PV-RCNN
참고
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
CVPR 2020
Introduction
LiDAR에서 rregular하고 sparse 한 point cloud 를 획득 가능
Irregular한 point cloud에서 더 좋은 3D feature를 얻을 수 있는 voxel-point를 결합한 새로운 네트워크를 제시
기존에 존재하는 3D object detection은 point cloud representation에 따라 2가지로 나뉨
- Grid-based method
- Irregular한 point-cloud 데이터를 regular한 데이터 형식으로 바꿈 (voxel, 2D bird’s view )
- 3D 또는 2D convolution 이용하여 3D detection을 위한 feature 학습
- 계산 효율성이 좋지만, regular하게 만드는 과정에서 불가피하게 정보손실이 발생
- Point-based method
- 3D object detection을 위해 raw point cloud에서 직접적으로 feature 추출
- 계산 비용이 높지만 pount 집합 추상화ㄹ에 의해 더 큰 receptive field를 가져 feature를 잘 획득
위의 두 가지 방법의 장점을 합쳐 기존 3D object detection 성능을 능가하는 통합된 framework 제공
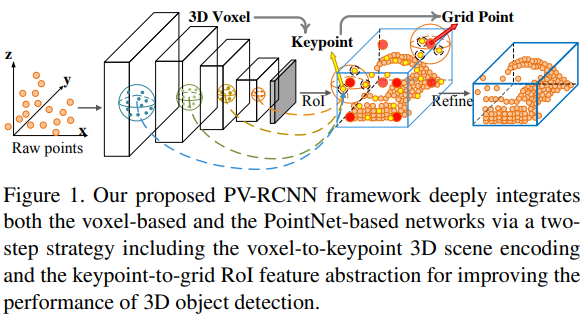 }{:.img-display-60}
}{:.img-display-60}
Point-based 와 Voxel-based feature 학습 방법의 장점을 합친 PV-RCNN (Fig 1.)이라는 새로운 네트워크 제시하여 3D detection의 성능을 높임
Voxel-based dustksdms 효과적으로 multi–scale feature를 만들 수 있고 고품질의 3D proposal 생성 가능
PointNet 기반의 set abstraction 연산은 유연한 receptive field로 정확한 위치 정보를 보존 가능
두 가지 feature 학습 방법을 이용하여 정확하고 fine-grained한 box 정제를 가능하게 하는 discrimitive feature 학습이 가능
3D voxel CNN과 PointNet기반의 set abstarction 을 어떻게 효과적으로 합치는지가 주요 과제
2가지 유형의 point cloud featrue 학습 네트워크를 잘 통합하기 위해서, 2 step 전략을 취함
