PointNet
참고
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
CVPR 2017
Introduction
기존 Convolution 구조를 가지는 딥러닝 방법론은 이미지와 3D voxel과 같은 정규적인 (regular) 데이터 구조를 입력으로 가짐
하지만 대표적으로 활용되는 3차원 데이터의 구조인 point cloud나 mesh는 정규적이지 못한 구조를 가짐
Point cloud를 적용하기 딥러닝 구조의 입력으로 사용하기 위해 기존의 연구들은 정규적인 데이터 형태인 이미지의 모음이나 3D voxel로 변환하는 과정을 거침
이 과정에서 데이터는 불필요한 empty space 가지게 되고 또한 quantization artifact가 발생함
이를 위해 point cloud를 사용하는 새로운 네트워크인 PointNet 구조를 제시
Point cloud의 unordered한 특징과 permutation invariant한 특성을 유지할 수 있도록 네트워크가 고안됨
- Permutation invariant는 각 요소가 어떤 순서로 데이터가 구성이 되어도 그 형태 등의 특징은 동일하다는 특징
PointNet은 입력으로 point cloud를 직접적으로 사용하는 통합된 구조
초기 단계 (stage) 에서 각 point들은
또한 CNN과 RNN과 같은 구조는 permutation invariant 하지 못함
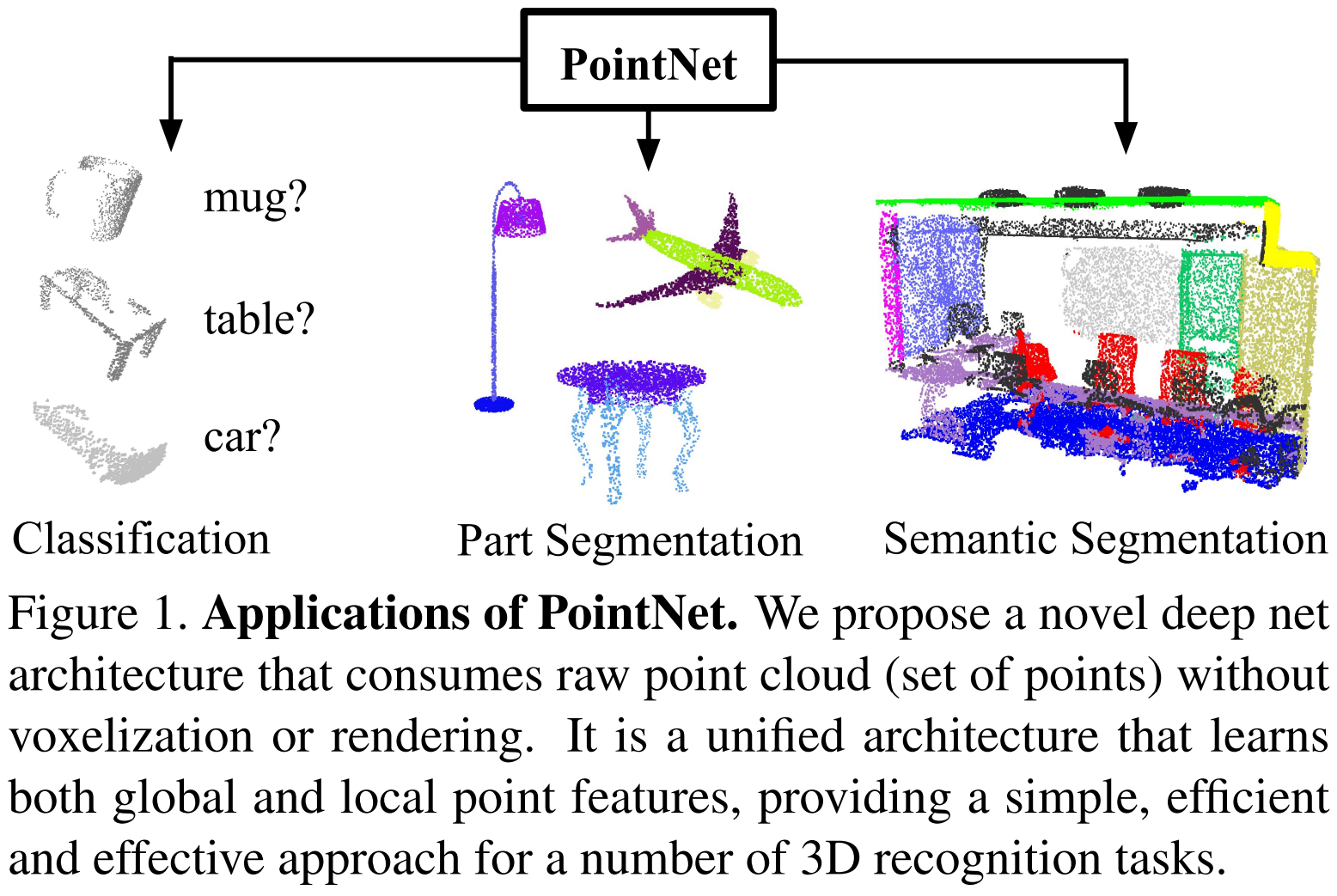
이 논문에서는 unordered한 point cloud를 별도의 전처리 없이 입력으로 사용하여 classification이나 segmentation 결과를 출력으로 하는 Pointnet 구조를 제안함
Problem statement
Unordered point set을 직접적으로 입력으로 사용하도록 모델 디자인
\[\{P_{i}|i=1, ..., n\}$\]각 포인트 클라우드 $P_{i}$는 3차원 위치인 $(x, y, z)$로
Classification
-
input : shape에서 직접적으로 sampling 되거나 scene point cloud에서 pre-segmentation된 point cloud 사용
-
output은 : class에 대한 k score
Segmentation
