PointRCNN
참고
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
CVPR 2019
Introduction
2D Object Detection이 다양한 view point 와 이미지에서 background 클러스터를 처리할 수 있지만, point cloud를 사용하는 3D object detection에서는 3D object의 불규칙한 데이터 형식과 6 DoF (Degrees-of-Freedom) 의 넓은 범위의 search space 와 같은 어려움이 존재
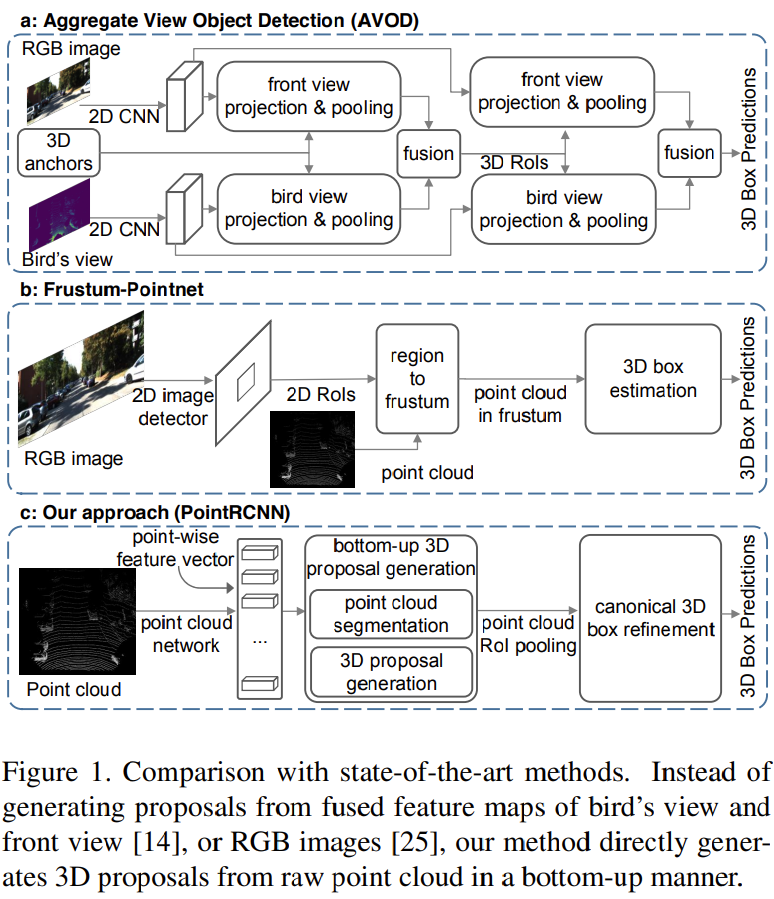
Point-cloud를 기반으로 한 3D object detection은 point cloud의 iregularity 때문에 어려움이 존재
이 문제를 해결하기 위해 point cloud를 bird’s view나 front view로 projection 시켜 2D detection을 사용 (Fig. 1 (a))하거나 regular한 3D voxel로 만들지만 이 방법들은 quantization 과정에 정보 손실 발생
Feature 학습을 위해 voxel과 같은 regular한 데이터 형식으로 바꾸지 않고 Fig. 1 (b)와 같이 2D RGB detection 결과로부터 자른 frustum point를 기반으로 3D bounding box를 예측하기 위해 PointNet 사용
이 방법은 2D object deteciotn 성능에 크게 영향을 받고, robust한 bonding box proposal을 생성하기 위한 3D 정보의 장점 취하기 어려움
2D 이미지와 달리, 자율주행에서 3D object는 annotation된 3D bounding box에 의해 자연스럽게 잘 분리
즉, 3D object detection은 3D object segmentation을 위한 semantic mask를 제공하게 되고 이는 2D object detection에서 bounding box가 semantic segmentation에 약한 weak supervisions 을 제공하는 것과 다름
이를 기반으로 새로운 PointRCNN 이라는 2-stage 3D object detection 제시
3D point cloud를 직접적으로 사용하여 robust하고 정확한 3D detection 성능 얻음 (Fig. 1 (c))
2개의 stage로 구성
첫 번째 stage는 bottom-up 방식으로 3D bonding box proposal 생성을 목적으로 함
3D bounding box를 GT segmentation mask를 만드는데 사용하면서, forehead point를 분할하고 동시에 분리된 point를 기반으로 적은 수의 bounding box proposal을 제안함
이런 방법은 전체 3D 공간에서 많은 수의 3D anchor를 만드는 것을 막을 수 있고 계산을 줄일 수 있음