- Voxel-to-keypoint scene encoding
- Keypoint-to-grid Roi feature abstraction
3D sparse convolution을 가진 voxel CNN을 사용하여 voxel-wise feature를 학습하고 정확한 proposal을 생성
전체 장면을 인코딩하기 위해서 너무 많은 voxel이 필요하다는 단점을 완화하기 위해 FPS (Furtherest Point Sampling) 을 이용하여 작은 keypoint들의 집합을 선택하여 voxel-wise feature에서 전체적인 3D 정보 요약
Multi-scale point cloud 정보를 요약하기 위해서 PointNet-based set abstraction을 통해 인접한 voxel-wise feature들을 그룹화하여 각 keypoint들의 특징을 합침
이런 방법을 통해 multi-scale feature와 연관된 적은 수의 keypoint를 이용하여 전체적인 scene을 효과적이고 효율적으로 인코딩 가능
Keypoint-to-grid RoI feature abstraction 과정에서는, Grid point위치가 있는 각 box proposal에서 RoI-grid pooling module이 제안됨
다양한 반지름을 가지는 keypoint set abstraction layer를 사용하여 각 grid point들이 multi-scale feature context를 가지를 keypoint들에서 얻은 feature들과 합쳐짐
모든 grid point들의 합쳐진 feature들은 다음 proposal refinement에 공동으로 사용 가능
Contribution은 4가지로 정리 가능
- voxel-based와 point-based의 3D point cloud feature 학습 방법에 대한 장점을 효과적으로 획득
- 매모리 사용을 관리할 수 있도록 하여 성능 향상
- Voxel to-keypoint scene encoding 에서는 voxel set abstraction layer을 이용하여 전체scene의 multi-scale voxel feature들을 작은 keypooint 집합으로 인코딩
- Keypoint feature들은 정확한 위치 정보 보존하고 풍부한 scene context를 인코딩하여 성능 향상
- 각 proposal의 grid point들에 multi-scale RoI feature abstraction layer 적용
- 정확한 box refinement와 confidence 예측을 위해 multiple receptive field를 가지는sceneㅇdptj 풍부한 context 정보를 얻어 합침