- output : $n\times m$ score의 output
- 각 $n$ point에 대한 $m$개의 semantic sub class
Deep Learning on Point Sets
Properties of Point Sets in $ \mathbb{R}^{n}$
- Unordered
- 특정 순서를 가진 데이터가 아님
- 최악의 경우 $N$개의 point가 있는 경우 $N!$ 입력이 data feeding으로 요구됨
- Interation amoing points
- Point는 독립적이지 않음
- 전체의 point가 하나의 shape를 갖기 욌다면 인근 위치의 포인트끼리는 유사한 정보를 가짐
- 이런 특성을 이용하여 local structure을 알아냄
- Point는 독립적이지 않음
- Invariance under transformations
- 특정 Transformation가 적용되더라도 object 자체가 변화하지 않음
- 모든 point에 대하여 rotation, translation이 적용되더라도 딥러닝 결과 (category, segmentation)에 변화를 주지 않음
PointNet Architecture
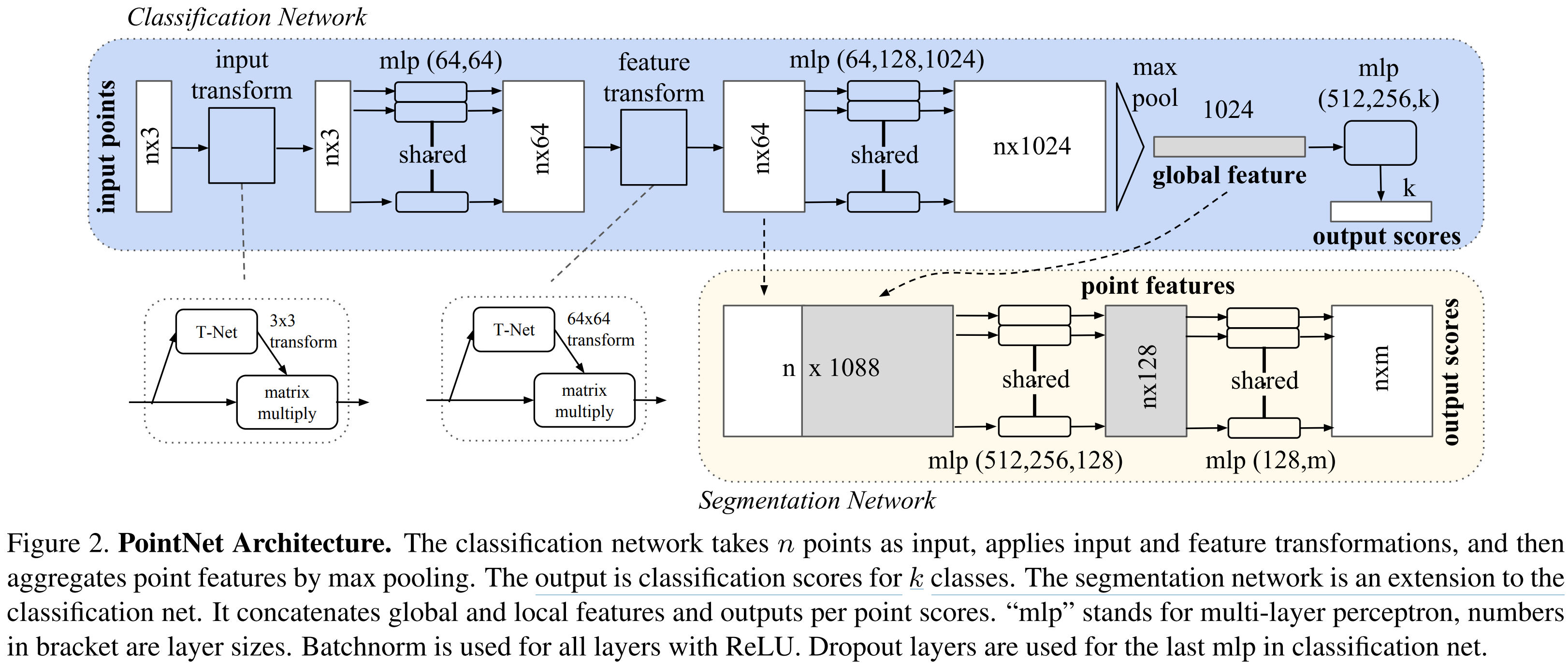
Classification 네트워크와 Segmentation 네트워크로 구성
3개의 중요한 모듈 존재
- Max pooling layer
- 모든 point들의 정보를 합치는 (aggregation) Symmetric function
- Combination structure
- 지역적 전역정 정보 조합하는 구조
- Alignment Network
- 입력 point와 point feature를 정렬하는 2개의 네트워크
Symmetry Function for Unordered Input
Permutation invariant를 유지하기 위함
3가지 전략을 적용
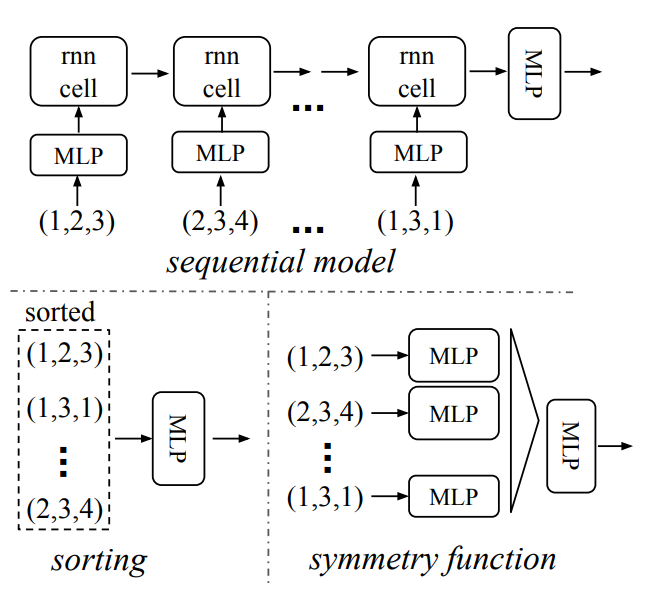
-
입력 정렬
- 고차원 데이터 공간에서는 point data에 작은 변화를 주는 것에도 안정적일수 없음
- 입력에 대한 데이터와 정렬된 결과가 일대일 대응이 가능하다는 것을 보장하기가 어려움
-
RNN 활용