2번째 단계에서는 canonical 3D box를 정제함
3D proposal이 만들어지고 난 후, 학습된 point representation을 pooling 하기 위해 point cloud 영역을 pooling 연산
Global box 좌표를 직접적으로 추정하는 방법과 달리 pooling된 점들은 canonical 좌표로 변형되고 pooling된 point feature들과 결합되며 stage 1의 segmentation mask는 상대 좌표 교정에 사용됨
stage 1에서의 robust한 segmentation과 proposal sub-network에서 제공하는 정보를 충분히 활용
더 효율적으로 좌표 정제를 학습하기 위해서 , full bin-based 3D box regression loss를 제안
- point cloud 기반의 3D bounding box proposal을 생성하는 새로운 bottom-up 방식의 알고리즘 제안
- Foreground와 background point를 분리하는 것을 통해 적은 수의 고품질의 3D proposal 생성
- Segmentation을 통해 학습된 representation들은 proposal 생성 뿐만이 아니라 box 정제에도 좋음
- Canonical 3D box 정제는 stage 1에서부터 생성한 높은 recall의 box proposal의 이점의 취하고 robust bin-based loss를 이용하여 좌표 정제를 예측하는 것을 학습
- SOTA 모델들보다 좋은 성능을 보임
PointRCNN for Point Cloud 3D Detection
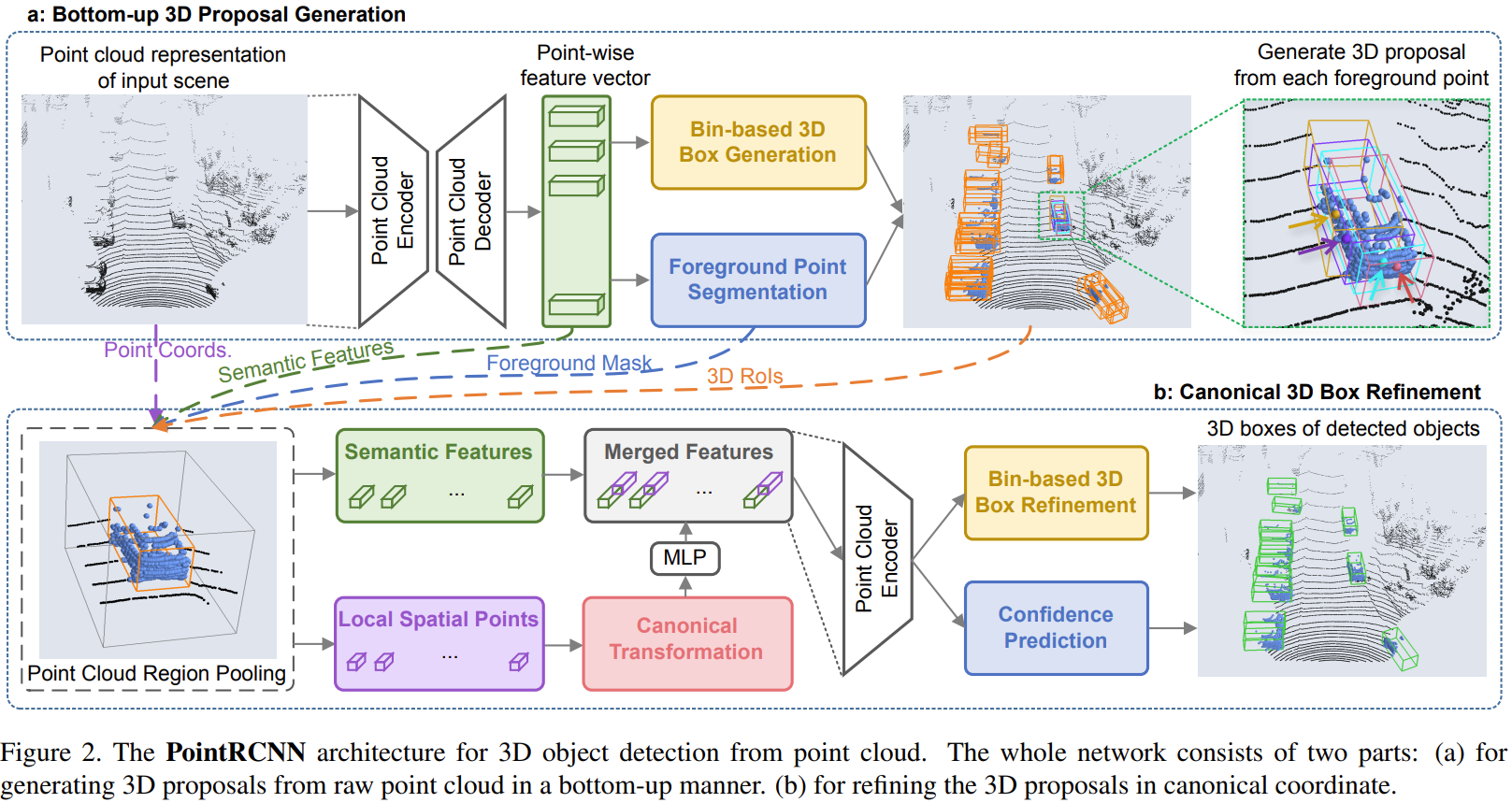
Bottom-up 3D proposal generation via point cloud segmentation
2D object detection 방식을 3D로 바꾸는 것은 쉽지않음
- 방대한 3D search space
- Irregular point cloud
Bottom up 방식의 3D proposal을 생성하는 방식 제안
분리된 raw point cloud로부터 point-wise feature들을 학습하고 동시에 분리된 foreground point들로부터 3D proposal 생성
Bottom-up 방식을 사용하기 때문에 3D 공간에서 많은 수의 미리 정의된 3D box를 만들지 않아도 되고 3D proposal이 생성되는 search space를 제한할 수 있음
실험 결과가 3D anchor-base 방식보다 더 높은 recall을 보여주는 것을 알 수 있음
Learning point cloud representations
가공되지 않은 point cloud로 부터 point-wise feature를 얻기 위해서 multi-scale 그룹화와 함께 PointNet++ backbone 모델로 사용