- 기존의 방법보다 성능이 뛰어남
PV-RCNN for Point Cloud Object Detection
2 stage의 3D object detection 방법인 PointVoxel-RCNN (PV-RCNN) 제시
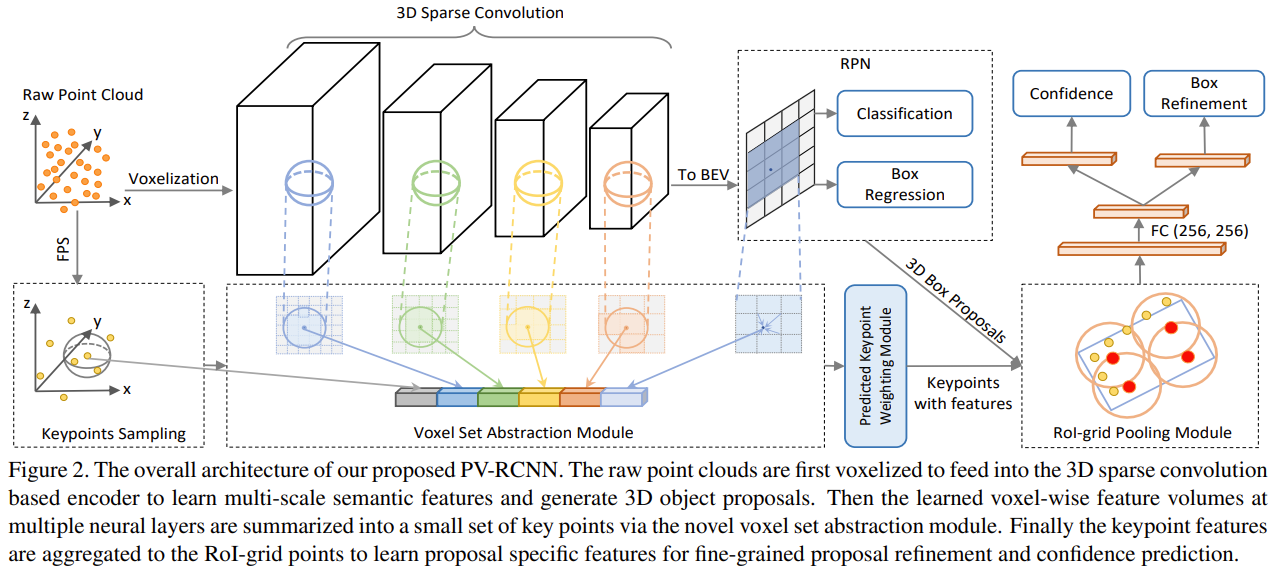
3D Voxel-CNN과 PointNet 기반의 알고리즘의 장점을 합침
Sparse convolution을 적용한 3D voxel CNN을 backbone으로 사용하여 효과적으로 feature를 인코딩하고 proposal을 생성
앞서 생성한 3D object proposal을 고려하여 , Scene에서 대응되는 feature를 효과적으로 pool 하기 위해서 2개의 새로운 연산 제시
- voxel-to-keypoint scene encoding
- e point-to-grid RoI feature abstraction
3D Voxel CNN for Efficient Feature Encoding and Proposal Generation
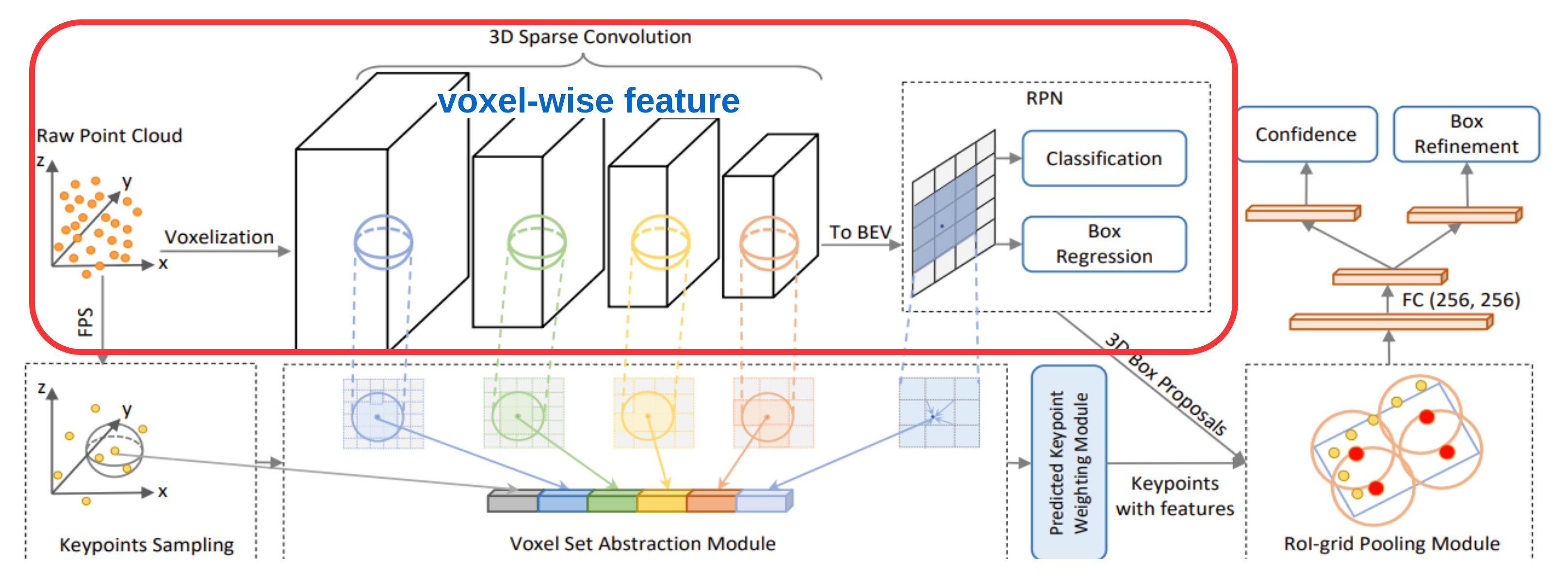
3D voxel CNN
입력 Point cloud $\textbf{P}$ 들은 처음에 $L\times W\times H$의 공간적인 해상도를 가지는 작은 voxel들로 나눠짐
Non-empty voxel의 feature들은 모든 포인트들의 point-wise feature의 평균으로 계산
- 주로 사용하는 feature들은 3D 좌표들과 reflectance intensities
Network는 $3\times 3\times 3timse$ 3D sparse convonlution을 이용하여 feature volume을 $1\times, 2\times, 4\times, 8\times$로 downsampling
각 level에서의 sparse feature volume을 voxel-wise feature vector 들의 집합이라고 할 수 있음
3D proposal generation
8배 downsampling 된 3D feature volume을 2D bird-view feature map으로 변환
- 3D feature volume을 $Z$ 축을 기준으로 stack 하여 생성
이를 입력으로 anchor-based 방법 이용하여 고품질의 3D proposal 생성
- 각 feature map pixel 마다 orientation이 (0, 90도)인 2개의 anchor
