RetinaFace: : Single-Shot Multi-Level Face Localisation in the Wild
RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild
(CVPR 2020)
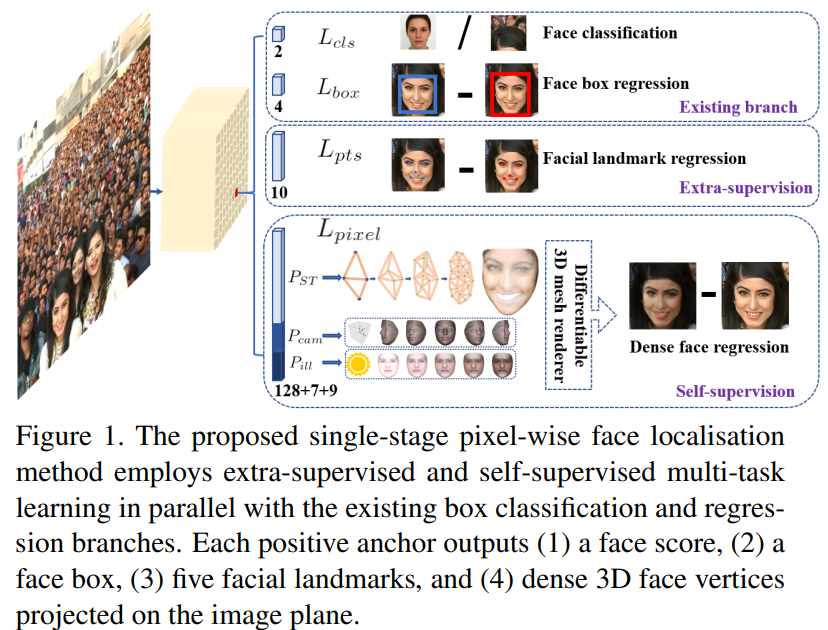
Abstract
Single stage 디자인으로새로운 pixel-wise face localisation 방법을 제시
Multi-task learning 을 이용하여 각 pixel에 대응되는 face score, face box, 5개의 facial landmarks, 3D position 를 예측
- 다양한 task의 loss를 이용하여 학습 진행
WIDER FACE hard 데이터에서 RetinaFace가 그 당시의 SOTA인 ISRN 보다 성능이 좋아짐
IJB-C 데이터셋에서 ArcFace의 face verification의 정확도를 높이는데 도움
- Face localisation 성능이 높아지면 face recognition 성능이 좋아짐을 확인
가벼운 backbone 모델을 사용하면서 VGA resolution 이미지가 Single CPU core에서 실시간으로 동작하는 것을 확인
Related works

Image Pyramid
이미지 해상도를 다르게 하여 피라미드 형태로 나타낸 것
이미지 피라미드를 학습하면 다양한 해상도의 이미지를 학습하기 때문에 다양한 크기의 물건 잘 인식
각 이미지 해상도 별로 prediction 과정을 진행한다는 단점
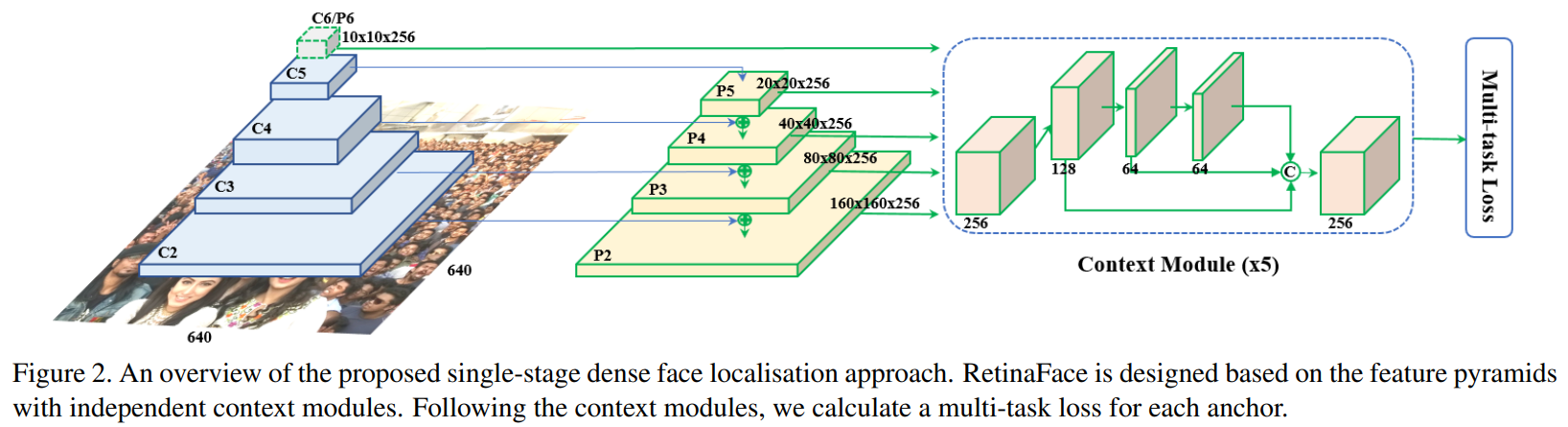
Feature Pyramid