Backbone 으로 다른 네트워크들이 사용 가능
Foreground point segmentation
Foreground point는 object의 위치와 방향을 예측하는데 풍부한 정보를 제공
Foreground point를 나누는 것을 학습하면서 point-cloud 네트워크는 정확한 point-wise 예측을 위한 풍부한 contextual 정보를 획득할 수 있고, 이는 3D box를 생성하는데 도움이 됨
Foreground point segmentation과 3D box generation은 동시에 진행이 됨
Point segmentation을 위해 3D GT box에서 GT segmentation mask 제공
Point Segmentation의 경우 foreground point가 background point에 비해서 훨씬 적기 때문에 Focal Loss를 사용
- 학습하는 동안 $\alpha_{t}=0.25$ , $\gamma=2$ 로 세팅
Bin-based 3D bounding box generation
Foreground point segmentation과 동시에 진행되며 학습동안 foreground point로부터 3D bounding box 위치를 regression 하기 위해 box regression만 필요
Box들은 background point들로부터 regression 되지 않지만, point cloud의 receptive field 때문에 박스를 생성하는데 도움을 줄 수 있는 추가적인 정보 제공 가능
3D bounding box는 LiDAR에서 $(x,y,z,h,w,l,\theta)$ 로 표기됨
- $(x,y,z)$ : object의 중심위치
- $(h, w, l)$ : 객체 크디
- $\theta$ : bird’s view에서의 object 방향
3D box proposal 생성을 제한하기 위해 bin-based regression loss 사용
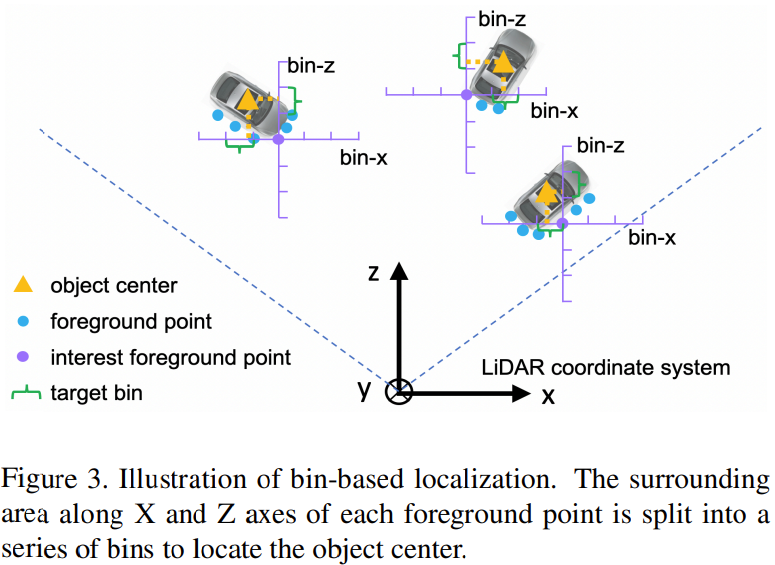
Object의 중심점을 구하기 위해 Fig. 3과 같이 각 foreground point의 주변 영역을 $X$축과 $Z$ 축을 따라 bin으로 나눔
현재 foreground point에서 각 $X$, $Z$ 축에 대해 search range를 $S$로 설정
각 1D의 search ragne는 균일한 길이의 $\delta$롤 나누어져 다른 객체의 중심 $(x, z)$를 나타냄
- 중심점이 어떤 bin에 속해있는지 찾고 grid cell 내에서 fine-tuning 하여 더 정확한 위치 찾는 것
Bin-based classification을 smooth L1 loss가 아닌 cross-entropy loss 사용
- 중심 위치를 찾는데 더 정확하고 robust한 결과
$X$, $Z$ loss는 2가지 term으로 구성
- Bin classification
