ArcFace: Additive Angular Margin Loss for Deep Face Recognition
ArcFace: Additive Angular Margin Loss for Deep Face Recognition
CVPR 2019
Face recognition에서 angular margin을 주는 loss function을 소개하는 논문
Introduction
Face Recognition을 위한 DCNNs을 학습하는 2가지 큰 연구 방향 존재
- 다른 identities들을 분류 할 수 있는 multi-class classifier 학습
- softmax classifier
- 임베딩 직접 학습
- triplet loss
대규모 데이터셋에서 face recognition에서 좋은 성능을 낼 수 있지만 단점 존재
Softmax classifier의 단점combinatorial explosion in the number of face triplets
- 학습된 feature들은 폐쇄형 (closed-set) 분류 문제에서는 분류가 가능하지만 개방형 (open-set) 얼굴 인식에서는 어려움
- 선형 변환 행렬 $W \in\mathbb{R}^{d\times N}$ 이 identity의 수 N에 따라 선형 증가
Triplet loss의 단점
- 대규모 데이터셋은 face triplet 조합이 폭발적으로 증가
- 상당한 iteration step의 증가를 가지고 옴
- 효과적인 모델 학습을 위한 semi-hard sample mining의 어려움
margin의 이득을 보고 sampling 문제는 피하기 위해 최근에는 margin penalty와 softmax loss와 통합하는 데 초점을 맞춤
Softmax loss는 embedding feature 선형 변환 행렬 간의 곱셈 단계에서global sample-to-class 비교를 수행
Sphereface 는 angular margin에 대한 중요한 idea를 도입했지만 loss 계산을 위한 일련의 근사값들이 필요해서 학습이 불안정함
- 학습을 안전화시키기 위해 softmax loss를 포함하는 hybrid loss 제시
- 경험적으로 softmax loss가 학습 과정 지배
Proposed Approach
ArcFace
Softmax
- $x_{i}$ : $i$번째 sample의
Hypersphere Loss
Numerical Similarity
SphereFace
- Softmax 함수에서 W 정규화해주고 angular 공간을 이용해 feature 구분
- Angular margin을 통해 intra-class variance를 최소화하고 inter-class variance 최대화
- $m$ : angular margin
CosFace
Feature x 도 정규화
Angular margin을 cosine 값 자체에 더함
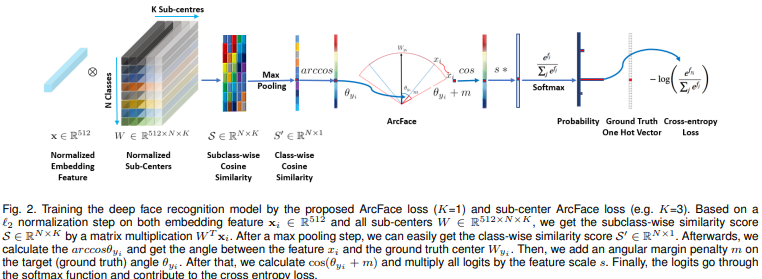
- 정규화 된 feature와 정규화 된 weight 이용
- arcface의 특징은 각도에 직접적인 margin을 줌
- 그 후에 softmax를 적용
ArcFace 코드 실행
Docker Image : pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel
GPU : NVIDIA GeForce RTX 4080 Laptop GPU
코드 : 깃허브 주소
Training
AI Hub의 한국인 안면 이미지의 중화질 데이터의 일부를 사용하여 학습 진행
학습시키기 위해서 데이터를 변환하고 하는 과정이 까다롭게 느껴짐.
