이를 바탕으로 confusion matrix를 나타내면 다음과 같음
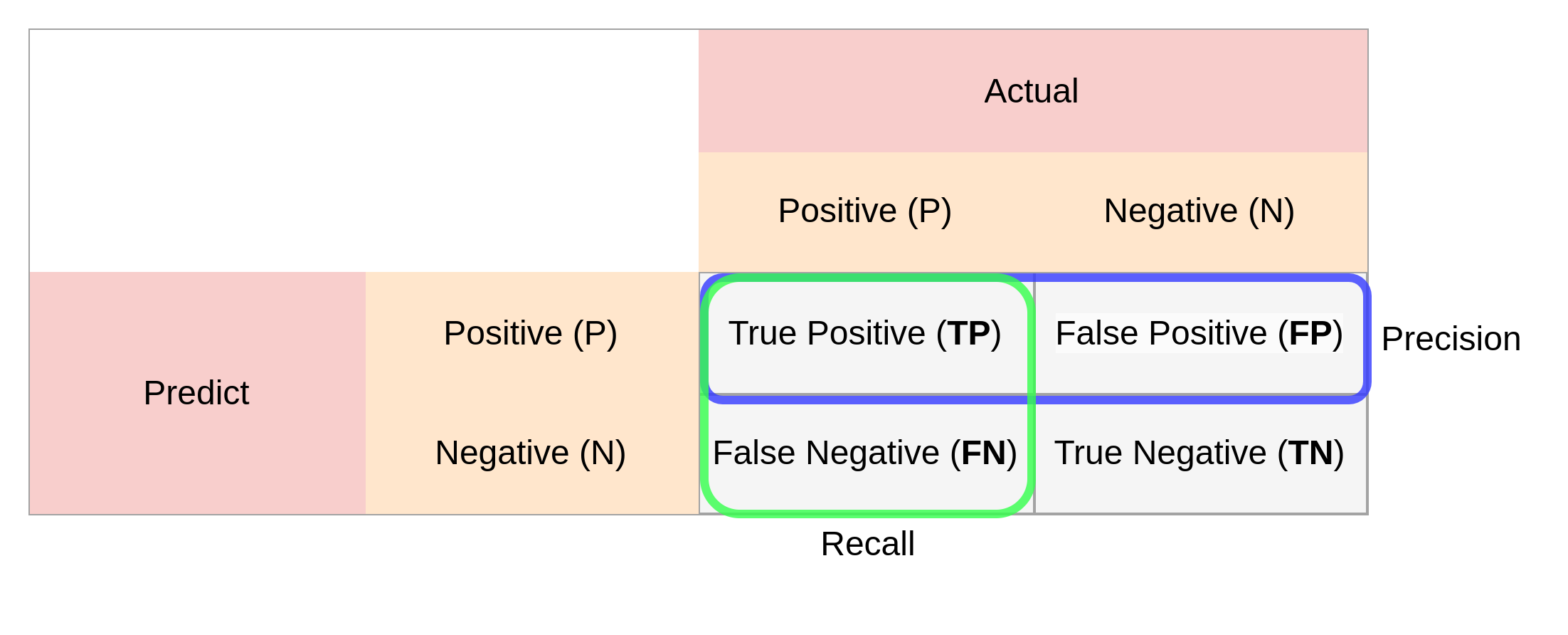
Precision
검출한 객체가 실제 객체와 얼마나 일치하는지 나타내는 지표
\[Precision=\frac{TP}{TP+FP}=\frac{TP}{all\ detections}\]Recall
실제 객체들이 얼마나 잘 검출이 되었는지 나타내는 지표
\[Recall=\frac{TP}{TP+FN}=\frac{TP}{all\ GroundTruuth}\]Precision-Recall Curve