- 각 anchor가 object 유무에 대한 classification, box regression 진행
Discussion
SOTA 모델 대부분의 detector는 2-stage 방식을 채택하고 proposal refinemet를 위해 3D feature volume이나 2D map에 ROI polling을 진행
하지만 이러한 3D voxel CNN featrue에는 크게 2가지 문제점 존재
- 3D convolution을 통해 해상도가 8배 낮아져 input scene에서 정확한 위치 찾기 힘듦
- Upsampling을 통해 해상도를 높이더라도, sparse 함
- ROIPolling/RoIAlign 연산을 위해서 interpolation을 이용하는데 주변의 적은 수의 이웃들을 가지고 feature를 추출하여 전체적인 context 정보 알기 힘듦
다양한 PointNet에서 제시한 set abstraction 방법을 이용하면 적은 수의 매우 넓은 receptive field를 가지기 때문에 정확하고 robust한 refinement 가능하게 함
이를 위해 3D voxel CNN과 set abstraction 연산을 합침
Set abstraction 연신을 scene feature voxel을 pooling 하기 위해 사용하는 것은 사용하는 것은 상당히 많은 메모리를 차지하여 실제로 사용하기 비효율적
- set abstraction 연산은 모든 distance-pair를 계산해야 함
이 문제를 해결하기 위해 2 step의 방식 사용 (다시 확인)
- 전체 scene의 서로 다른 neural layer에서 voxel을 소수의 keypoint로 인코딩
- box proposal refinemet를 위해 Roi grid에 keypoint feature 통합
Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
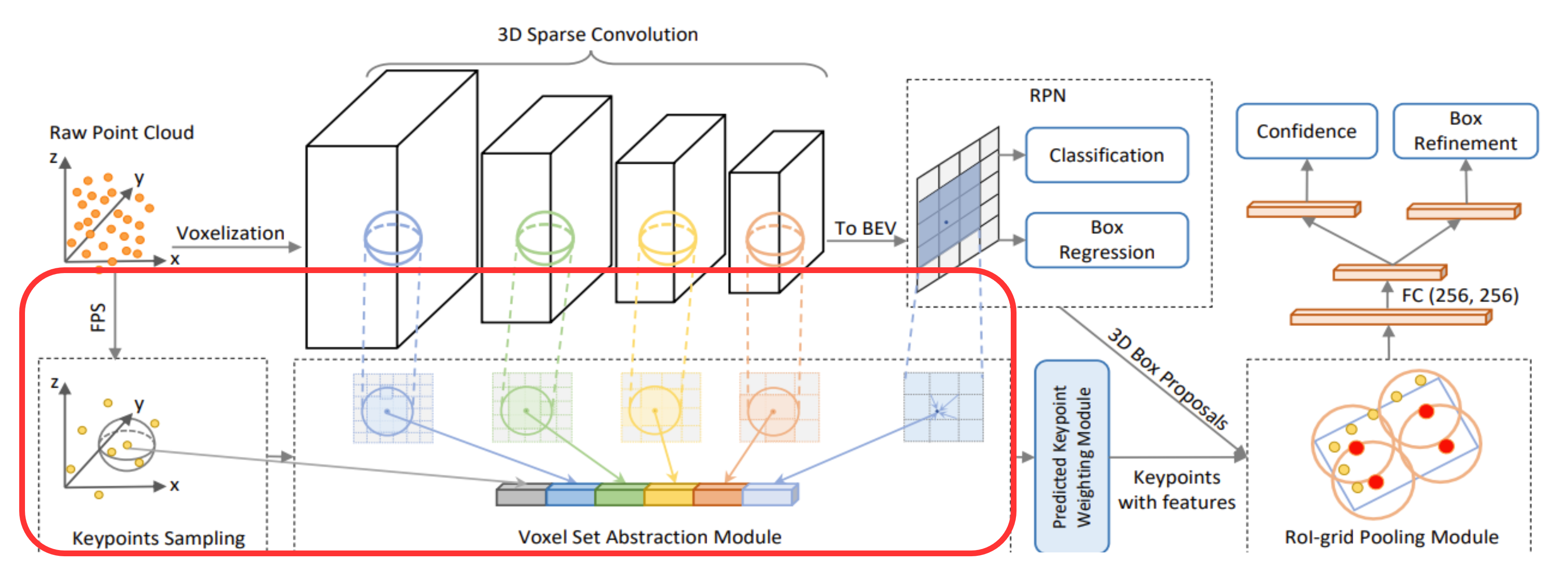
Keypoints Sampling
FPS (FurthestPoint-Sampling) 알고리즘을 건택하여$\textbf{P}$의 cloud pointdptj $n$개의 keypoint $K$를 선택
이를 통해 keypoint들이 non-empty voxel에 uniform하게분포하도록 하고 전체 scene을 대표할 수 있도록 함
Voxel Set Abstraction Module
3D volume에서 얻은Multi-scale semantic features를 keypoint로 인코딩하기 위해 VSA (Voxel Set Abstraction) moudle 제안
