PFLD: A Practical Facial Landmark Detector
PFLD: A Practical Facial Landmark Detector
2019

Introduction
Face landmark detection에서 주로 발생하는 어려움
Challenge # 1 Local Variation
표정, 빛, occlusion 가 있는 경우 face landmark가 잘못잡히거나 사라지는 경우 발생
Challenge # 2 Global Variation
포즈나 이미지 퀄리티는 이미지에서 얼굴에 영향을 미치는 주요한 요소
Challenge # 3 Data Imbalance
class 나 attributes (표정, 빛, occlusion 등)에 따라 데이터가 imbalance 함
Challenge # 4 - Model Efficiency
모델 사이즈와 계산량이 중요한 제한 요소
#####
PFLD는 실제 환경에서도 모바일 디바이스에서 실시간 (super real-time)으로 landmark detection 가능
End-to-end single stage network 를 사용
학습을 할 때만 하나의 보조 네트워크를 사용하여 각 샘플마다 rotation information 을 측정하여 성능을 높임
Geometrical regularization을 고려하여 만든 새로운 loss는 data imbalance 문제를 해결
- 각 상태에 따라서 샘플들의 weight 조정
Challenging benchmark에서 SOTA 성능이 나옴
모바일 폰에서 (Qualcomm ARM 845 processor) 2.1Mb 사이즈의 모델로 각 얼굴마다 140fps 로 작동
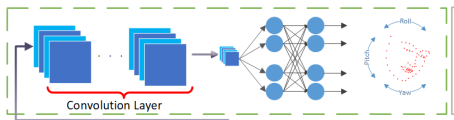
Methodology
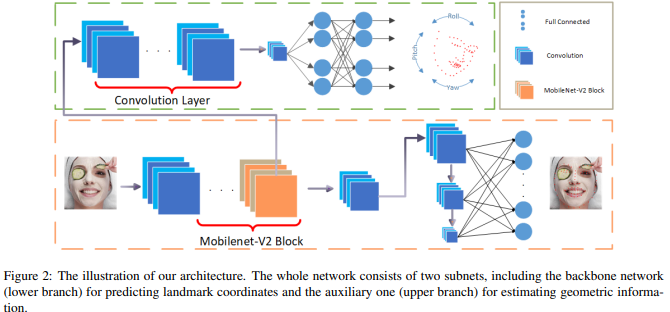
-
보조 네트워크에서는 convolution layer와 fully-connected layer를 지나 rotation 정보가 output
-
메인 branch에서는 face landmark 정보가 output
Backbone Network
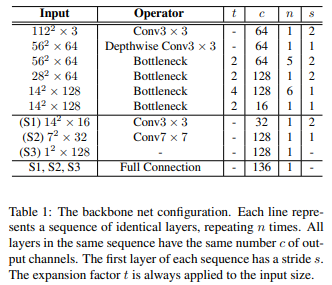
- MobileNet V2 이용
- Depthwise Seperable Convolutions
- Linear Bottlenecks
- Inverted Residuals
- ReLU6
- S1, S2, S3 같이 multi- scale로 구성하여 Multi-Scale Fully-Connected (MS-FC) 을 활용하여 얼굴의 global한 구조, 즉 전체적인 특징을 잘 잡아내서 높은 정확도
- 사람의 얼굴은 전체적인 구조의 관계성이 있음
- 간단하지만 좋은 성능을 내는 구조
- Width parameter를 이용해서 모델 압축 가능
- Width parameter인 width multiplier는 layer의 channel수를 일정 비율로 줄임
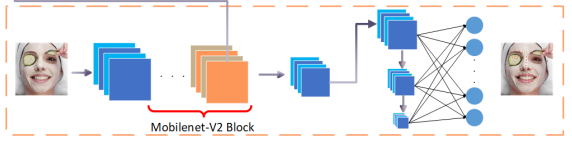
Auxiliary Network
기존의 특징점만 사용하는 모델보다 더 좋은 성능을 낼 수 있음