Precision과 Recall은 둘 다 중요한 지표
Confidence threshold 값을 어떻게 설정하는지에 따라 recall과 precision변화
둘 다 중요한 지표이기 때문에 Precision과 Recall의 성능 변화 전체를 확인해야 함
Threshold 값을 조절하면서 계산한 recall 값 변화에 따른 Precision의 값을 그래프로 나타낸 것이 Precision-Recall Curve
총 15개의 객체가 존재할 때,
Detection 된 box에 대한 명칭을 A ~ J 라 하고, 각 box의 confidence score와 TP/FP 여부가 다음과 같음
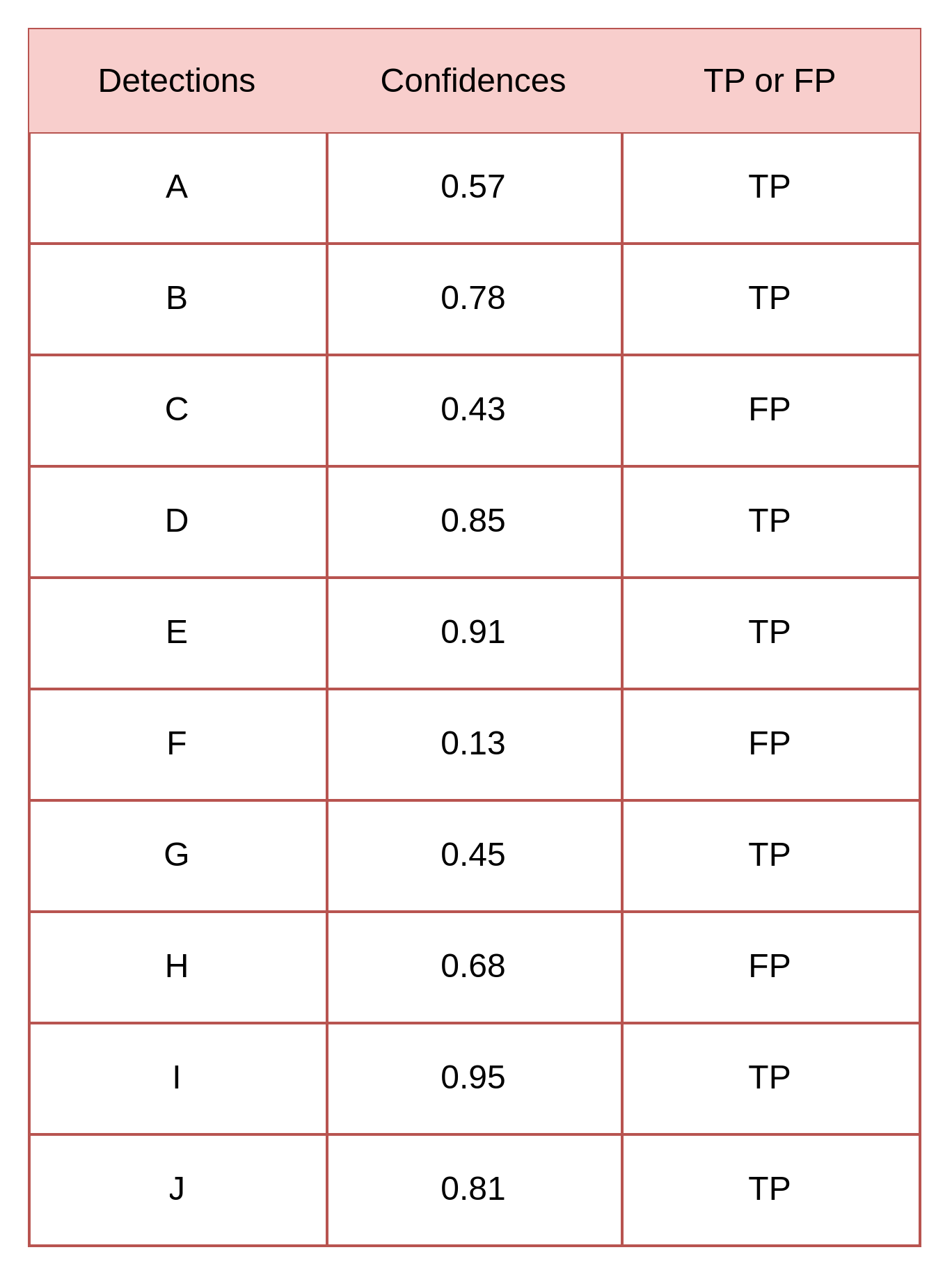
Confidence threshold=0 일 때는 열 개 모두 검출한 것으로 판단
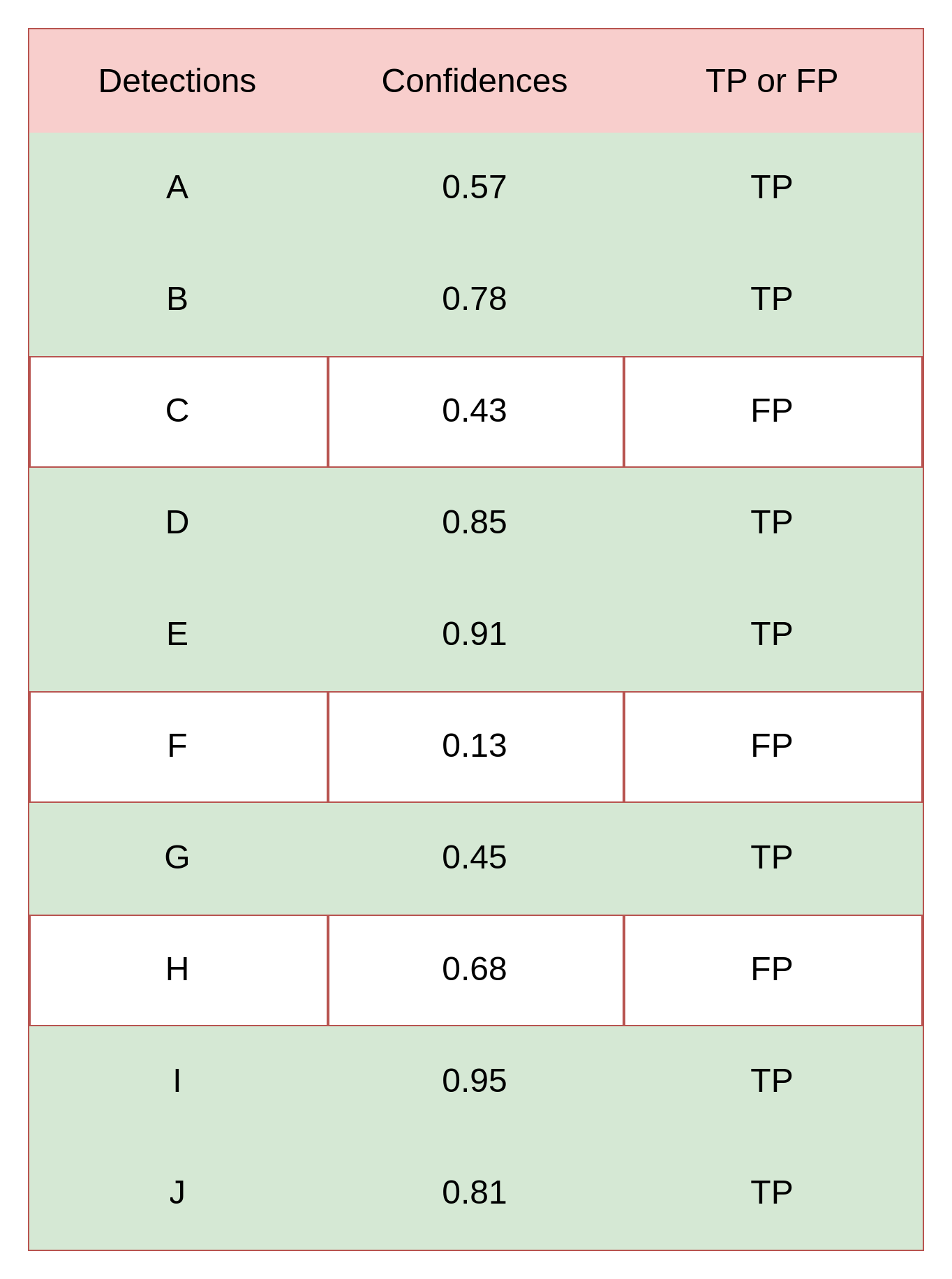
이 때의 Precision 과 Recall 을 계산하면 아래와 같음
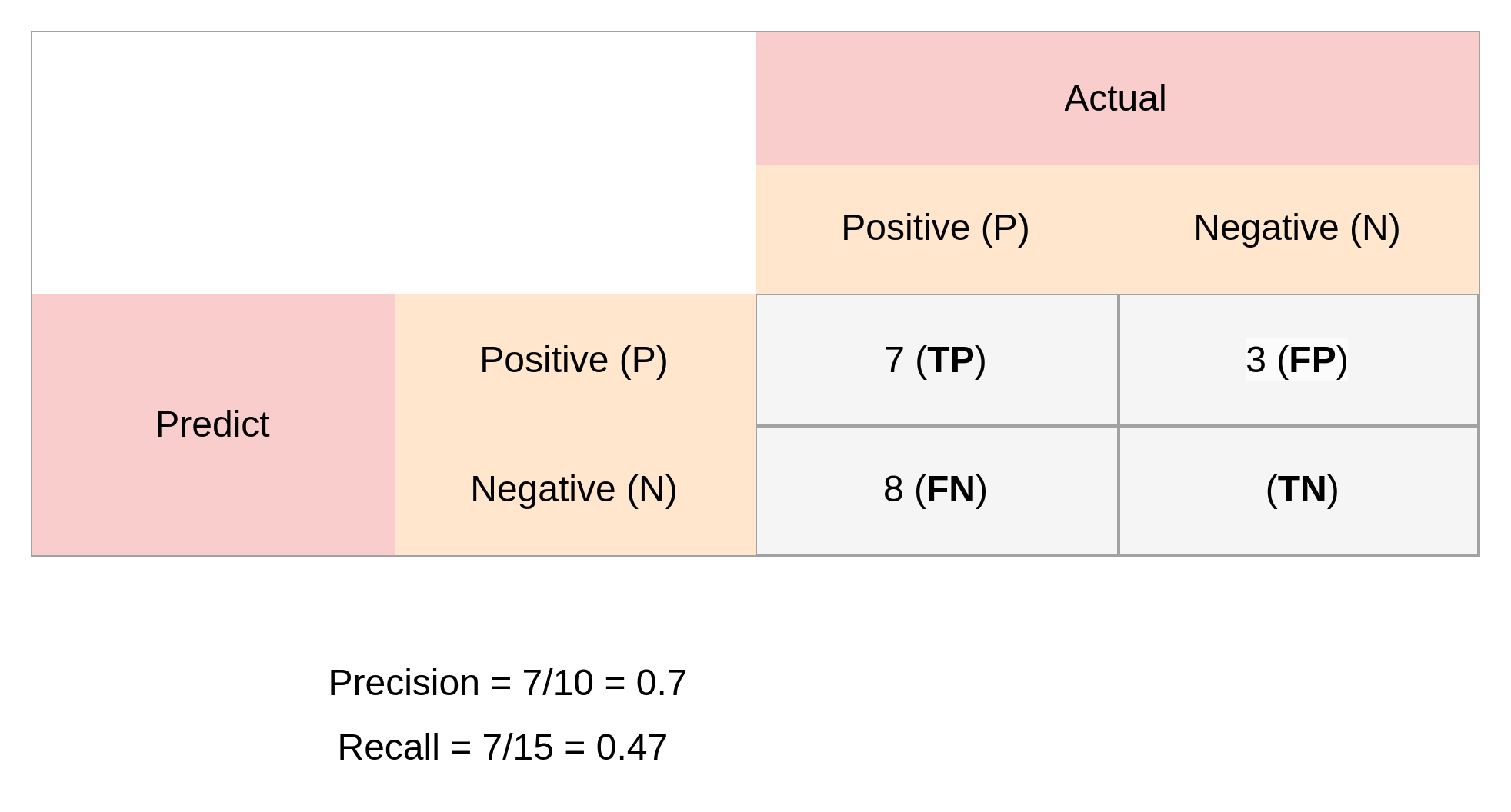
- Precision=0.7
- Recall=0.47..
Confidence threshold=0.95 일 때는 열 개 중 한 개만 검출한 것으로 판단,