위의 단점을 해결하기 위해 feature pyramid를 이용할 수 있음
한 번의 학습으로 각각을 prediction 진행 가능
Low-level 부터 high-level feature를 다 이용 가능
Context Modeling
다양한 feature를 input으로 받음
작은 얼굴도 잘 잡아 낼 수 있도록 모델의 contextual reasoning 키우는 역할
Deformable Convolution을 이용하여 진행
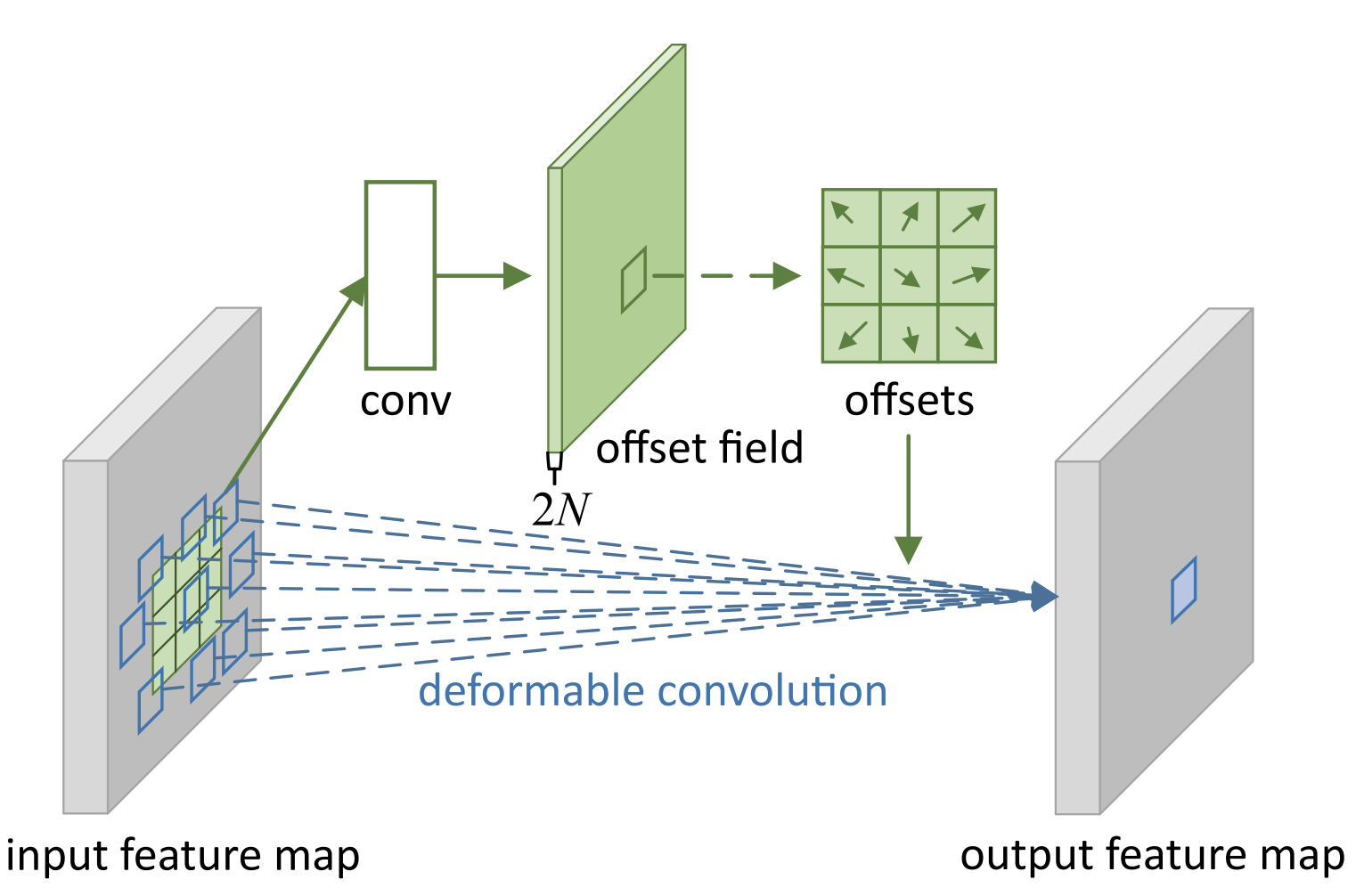
-
일반 convolution과 차이가 있음
-
일반적인 커널에 offset을 주어 convolution 연산을 진행
-
Receptive field가 더 넓어진다는 장점이 있음
Multi-task learning
Main task가 있다면 (여기서는 face detection) sub task를 추가하여 학습하여 main task도 학습이 더 잘 되도록 하는 방법
Mask R-CNN이 가장 대표적인 예시이고 main task인 object detection의 성능이 높이기 위해서 segmentation을 sub task로 이용
RetinaFace
Multi-task Loss
여러 loss의 합으로 구성이 되고 각 요소의 중요도 마다 $ \lamda $ 를 주어서 가중치를 줌
- Face classification loss $L_{cls}(p_{i}, p_{i}^{*})$
- 얼굴인지 아닌지 2개의 값으로 나타내어서
- Face box regression loss $L_{box}(t_{i}, t_{i}^{*})$
- 얼굴의 좌표 4가지를 이용하여 face box regression loss 계산