Inference
임의로 이미지들로 DB를 구성하고 확인
-
DB에 있는 인물 사진 결과
-
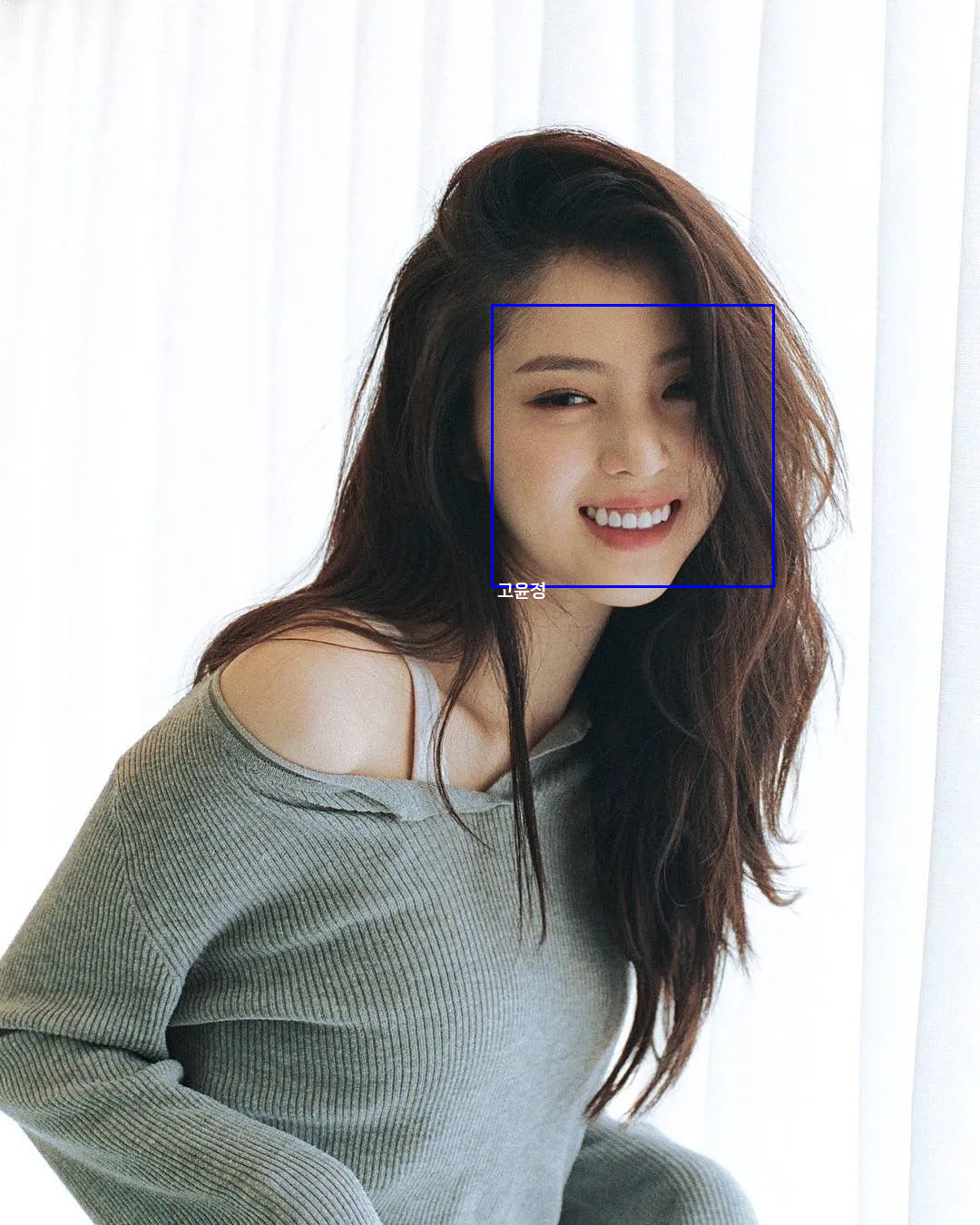
DB에 없는 인물 사진 결과
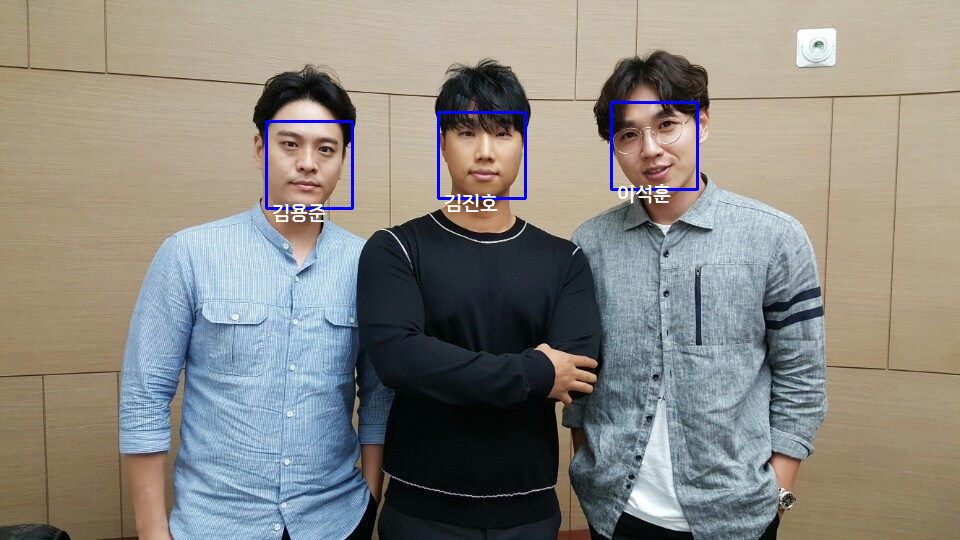
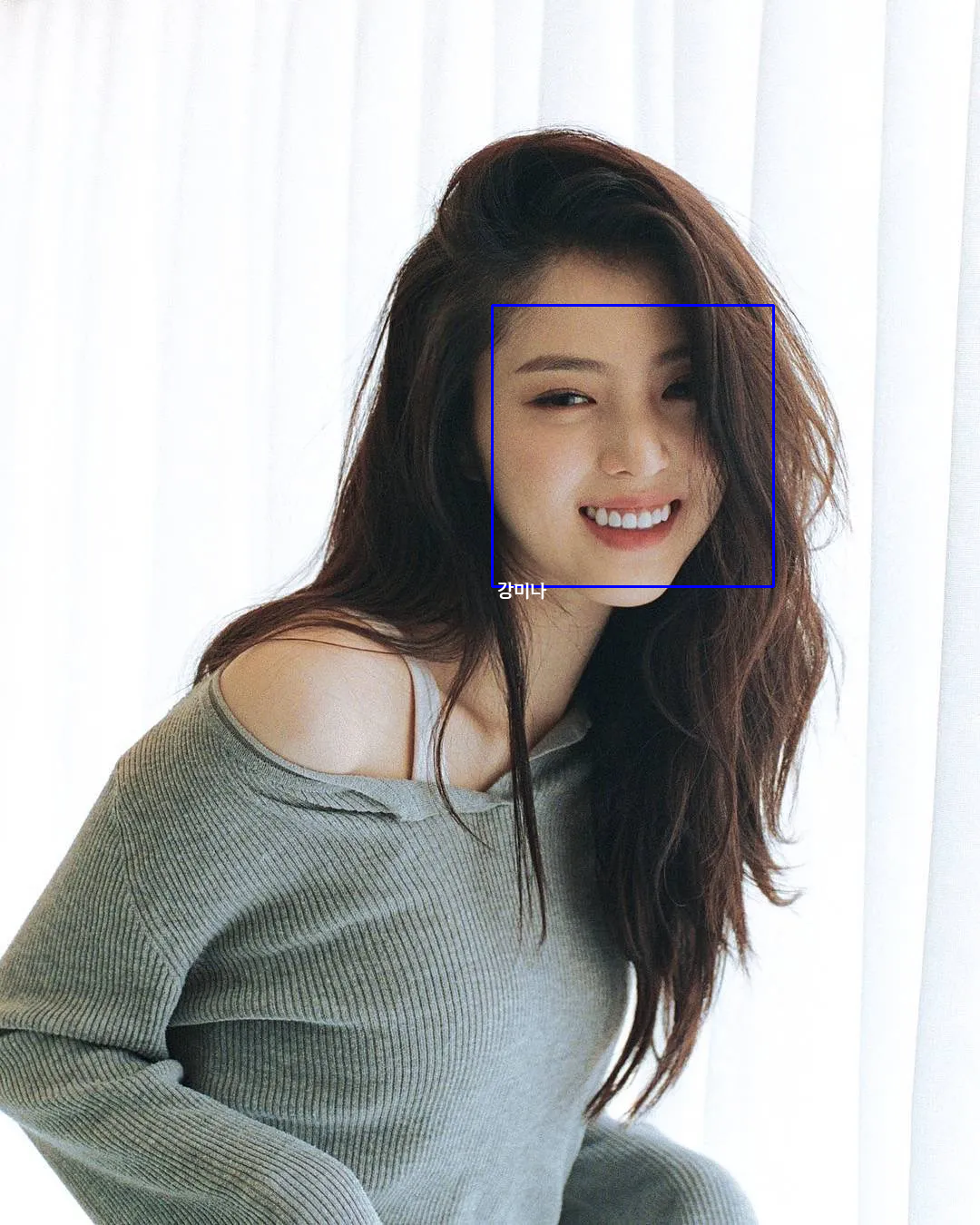
DB에 있는 인물 사진의 결과 찾는 것을 확인해봤을 때 모두 본인을 잘 찾는 것을 확인
한국인 안면 이미지 데이터로 fine-tuning 한 경우 한 명을 제외한 두 명이 DB의 본인 사진과의 거리가 줄어드는 것을 확인
- 데이터 양을 조절하여 적은 수를 학습하였기 때문에 전체 이미지 모두를 이용하거나 데이터를 더 추가하면 성능이 향상 가능
DB에 없는 이미지를 확인한 결과 제대로 결과를 내지 못하는 것을 확인
DB 데이터와의 최소의 거리가 1.5 이상인 경우 None이 나오도로고 설정
하지만 최소값이 1.5 보다 작으므로 DB에 없는 데이터라고 판단하지 못함
하지만 그래도 fine-tuning 을 진행한 경우에는 최소 거리가 늘어남… 의미가 있을지는 모르겠지만
추후에 학습을 제대로 해서 확인해보고 싶음