즉 나머지는 검출 못했다고 판단
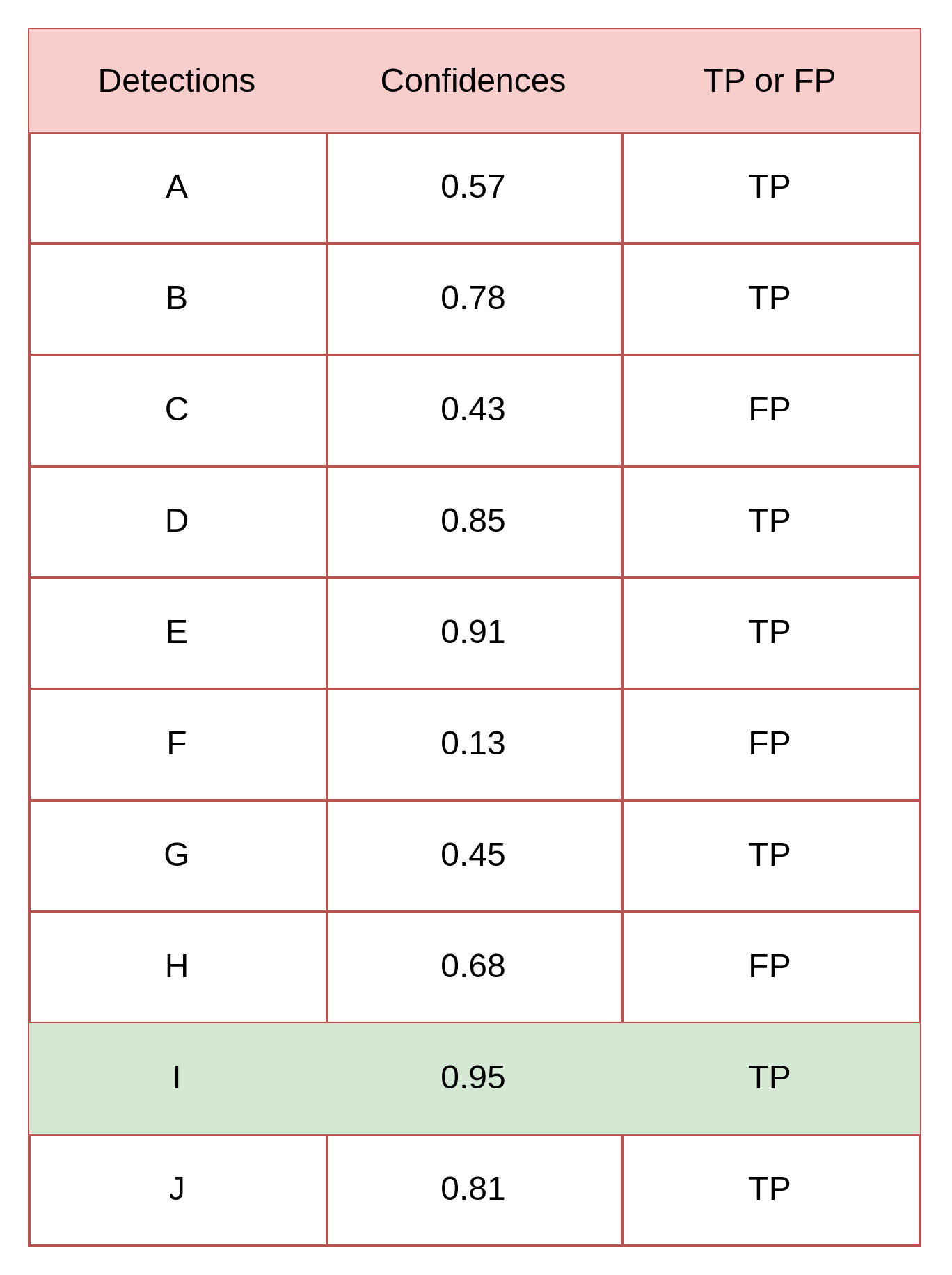
이 때의 Precision 과 Recall 을 계산하면 아래와 같음
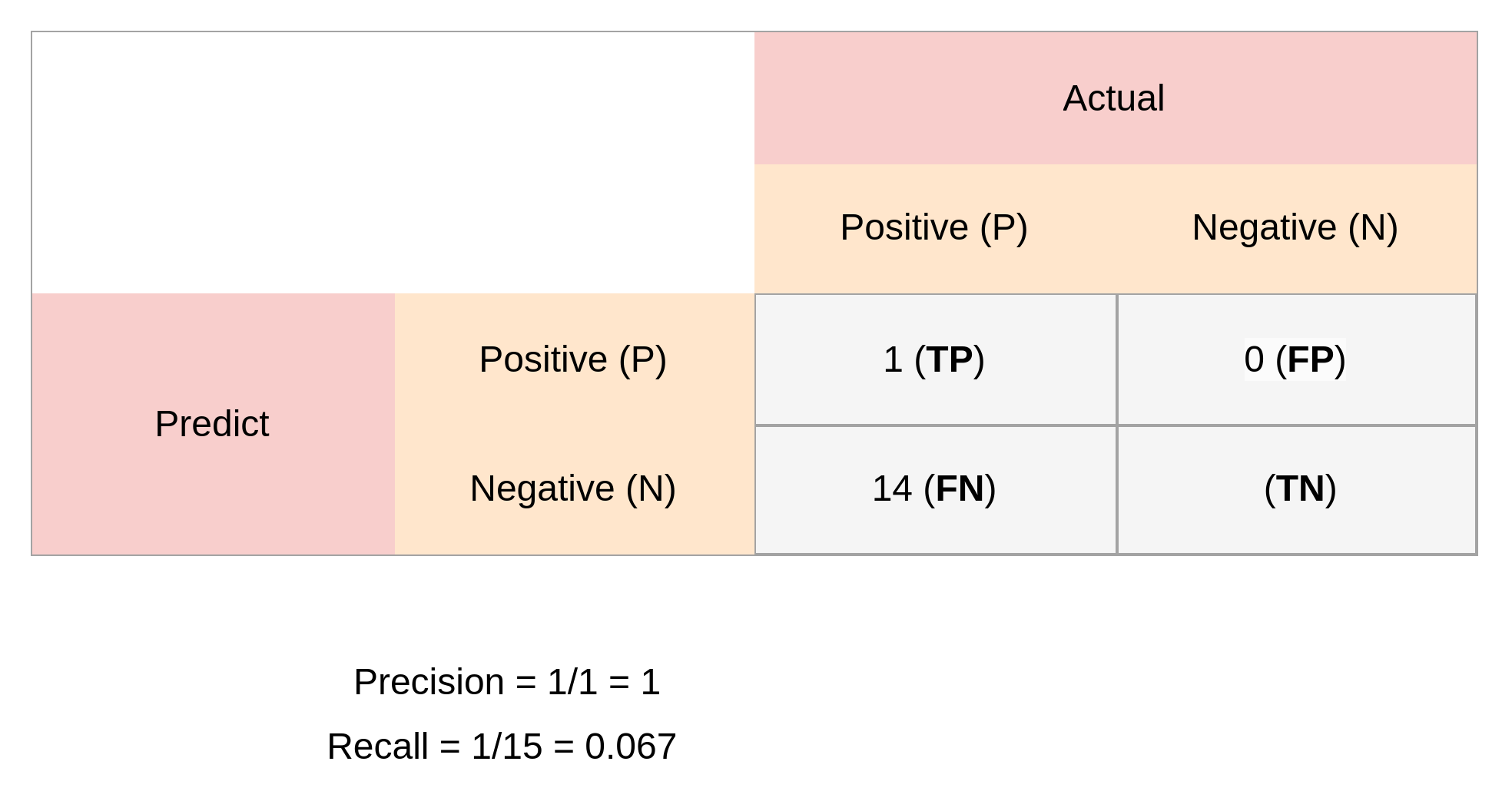
- Precision=1
- Recall=0.067
Threshold 값을 검출된 객체들의 confidence에 맞춰 낮춰가면 다음과 같은 표가 나옴
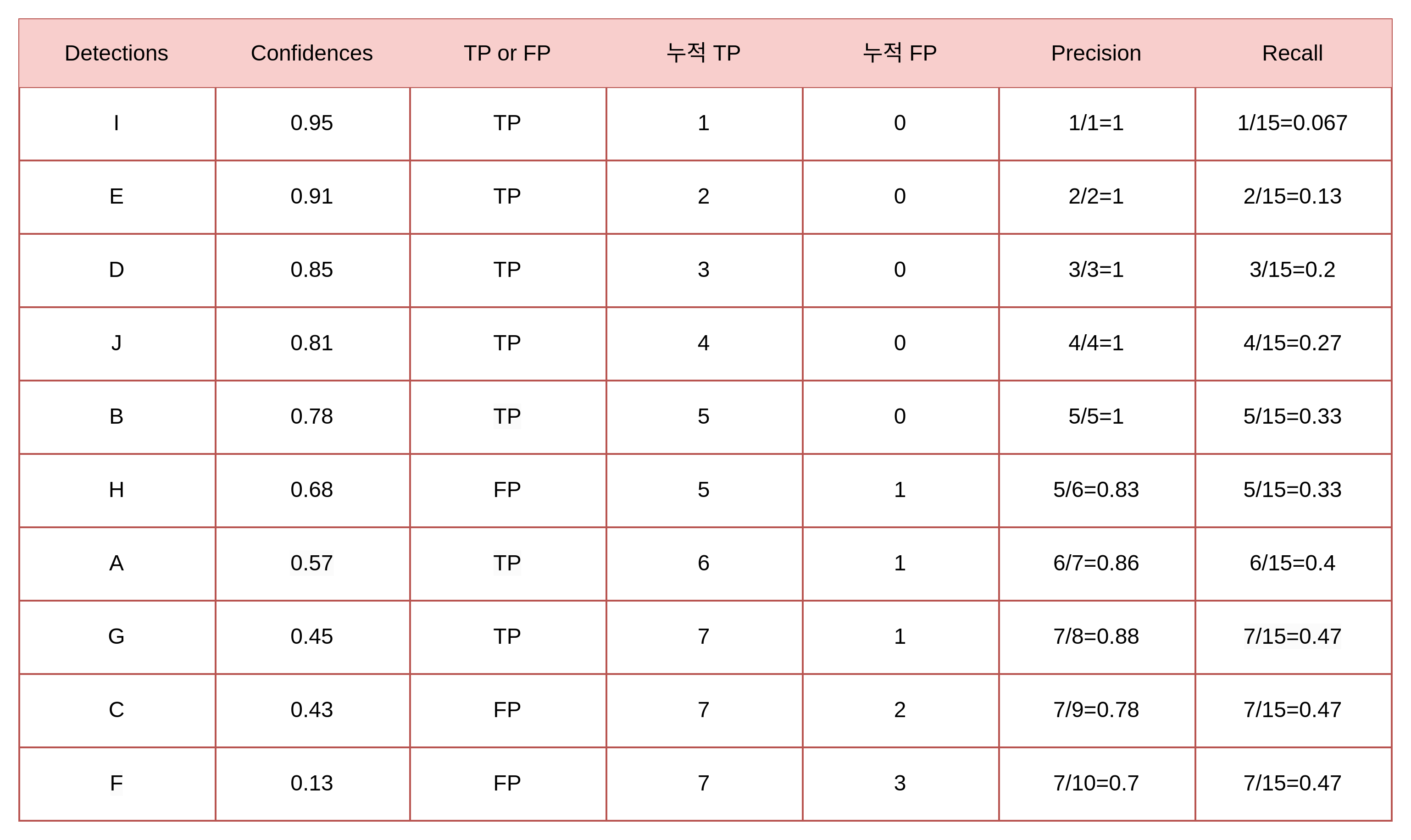
이 Recall 값과 Precision의 값을 그래프로 나타내는 것이 PR 곡선