- 짧은 길이의 입력에 대해서는 순서에 불변하게 좋은 결과가 나오지만 데이터의 길이가 길어지면 순서 영향 받음
- Pointcloud는 많은 입력이 들어올 수 있어 부적합
-
Symmetry function
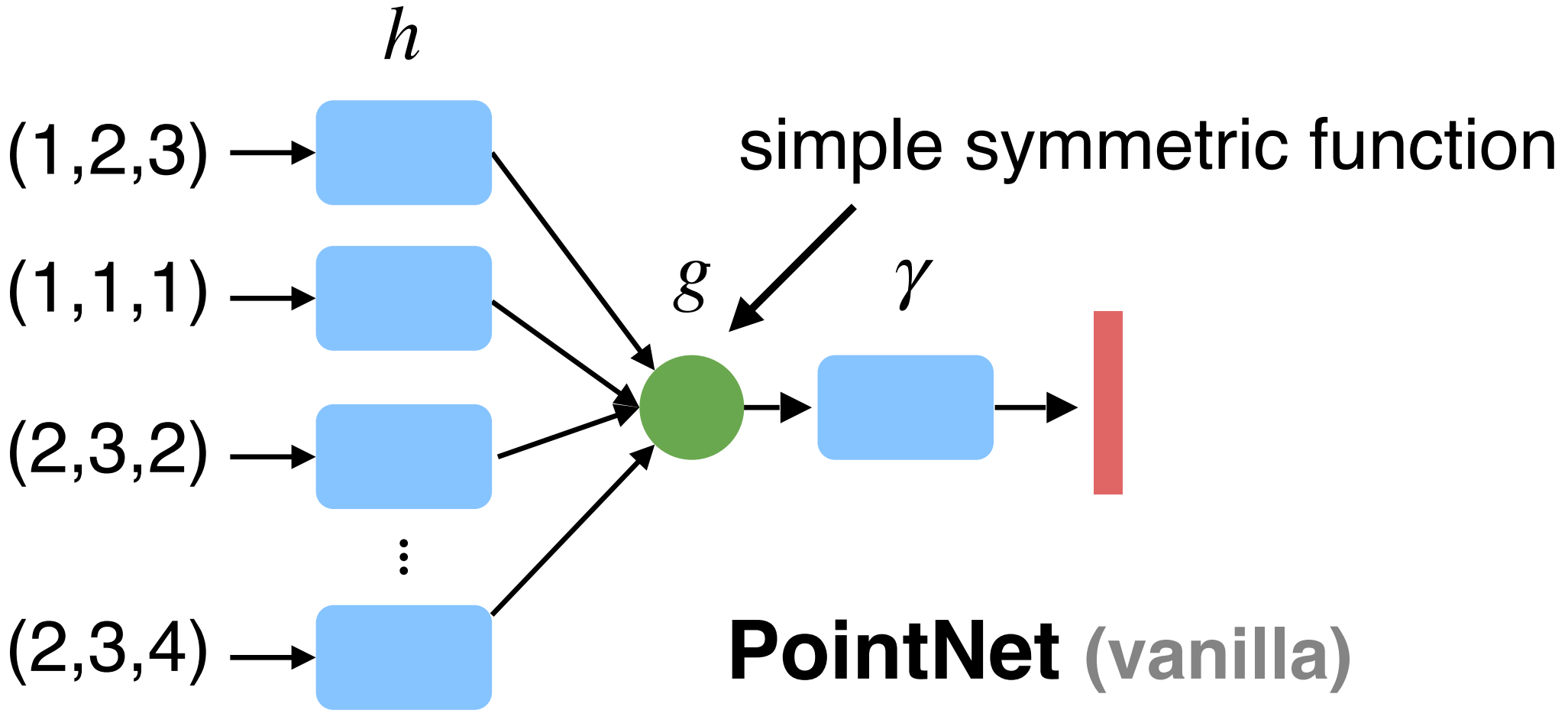
출처 - Symmetry function은 들어오는 입력 변수의 순서에 상관없이 동일한 출력값이 나올 수 있도록 하는 함수
- Point 입력을 근사화 할 함수를 MLP 네트워크로 도출 ($h$)
- Symmetry function ($g$) 입력은 근사화 함수로 나온 결과
- 실험 결과를 바탕으로 Symmetry function은 Max pooling
Local and Global Information Aggregation
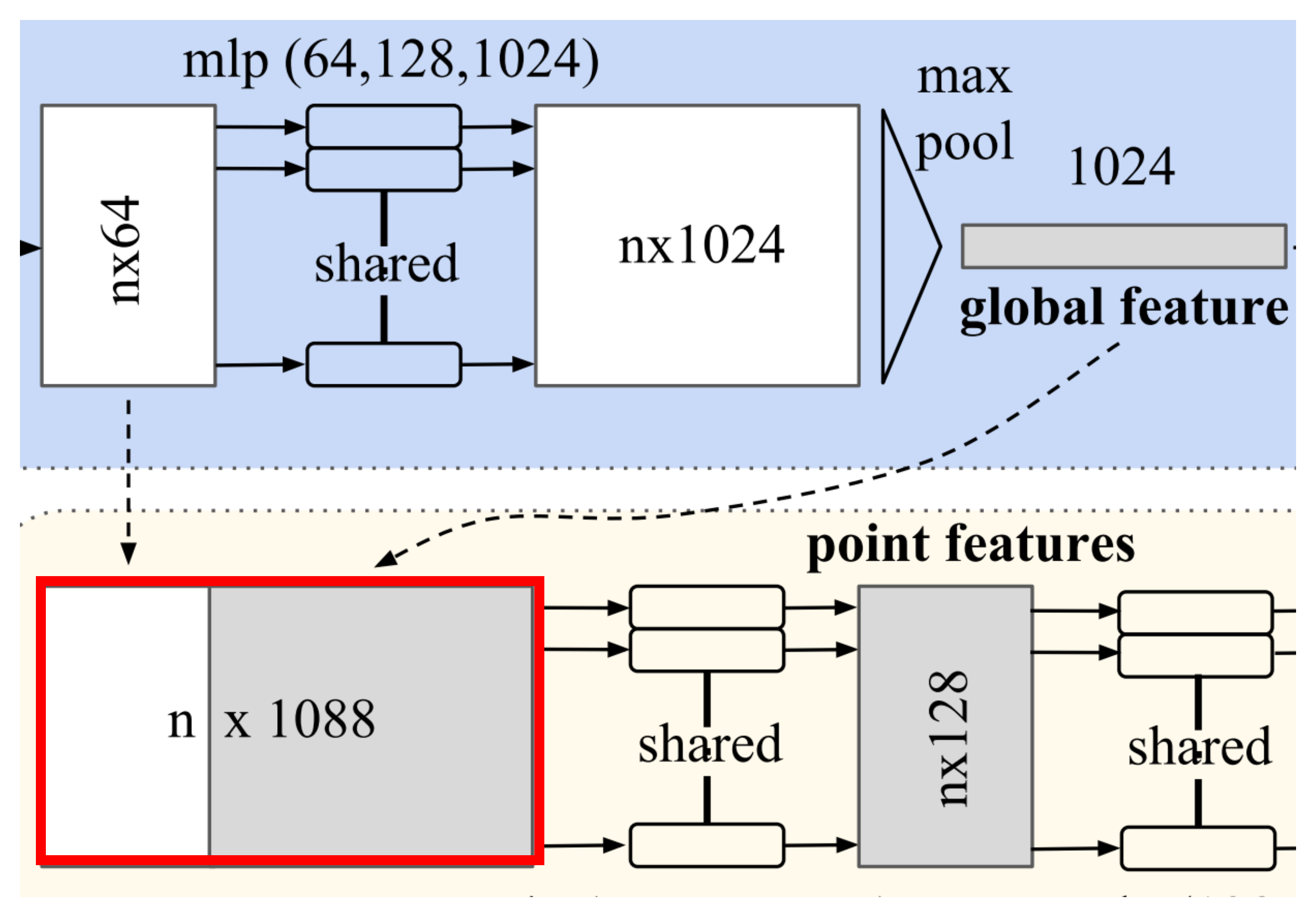
Joint Alignment Network
Point cloud의 Semantic labeling은 특정한 transform을 적용하더라도 invariant 해야 함
기존에는 특징 추출 전 표준 공간에 정렬하는 방법 사용