-
Convolution연산과 fully-connected 연산으로 구성되어 있음
-
Backbone 의 4번째 block이 input으로 들어감
-
3차원 회전 정보인 yaw, pitch, and roll 각도를 측정하고자 함
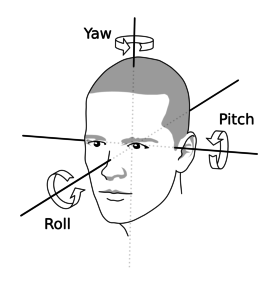
출처
Ground Truth 값과 predicted된 landmark로 오일러 각도를 계산해도 가능
하지만 초기에는 predicted 된 landmark 정확도가 좋지 않음
또한 학습 데이터에는 정면 얼굴이 없기 때문에 직접적으로 오일러 각도를 구할 수 없기 때문에 사용
오일러 각도를 계산하기 위한 추가적인 annotation을 사용하지 않음
- yaw, pitch, roll 값이 얼마인지 annotation을 따로 하지 않음
학습 진행 방법
- 여러 장의 정면 이미지의 얼굴의 평균값을 이용하여 하나의 standard face를 만든 후 11개의 landmark 지정함
- 각 얼굴과 standard face의 11개의 landmark의 rotation matrix 구함
- Rotation matrix를 이용하여 오일러 각도 계산
Loss Function
\[L:= \frac{1}{M}\sum_{m=1}^{M}\sum_{n=1}^{N}\gamma_{n} \left\|d_{n}^{m}\right\|\] \[L:= \frac{1}{M}\sum_{m=1}^{M}\sum_{n=1}^{N}\left (\sum_{c=1}^{C}{w_{n}^{c}}\sum_{k=1}^{K}{(1-cos{\theta_{n}^{k}})} \right )\left\|d_{n}^{m}\right\|\]- $M$ : input image의 개수
- $N$ : face landmark의 개수
- $C$ : attribute class
- $K$ : 3d pose 정보의 수 (3- yaw, pitch, roll)
- $\gamma_{n} $: 3d pose 정보를 가짐
- $w_{n}^{c}$: : data imbalance 해결하는 가중치
3D pose 정보와 2D landmark의 distance를 이용하여 간단하게 표현
Forward와 barkward 모두 간단하게 연산 가능
이 Loss function은 cascade 되기 때문에 single stage와 같은 효과를 주어 최적화 성능 높임
Implementation Details
Input image size : 112 x 112
Batch size : 256
Optimizer : Adam
Weight decay : 10e-6
Momentum : 0.9
Learning rate : 10e-4
Nvidia GTX 1080Ti
Experimental Evaluation
Dataset
- 300W
- 5개의 얼굴 데이터를 annotation
- -LFPW, AFW, HELEN, XM2VTS, IBUG
- 68개 landmark
- 5개의 얼굴 데이터를 annotation
- AFLW
- 21개 landmark
Experimental Results
Model Size & Processing Speed

- PFLD 뒤의 숫자는 depth 조절