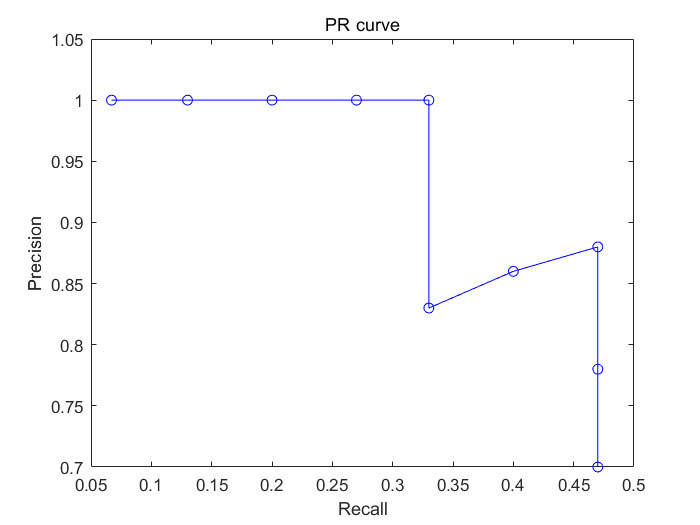
AP (Average Precision)
Precision-recall curve 그래프는 알고리즘의 성능을 전반적으로 파악하기에는 좋으나 서로 다른 알고리즘들의 성능을 정량적으로 비교하기 어려움
Precision-recall curve 그래프를 하나의값으로 나타낸 것이 Average precision(AP)
Average precision는 precision-recall curve 그래프의 선 아래 면적, 즉 AUC (Area under the Curve)를 계산한 값