PointNet에서는 작은 네트워크인 T-Net을 학습하여 Affine transformation matrix를 추정
- 입력 데이터를 표준 공간으로 보내기 위해 적용되어야 하는 matrix
입력 point에 적용할 transformation을 추정하는 역할이나 feature에 적용할 transformation 추정도 가능
하지만 네트워크 후반부에 넣으면 높은 차원의 feature를 transform 할 정보 추정해야 하므로 최적화가 어려워짐
Regulation term을 손실 함수에 추가 시켜 학습
\[L_{reg}=||I-AA^{T}||^{2}_{F}\]Transformation matrix $A$를 orthogonal matrix가 되도록 학습
Theoretical Analysis
Universal approximation
입력 point의 작은 변동이 classification, segmentation 결과에 큰 영향을 주지 않음
(더 자세한 내용은 다음에 추가.. )
Bottleneck dimension and stability
입력 point에 잡음이 추가되거나 변형되어도 네트워크 출력값에 큰 영향을 미치지 않음
PointNet은 point cloude의 shape 정보를 잘 요약할 수 있음
Experiment
Applications
3D Object Classification
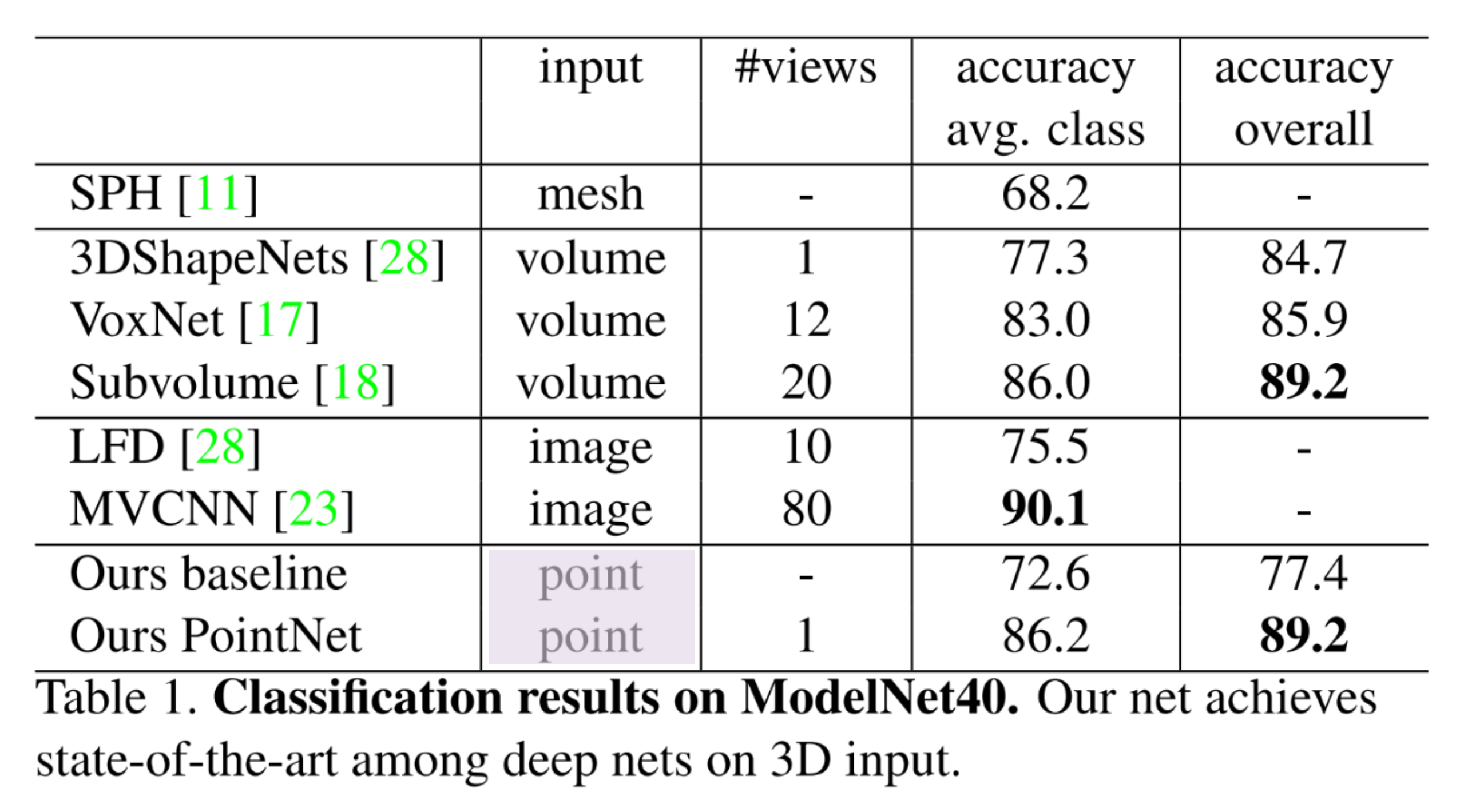
FC layer와 Max pooling 조합만으로 논문이 나올 당시 SOTA 성능
80개의 view point를 projection하는 MVCNN과 달리 point를 입력 자체로 사용했기 때문에 burden을 줄임
3D Object Part Segmentation
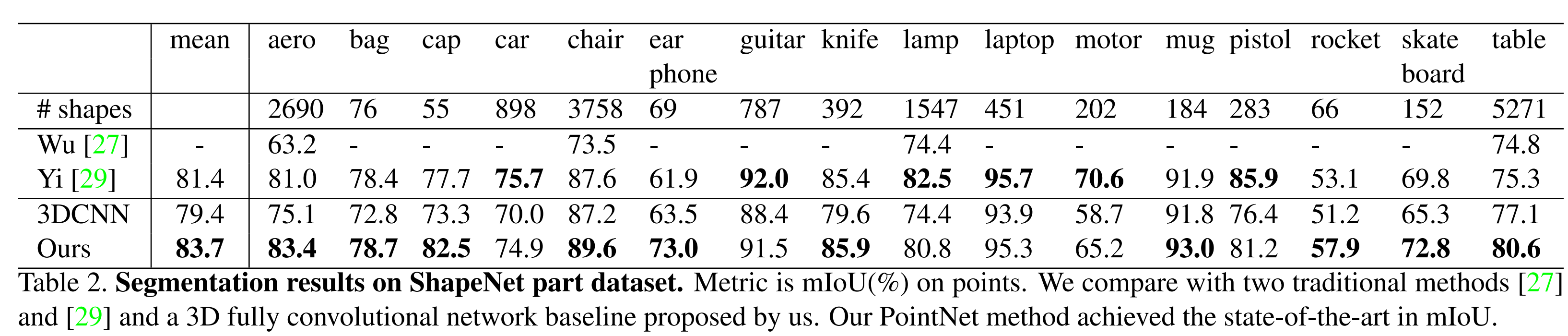
카테고리 별 평균 IoU 값이 높음
ShapeNet 데이터셋을 사용했을 때 안정적인 결과 얻음
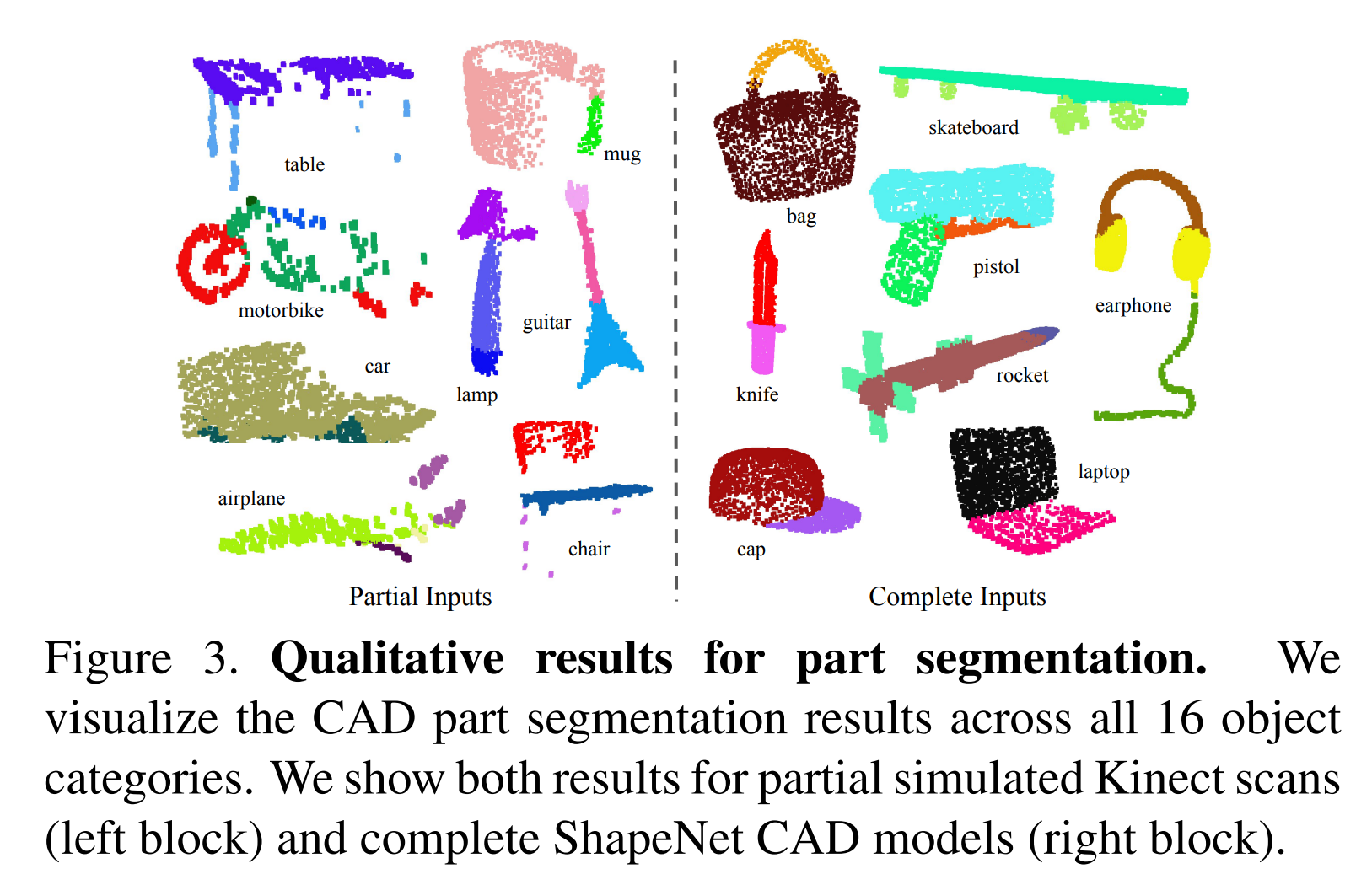
Semantic Segmentation in Scenes
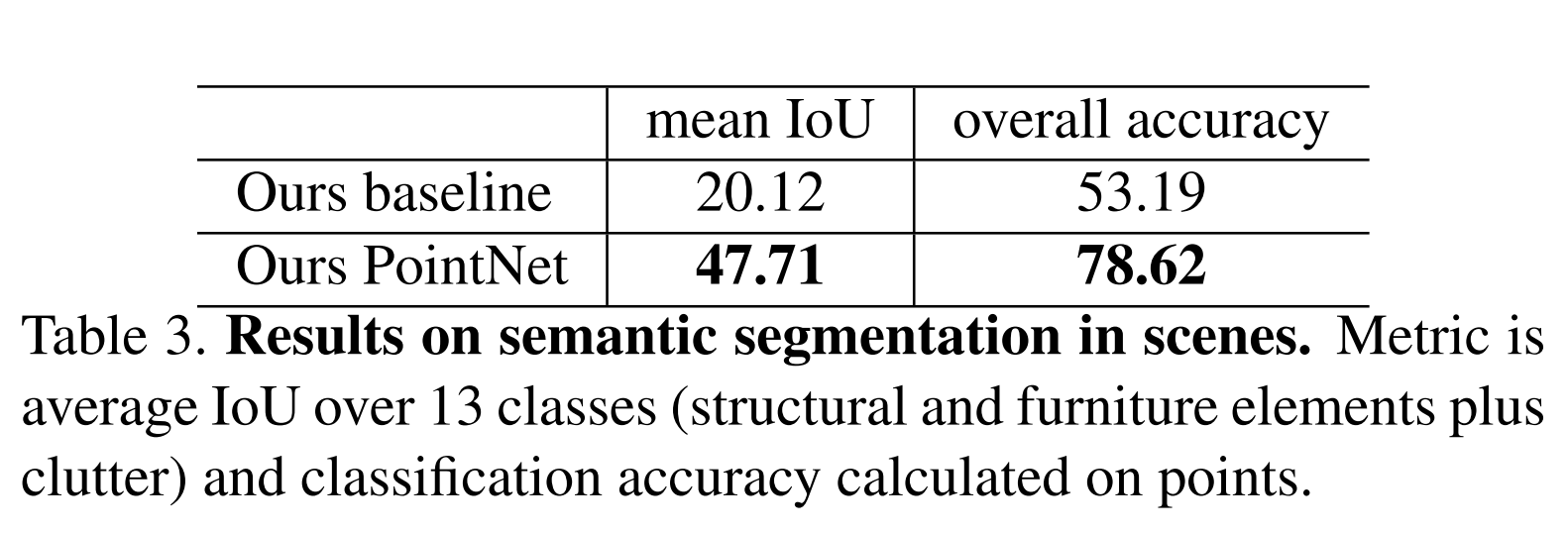
기존 basline 모델에 비해서 높은 성능 향상
이 모델을 backbone으로 사용하면 좋은 3D object 성능 획득할 수 있을 것