- Facial landmark regression loss $L_{pts}(l_{i}, l_{i}^{*})$
- Retina Face는 5개의 landmark를 구하고 그것에 따른 좌표 2개의 값, 총 10개의 좌표에 대한 loss function
- Dense regression loss $L_{pixel}$
- 3D mesh render에서 2D face로 regression 해주는 loss function
Dense Regression Branch
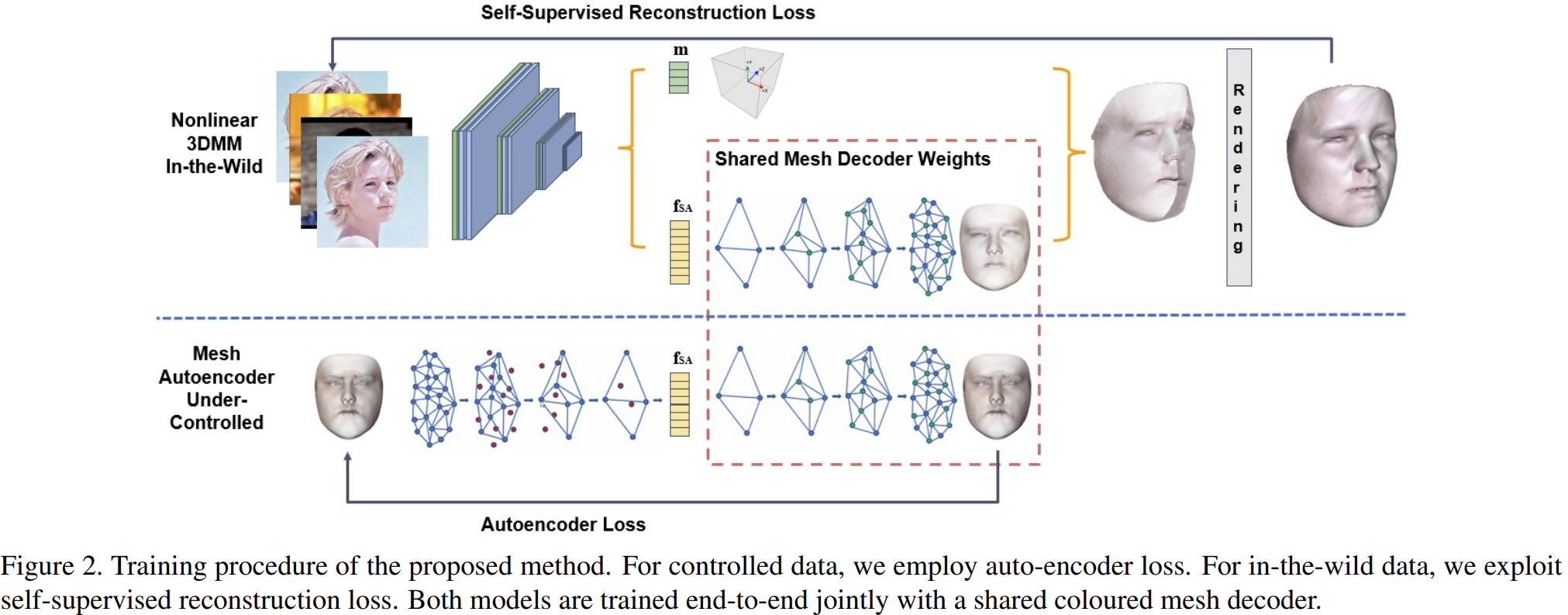
정답이 없는 set을 이용하여 reconstruction을 하는 task
Self-supervised Reconstruction Loss를 사용하여 학습
Experiments
Dataset : Wider Face
Face Detection Benchmark dataset
32,203 개의 이미지와 393,703개의 face box로 구성

Edge box라는 간단한 detection 모델을 사용해 confidence score 을 기준으로 데이터를 나눔
- Easy, Medium, Hard
Extra annotation 추가
- 5개의 landmark (눈, 코 , 입 가장자리)

Implementation details
-
Loss Head
Multi-task loss는 Positive anchor에만 적용
-
Anchor settings
Scale step은 $2^{\frac{1}{3}}$ 로 조절, Aspect ratio : 1
- 이미지 사이즈가 640 x 640 인경우에는 anchor가 16 x 16 ~ 406 x 406 까지 커버