하지만 계산의 어려움이 있어서 보간법을 활용
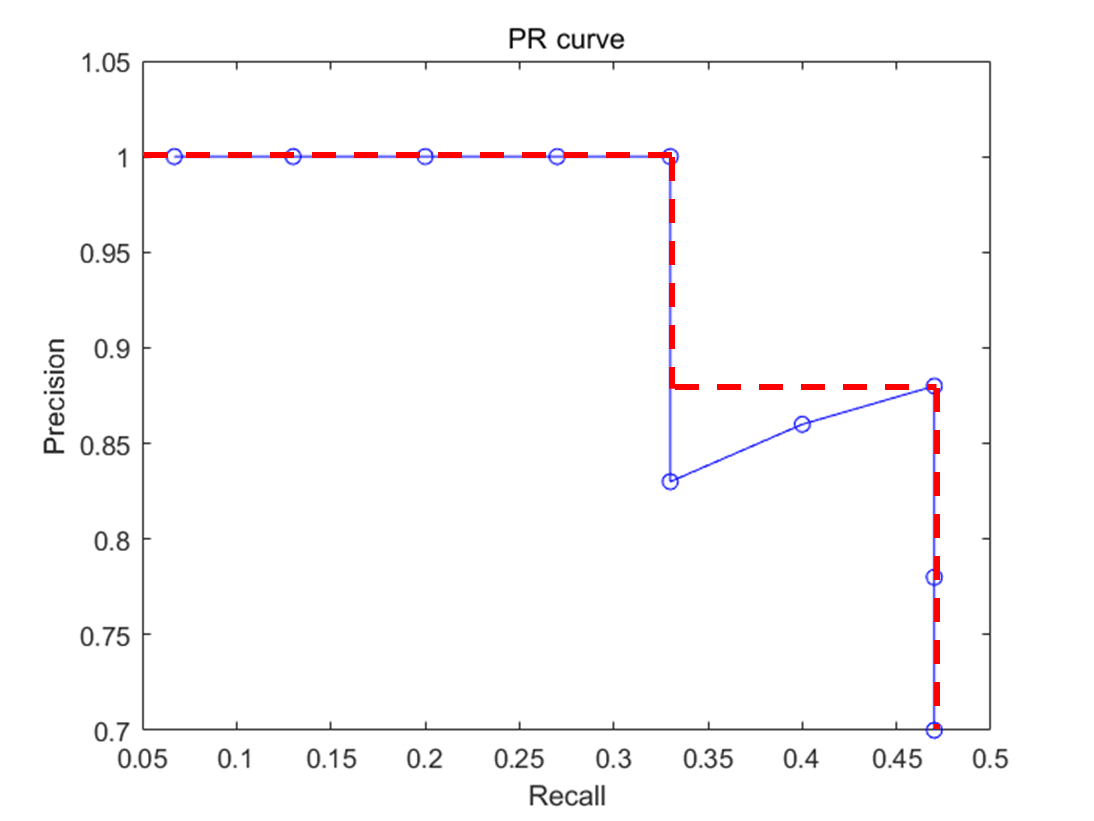
위의 그림처럼 PR Curve를 보간법을 활용하여 계산
- 11-point interpolation 또는 All-point interpolation
Average precision이 높을 수록, 즉 1에 가까울수록 성능이 좋다는 것을 의미
mAP (mean Average Precision)
여러 class의 객체를 검출하는 경우에 사용
각 class 의 AP를 계산하여 합치고 모든 class의 수로 나누어 주면 이를 mAP 라 함