Set abstraction 연산은 voxel-wise feature를 합치기 위해 사용
$k$ 번째 3D voxel CNN level에서의 voxel-wise feature 집합은 다음과 같이 표현
\[F^{(l_{k})}=\{f_{1}^{(1_{k})}, ..., f_{N_{k}}^{(1_{k})}\}\]- $N_{k}$ : $k$번째 level의 non-empty voxel의 개수
$k$ 번째 level에서의 voxel indices와 실제 voxel 크기로 계산된 좌표
\[V^{(l_{k})}=\{v_{1}^{(1_{k})}, ..., v_{N_{k}}^{(1_{k})}\}\]각 keypoint $p_{i}$에 대하여 $k$ 번재 level에서 정해진 반지름 $r_{k}$내에 있는 non-empty voxel에 대하여 voxel-wise feature 획득
local의 상대적인 좌표인 $v_{j}^{(l_{k})}-p_{j}$ 와 상대적 위치에 대한 semantic voxel feature $f_{j}^{(1_{k})}$ 을 concat
이웃한 voxel 에 있는 voxel-wise feature 집합을 $S_{j}^{(l_{k})}$
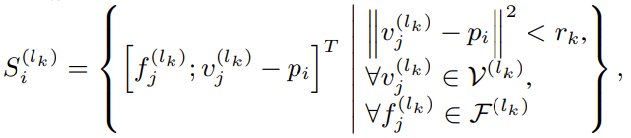
이렇게 얻은 $S_{i}^{(l_k)}$ 집합을 PointNet block을 통과시켜 keypoint $p_{i}$에 대한 feature 생성
아래는 PointNet block 진행 과정을 보여줌
\[f_{i}^{(pv_{k})}=max\{G(M(S_{i}^{(l_{k})})) \}\]- $M(\cdot)$ : Random sampling
- 최대 $T_{k}$ 개 만큼 random sampling 하여 계산량 줄임
- $G(\cdot)$ : Multi-layer perceptron
- Voxel-wise feature와 상대 좌표를 인코딩하기 위함
- $max{\cdot}$ : Max pooling
위와 같은 voxel set abstraction 과정은 3D voxel CNN의 서로 다른 level에서 진행이 되고 각각 다른 level에서 얻은 feature들을 합쳐 keypoint $p_{i}$에 대한 multi-scale semantic feature 생성
\[f_{i}^{(pv)} = [f_{i}^{(pv_{1})}, f_{i}^{(pv_{2})},f_{i}^{(pv_{3})},f_{i}^{(pv_{4})}], \ \ for \ i=1,...,n\]Extended VSA Module