- Object의 중심점이 현재 연산중인 foreground point의 bin 중 어떤 bin에 존재하는지 찾는 것
- Residual regression (classified bin 안에서의)
- 선택된 bin 안에서 정확한 위치를 찾는 것
중심점 $y$에 대한 예측은 smoothL1 loss를 사용
- y값들의 차이는 크지 않기 때문에 L1 loss 사용하는 것만으로도 충분
Localization targets은 다음과 같이 표현할 수 있음
\[bin_{x}^{(p)}=\left \lfloor \frac{x^{p}-x^{(p)}+S}{\delta} \right \rfloor, \ \ bin_{z}^{(p)}=\left \lfloor \frac{z^{p}-z^{(p)}+S}{\delta} \right \rfloor \\ \underset{u\in \{x,z\}}{res_u^{(p)}}=\frac{1}{C}(u^{p}-u^{(p)}+S-(bin_{u}^{(p)}\cdot\delta+\frac{\delta}{2}))\\ res_{y}^{(p)}=y^{p}-y^{(p)}\]- $(x^{(p)}, y^{(p)}, z^{(p)})$ : interest foreground point 좌표
- $(x^{(p)}, y^{(p)}, z^{(p)})$ : 해당 object의 중심점 좌표
- $bin_{x}^{(p)}, bin_{z}^{(p)}$ :,$X, Z$ 축을 다라 배치되는 ground truth bin
- $res_{x}^{(p)}, res_{z}^{(p)}$ : 할당된 bin 안에서 위치 조정을 한 residual
- $C$ : 정규화를 위한 bin의 길이
방향 $\theta$를 예측하기 위해 $2\pi$를 $n$개의 bin으로 나누고 bin classification target $bin_{\theta}^{(p)}$와 residual regreesion $res_{\theta}^{(p)}$ 를 $x, y$를 구했던 방법과 같은 방법으로 구함
물체 크기인 $(h, w, l)$은 전체 학습 데이터에서의 각 class의 평균 object 크기에 대한 $res_h^{(p)}, res_w^{(p)}, res_l^{(p)}$을 계산
추론할 때는, bin을 기반으로 예측된 $x,z, \theta$에 대해 먼저 예측된 confidence가 가장 높은 bin 중심 선택하고 regression을 추가하여 정제된 값 획득
$y, l, h, w$ 직접적으로 regression된 파라미터들은 초기값에 예측된 regression 더함
전체적인 3D bounding box regression loss $L_{reg}$는 다음과 아래와 같음