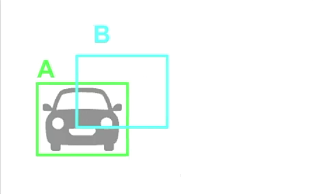
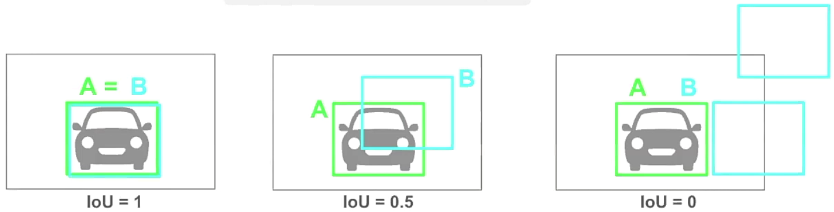
IoU (Intersection over Union)
다른 이름으로 Jaccard index 라고도 함
모델이 예측한 bounding box와 ground truth 의 localization 유사도를 측정하는 방법
아래 사진을 예시로 하면
GIoU (Generalized IoU)
1-IoU 를 loss로 사용하여 학습을 하는데 IoU는 교집합이 없으면 예측한 box의 위치에 상관없이 0이 계산 됨
가장 오른쪽의 경우에 학습에 문제가 생김
예측한 박스의 위치에 상관없이, 즉 그림에서는 B의 위치와 상관없이 값이 0이므로 예측한 두 box와 ground truth box와의 오차가 얼마나 나는지 반영하지 못함
이를 개선하기 위해서 나온 방법이 GIoU
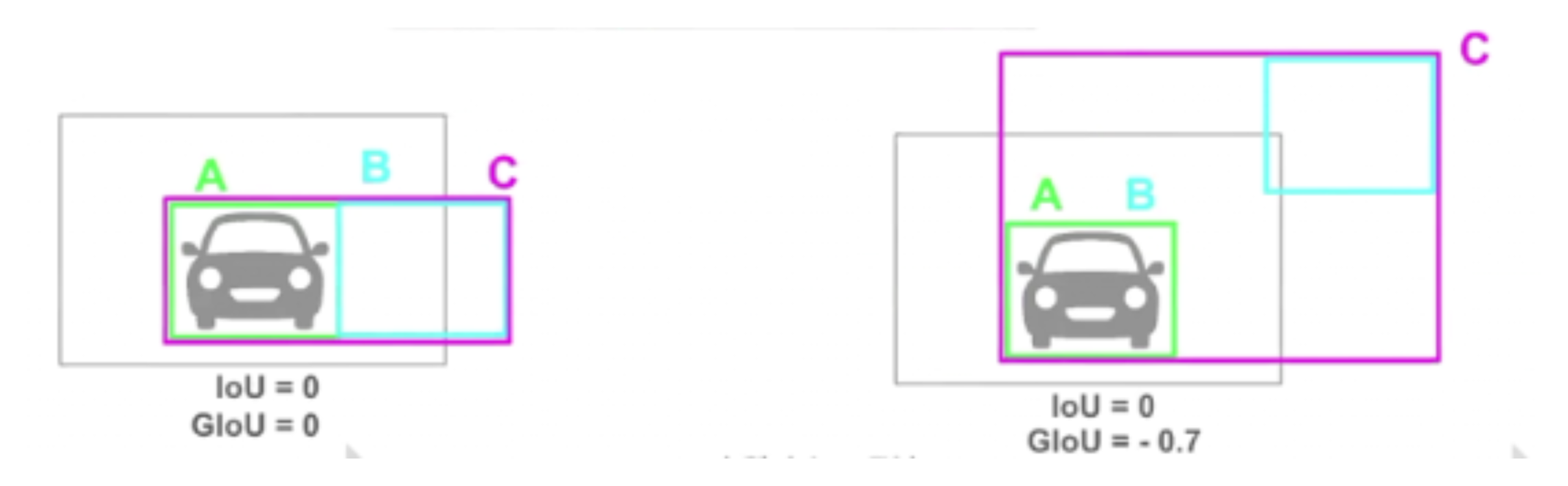
\(GIoU=IoU-\frac{|C-A\cup B|}{|C|}\)
이렇게 계산하면 IoU가 0이여도 예측한 box의 위치에 따라 값이 달라지는 것을 확인
GIoU를 개선한 여러 방법들도 존재