Keypoint feature를 풍부하게 하기 위해서 raw point cloud 와 8배 downsampling 된 bird-view feature map을 추가
Raw point cloud는 voxelization 과정 중 발생한 quantization loss 복구해주고 2D bird-view map은 $Z$ 축에 대한 receptive field를 확장해줌
따라서 $p_{i}$에 대한 keypoint feature는 다음과 같이 구성됨
\[f_{i}^{(p)} = [f_{i}^{(pv)}, f_{i}^{(raw)}, f_{i}^{(bev)}], \ \ for \ i=1,...,n\]Predicted Keypoint Weighting
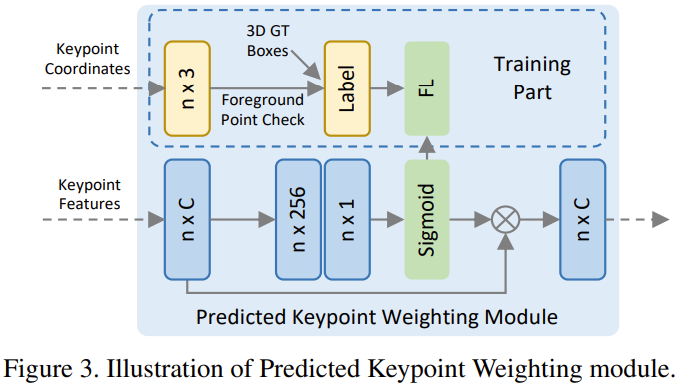
FPS 로 선택된 keypoint 중에서 background region을 나타내는 point 존재
Foreground keypoint가 refinement과정에서 background keypoint보다 더 많은 기여를 하도록 해야함
이를 위해 Fig 3. 에서 보여주는 것과 같은 Predicted Keypoint Weighting (PKW) module 적용
Point cloud segmentation 결과로 추가적인 supervision으로 부여하여 keypoint feature 에 가중치 부여
- Background , foreground segmentation
Segmentation label없이 ground truth 3D box 내부의 point는 foreground, 외부의 point는 background labeling 하여 학습
실제 동작시 학습된 네트워크를 통해 foreground confidence를 keypoint feature 에 곱해줌으로써 foreground인 keypoint가 refinement에 영향을 더 줄 수 있도록 함
\[\tilde{f}_{i}^{(p)}=A({f}_{i}^{(p)})\cdot f_{i}^{(p)}\]- $A(\cdot)$ : 3개의 MLP layer와 sigmoid 함수
- Foreground confidence 계산
학습시 focal loss를 통해 데이터 분포가 unblanced한 문제를 해결
Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
3D proposal을 3D RoI라 함
RoI-grid Pooling via Set Abstraction