- 총 102,300개의 anchor가 존재하고 이 중 75%는 P2에 존재
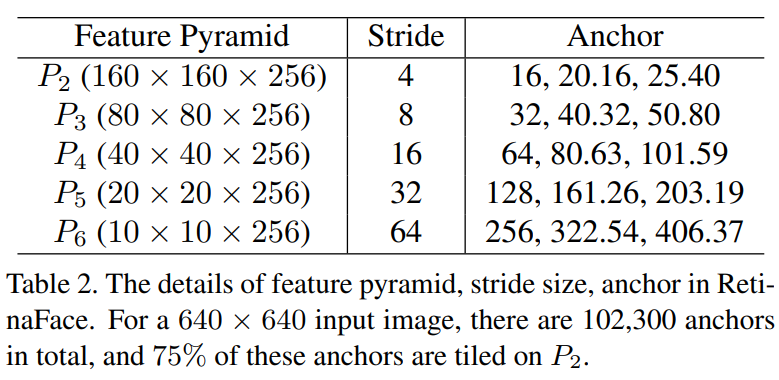
- Feature pyramid 별로 anchor size가 다르게 적용
Anchor와 ground-truth의 IOU가 0.5 이상이면 match , 0.3 미만이면 배경이라고 함
Match 되지 않은 anchor는 학습에서 제외
Anchor는 학습의 비율을 맞추기 위해 Positive : Negative 를 3 : 1로 맞춤
- OHEM (Online Hard Example Mining) 을 이용하여 맞춤
-
Data augmentation
Random crop
Horizontal flip
Photo-metric color distortion
-
Training
Optimizer : SGD
Momentum : 0.9
Weight decay :5e-4
Batch size : 8 x 4
Learning rate : 0.001
Epochs : 80
GPU : NVIDIA Tesla P40 (24GB) * 4
-
Testing
Flip
Multi-scale : [500, 800, 1100, 1400, 1700]
IoU : 0.4
Ablation Study
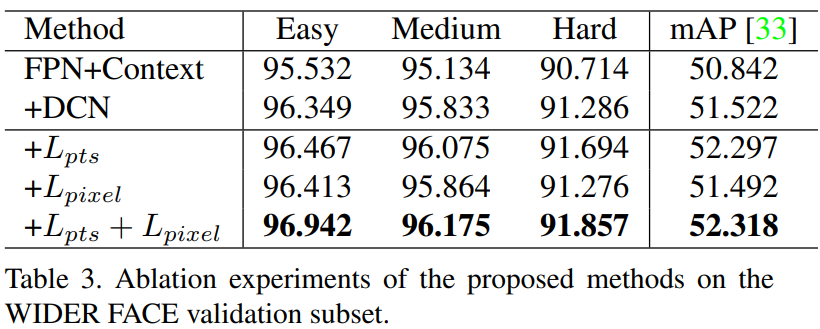
Face Recognition Accuracy
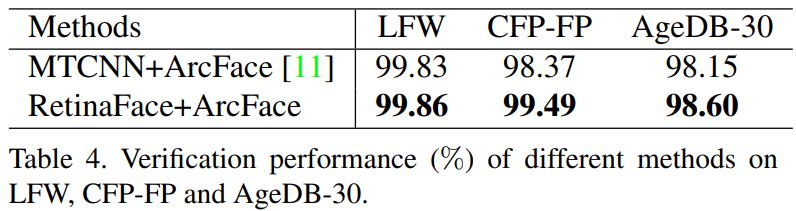
RetinaFace를 사용하는 경우 Face verification 정확도가 증가
Inference Efficiency