Architecture Design Analysis
Comparison with Alternative Order-invariant Methods
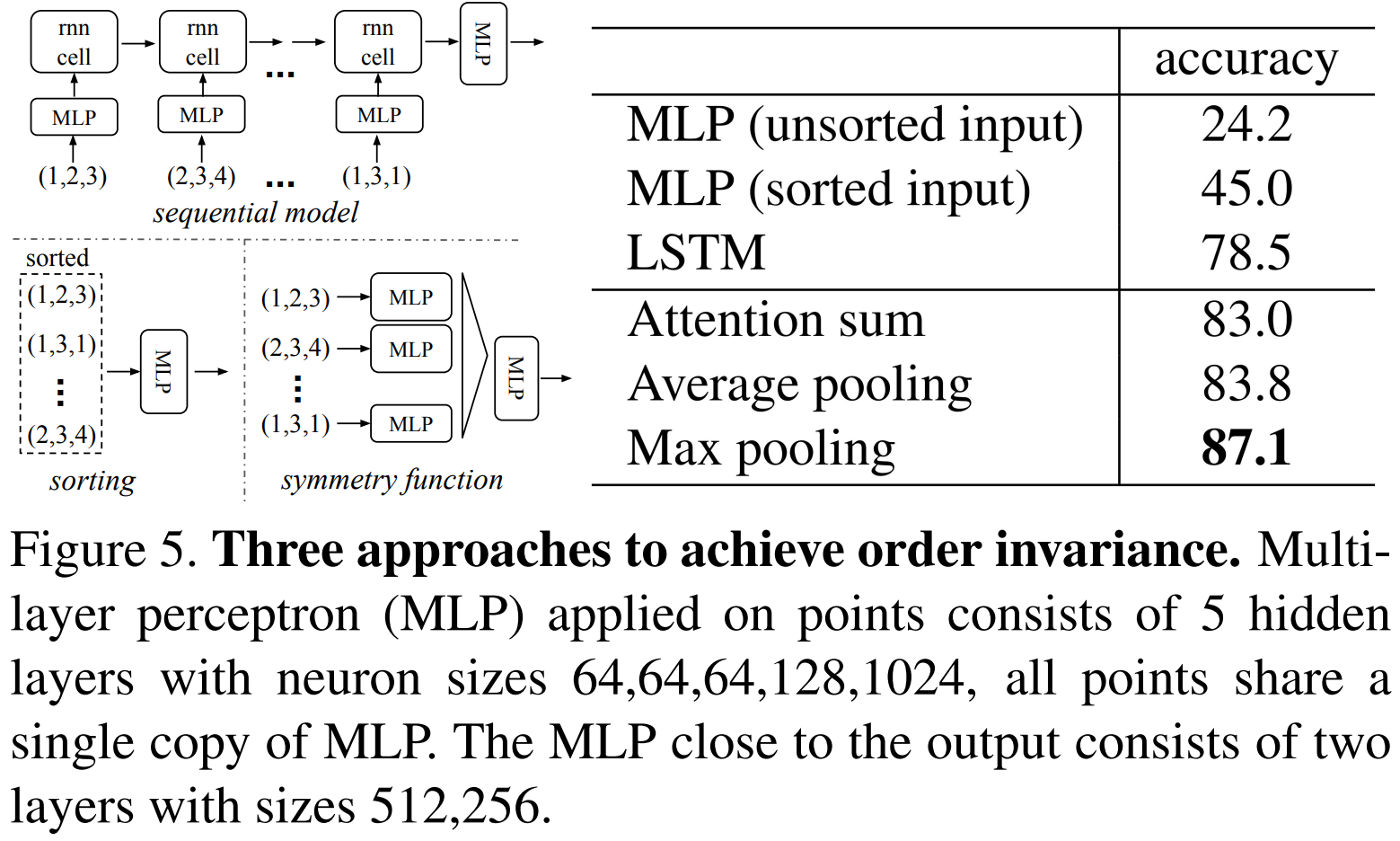
입력을 정렬하거나 LSTM을 적용하는 경우에도 성능이 향상
하지만 Symmetry function, 특히 Max pooling을 적용하는 경우 가장 높은 성능 변화를 보임
Robustness
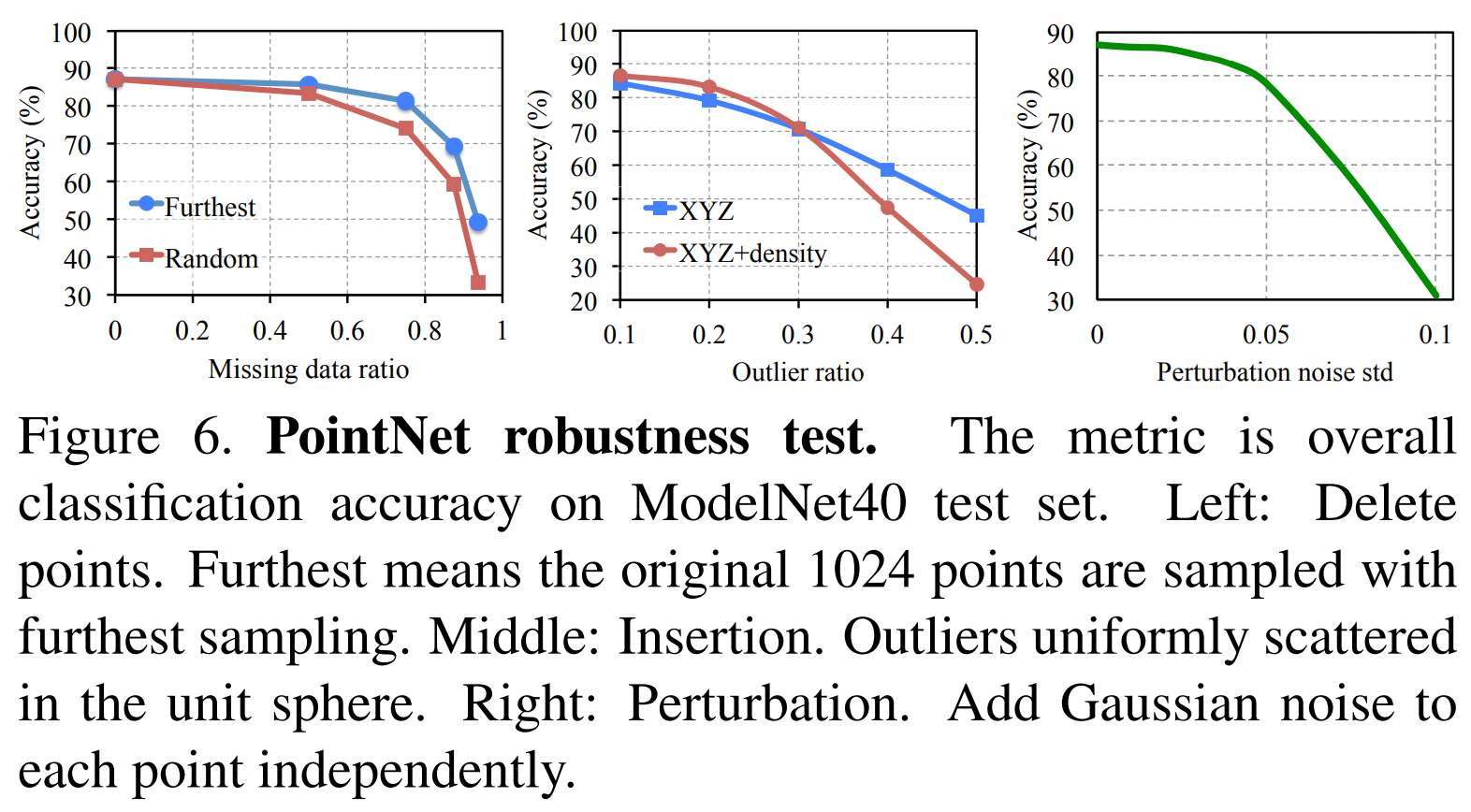
유실 데이터가 많아도 다른 모델에 비해서 정확도가 크게 떨어지지 않음
잡음이나 약간의 변동이 있더라도 어느 정도 성능이 유지됨
Conclusion
Point cloud를 직접적으로 사용할 수 있는 PointNet 네트워크 제안
다양한 3D recognition taskㅇ에 대한 결과 도출
기존 방법보다 좋은 결과 제시
이해를 위한 이론적 분석과 시각화 자료 제시
참고
- https://stanford.edu/~rqi/pointnet/docs/cvpr17_pointnet_slides.pdf
- https://ganghee-lee.tistory.com/50