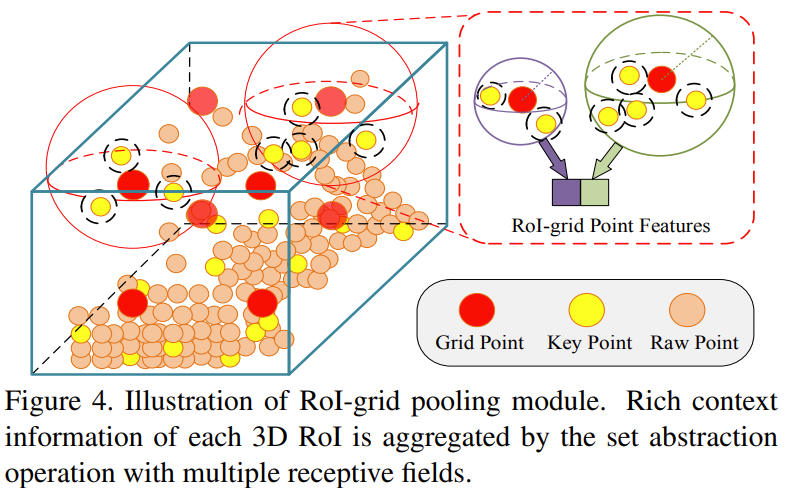
각 3D proposal을 $6\times 6\times 6$ 개의 grid point로 나눔 \(G=\{g_{1}, ..., g_{216}\}\)
Grid point $g_{i}$에서 반지름 $\tilde{r}$ 내에 존재하는 이웃하는 keypoint들에 대한 상대적인 위치 $p_{j}-g_{i}$와 keypoint $p_{j}$에 대한 feature $\tilde{f}_{j}^{(p)}$ 를 concate하여 이웃한 keypoint feature 집합 생성
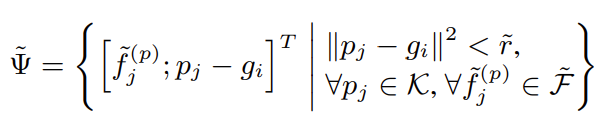
Neighbor keypoint feature 집합인 $\tilde{\Psi}$ 를 합치기 위해 PointNet block을 적용
아래는 PointNet의 과정을 보여줌
\[\tilde{f}_{i}^{(g)}=max\{G(M(\tilde{\Psi})) \}\]이 연산 후 grid point feature 획득
다양한 receptive field의 keypoint feature를 합치기 때문에 multi-scale의 context 정보 획득 가능
위의 과정을 통해 얻은 grid point feature들은 2개의 MLP를 통해 256 차원을 가지는 RoI feature vector 생성
3D Proposal Refinement and Confidence Prediction
2개의 branch로 구성
첫 번째는 confidence prediction branch
3D RoI 사이의 3D IoU를 채택하여 confidence 계산
$k$ 번째 3D RoI에서 confidence 는 아래와 같이 계산
- 0, 1처럼 binary confidence score를 계산하는 것이 아리나 더 좋은 box일수록 1에 가깝게 만듦
Confidence branch는 cross-entropy loss를 최소화 하는 방향으로 진행
\[L_{iou}=-y_{k}log(\tilde{y}_{k})-(1-y_{k})log(1-\tilde{y}_{k})\]- $\tilde{y}_{k}$ : 네트워크가 예측한 값
Box refinement branch에서는 smooth-L1 loss function일 이용
Training loss
PV-RCNN은 end-to-end로 3개의 loss에 대한 학습 진행
-
Region proposal loss $L_{rpn}$
- Keypoint segmentation loss $L_{seg}$
- Proposal refinement loss $L_{rcnn}$