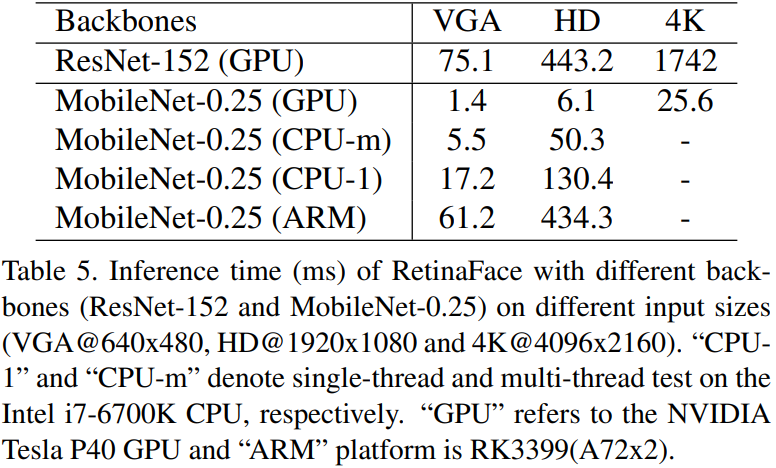
RetinaFace의 backbone과 Input Image의 화질에 따라 걸리는 시간
Conclusion
Wider Face 데이터에 5개의 추가적인 annotation을 넣어 학습을 하여 성능을 높임
Self-supervised branch를 추가해서 Face detection 성능을 높임
Wider Face hard set에서도 SOTA 정도의 성능을 보임
Face Verification의 성능을 높임
가벼운 backbone을 가지고 있어 single CPU core에석도 VGA 해상도 이미지에 대해서 실시간으로 추론이 가능
RetinaFace 코드 실행
Docker Image : pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel
GPU : NVIDIA GeForce RTX 4080 Laptop GPU
코드 : 깃허브 주소
- 공식 깃허브를 사용하지 않음
Training
Wider Face 데이터를 이용하여 학습 진행
Inference
-
Dlib

-
RetinaFace - CPU

-
RetinaFace - GPU

Inference 결과
Dlib으로 실행을 하면 CPU에서 진행하지만 FPS가 매우 빠르지만 Detection 정확도가 떨어짐
같은 CPU 환경에서 RetinaFace를 진행하면 속도는 느리지만 Detection 정확도가 매우 높은 것을 확인 할 수 있음
그렇지만 GPU에서 진행을 하면 지금 내가 실행한 코드에서는 병목현상이 발생하는지 매우 느려지는 것을 확인
이미지가 GPU에 올라가는 중에 생기나..? 수정 후 확인해야 할 듯