Normalized Mean Error
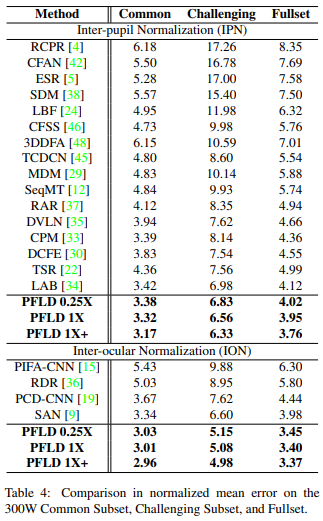
Inter-pupil Normalization
\[L=dist(p_{96}, p_{97})\] \[NME(S,S^{*})=\frac{1}{N}\sum_{i=1}^{N}\frac{\left\| s_{i}-s_{i}^{ * } \right\|_{2}^{2}}{L}\]- 눈동자 사이의 거리로 normalization
inter-ocular Normalization
\[L=dist(p_{60}, p_{72})\] \[NME(S,S^{*})=\frac{1}{N}\sum_{i=1}^{N}\frac{\left\| s_{i}-s_{i}^{ * } \right\|_{2}^{2}}{L}\]- 왼쪽 눈의 왼쪽 끝과 오른쪽 눈의 오른쪽 끝 좌표의 거리로 normalization
PFLD의 성능이 위의 두 요소에서 훨씬 좋음을 확인

- 위의 표의 NME는 모든 특징점을 포함하는 box의 size로 normalization
Conclusion
accuracy, efficiency, compactness 모두 만족
Backbone network의 성능을 높이기 위한 auxiliary network 사용
Geometric regularization과 data imbalance를 모두 고려한 새로운 loss function 고안
auxiliary network 통해 Rotation information (yaw, pitch, roll) 을 사용하여 geometric 제약을 둠
- 정확도 향상
PFLD 코드 실행
Docker Image : pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel
GPU : NVIDIA GeForce RTX 4080 Laptop GPU
코드 : 깃허브 주소
Training
WFLW 데이터를 이용하여 학습을 500회 진행
Test
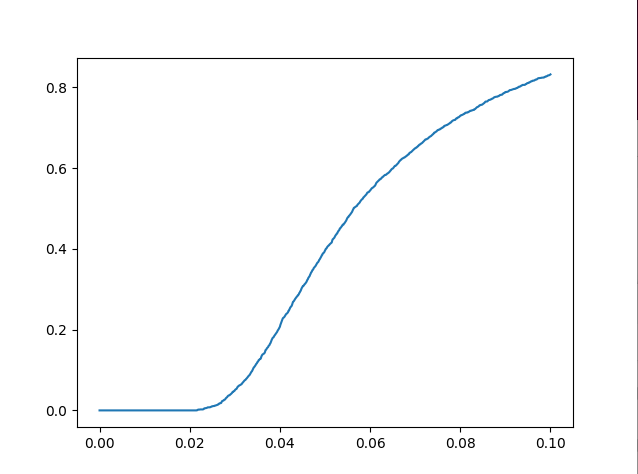
Test 결과는 아래와 같음
- nme: 0.0727
- auc @ 0.1 failureThreshold: 0.3773
- failure_rate: 0.16800000000000004
- inference_cost_time: 0.001215
- AUC curve plot
Inference
mtcnn으로 얼굴 영역 찾고 학습한 모델로 landmark 검출
-
origin_img

- [235.58936453 109.41309071 462.83261442 408.69015199]
- [x1, y1, x2, y2]
- [235.58936453 109.41309071 462.83261442 408.69015199]
-
gray_img
mtcnn 의 입력 이미지를 gray로 변환하여 진행
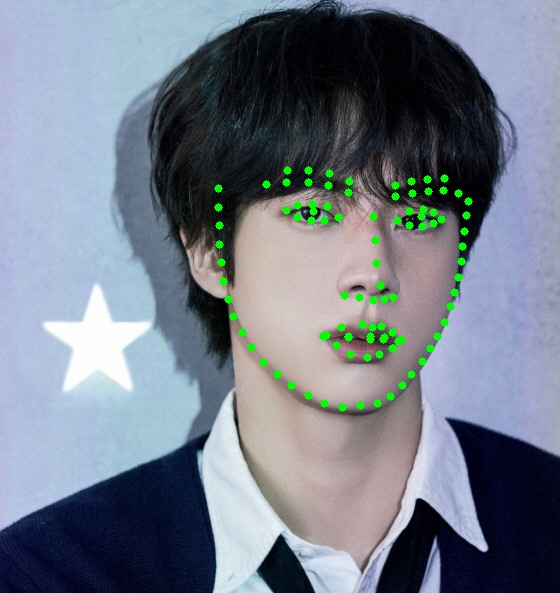
- [226.69451093 108.52436095 444.98290239 413.27364492]
Detection 된 얼굴의 영역에 따라서 face landmark가 다르게
face landmark 도 중요하지만 얼굴 영역을 검출 잘하는 것도 중요