Region Proposal loss는 아래와 같이 계산
\[L_{rpn}=L_{cls}+\beta\sum_{r\in\{x,y,z,l,h,w,\theta\}}L_{smooth-L1}(\widehat{\Delta r^{a}}, \Delta r^{a})\]- Anchor classification Loss $L_{cls}$ 는 focal loss로 계산
- $\widehat{\Delta r^{a}}$ : anchor box reidual을 prediction 한 값
Keypoint segmentation loss $L_{seg}$는 focal loss로 계산
Proposal refinement loss $L_{rcnn}$ 은 아래와 같이 계산
\[L_{rcnn}=L_{iou}+\sum_{r\in\{x,y,z,l,h,w,\theta\}}L_{smooth-L1}(\widehat{\Delta r^{p}}, \Delta r^{p})\]- $\widehat{\Delta r^{p}}$ : Predicted box의 residual
최종 loss 는 위의 3개의 loss의 합
\(L_{total}=L_{rpn}+L_{seg}+L_{rcnn}\)
Experiments
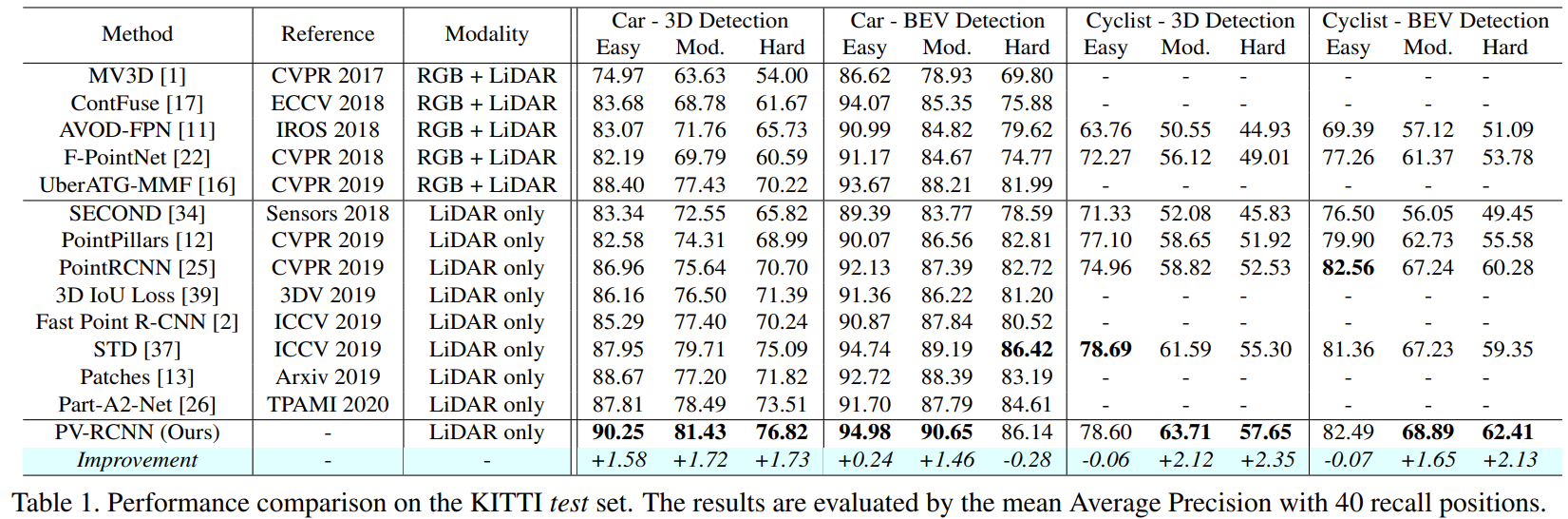
- 2018-2019에 나온 주요 모델들과의 비교 결과, 대다수의 detection PV-RCNN에서 가장 좋음을 확인
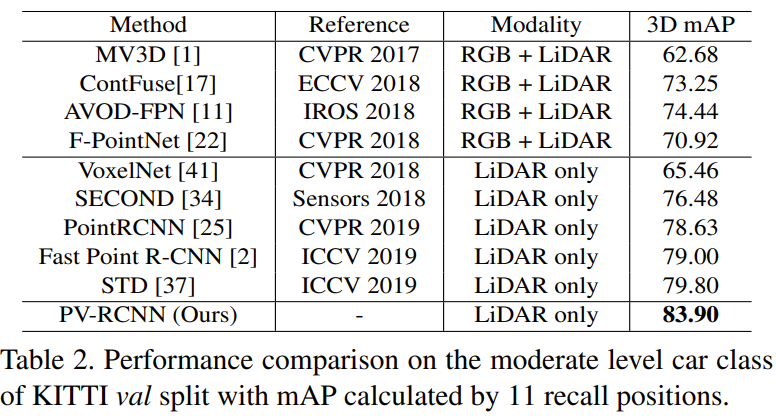
- Moderate level의 car detection도 다른 모델보다 좋은 3D mAP 성능을 보이는 것을 확인
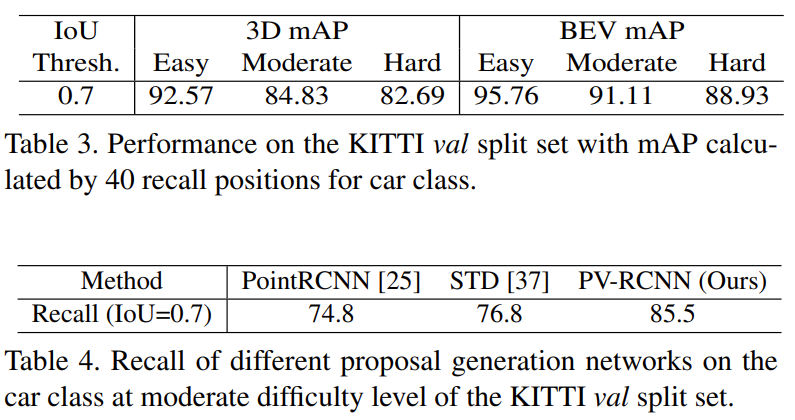
- Car class에 대한 3D mAP와 BEV map 모두 좋은 결과가 나오는 것을 확인
- 다른 proposal 생성 네트워크와 비교해봐도 좋은 성능을 보임을 확인
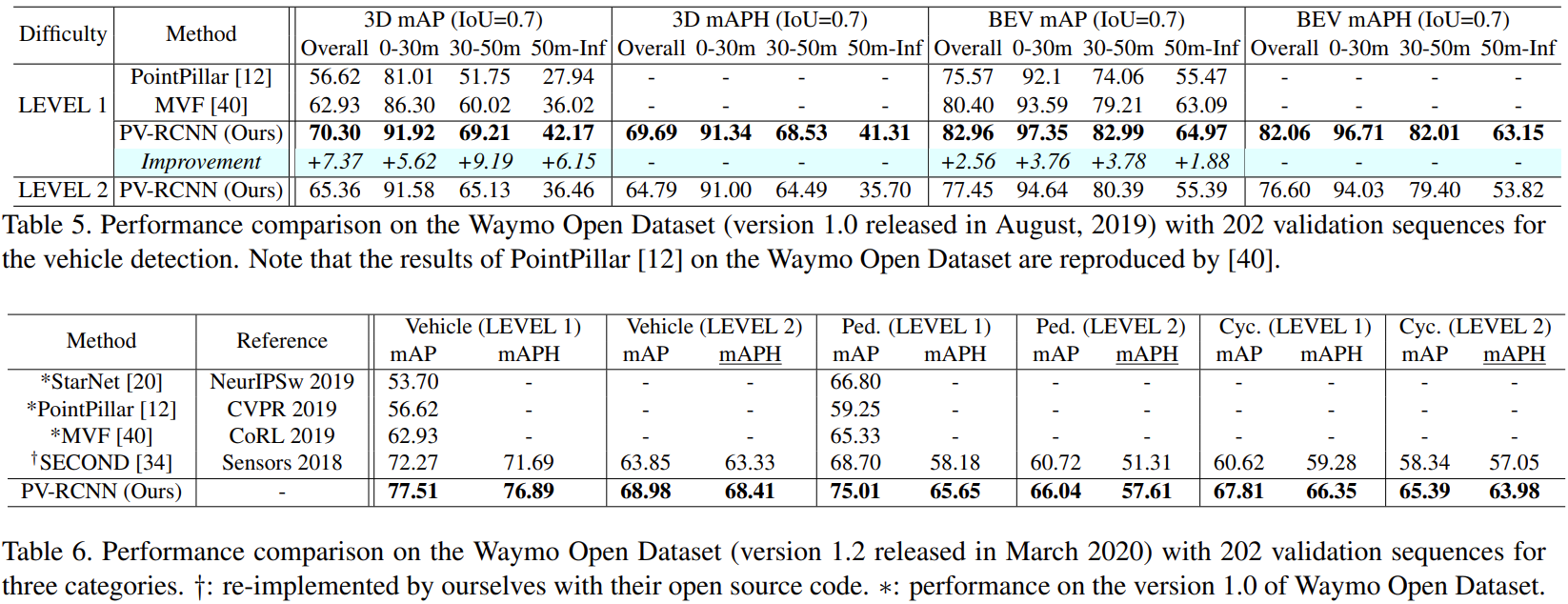
- Waymo Open Dataset에서도 가장 좋은 성능을 보이는 것을 확인
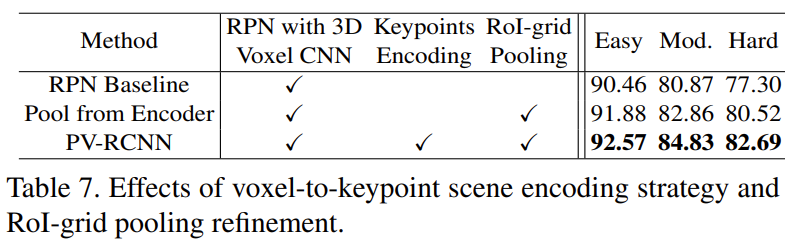
- PV-RCNN은 3가지 방법 모두 사용하여 조금 더 좋은 성능을 가지는 것을 확인

- 서로 다른 feature component가 성능에 얼마나 영향을 미치는지 확인
-
Raw feature만으로는 좋은 성능 얻기 힘듦
- Bird eye view와 raw에 2개 level의 feature만 추가해도 좋은 성능을 가지는 것을 확인