\[\begin{align} L_{bin}^{(p)}&=\sum_{u\in\{x,z,\theta\}}(F_{cls}(\widehat{bin}_{u}^{(p)},bin_{u}^{(p)})+F_{reg}(\widehat{reg}_{u}^{(p)},reg_{u}^{(p)}))\\ L_{res}^{(p)}&=\sum_{v\in\{y,h,w,l\}}(F_{reg}(\widehat{res}_{v}^{(p)},res_{v}^{(p)}), \\ L_{reg}&=\frac{1}{N_{pos}}\sum_{p\in pos}(L_{bin}^{(p)} +L_{res}^{(p)}) \end{align}\\\]- $\frac{1}{N_{pos}}$ : foreground point의 수
- $F_{cls}$ : cross-entropy loss
- $F_{reg}$ : smooth L1 loss
중복되는 proposal을 없에기 위해 bird’view의 oriented IoU를 기반으로 한 NMS를 실행하여 적은 수의, 고품질의 proposal 생성
Point cloud region pooling
앞에서 획득한 3D object box를 refine하기 위해 더 specific local feature 필요
이를 위해 stage 1에서 얻은 point-wise feature 사용
각 box proposal $b_{i}$ 크기를 확대하여 다음과 같이 나타냄
\[b_{i}^{e}=(x_{i},y_{i},z_{i},h_{i}+\eta,w_{i}+\eta,l_{i}+\eta,\theta_{i})\]크기를 늘린 새로운 3D box를 만들어 추가적인 context 정보를 더하여 encoding
각 point $p=(x^{(p)},y^{(p)},z^{(p)})$ 에 대하여 점 $p$가 확대된 box 안에 있는지 없는지결정
내부에 있다면 그 점과 해당 point와 이에 해당하는 feature는 $b_{i}$의 정제를 위해 사용됨
특정 proposal에서 내부에 있는 point가 없다면 해당 proposal은 제외
Canonical 3D bounding box refinement
Fig. 2 pooling된 점들과 관련 feature들은 stage 2의 sub-network에 공급되어 3D box 위치와 foreground object confidence를 정제함
Canonical transformation
Stage 1에서 얻은 높은 recall을 가진 box proposal을 활용하고 box parameter의 residual만 측정하기 위해 각 3 proposal에 속하는 pooling된 점들을 canonical coordinate system으로 변환
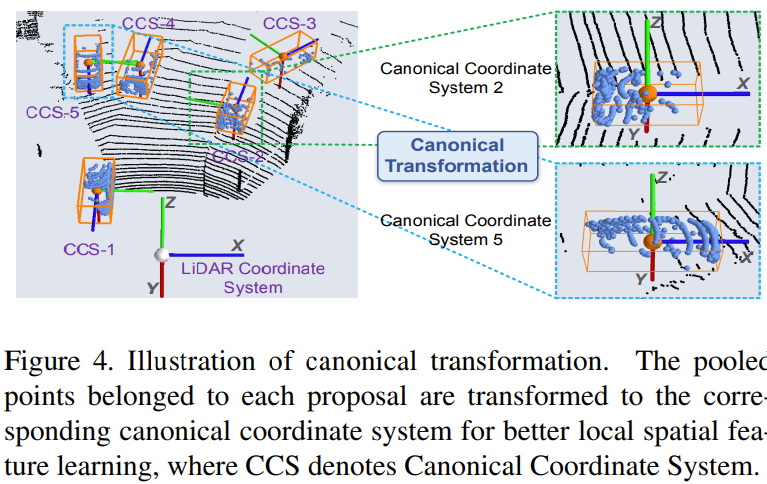
Canonnical 좌표계의 특징
- 원점은 proposal box의 중심에 위치
- $X^{'}$축, $Z^{'}$ 축은 지면에 대략적으로 평행
- $X^{'}$ : obejct heading 방향
- $Z^{'}$ : $X^{'}$ 축과 수직
- $Y^{'}$ 축은 LiDAR의 좌표계 축과 동일
- 지면 아래
Feature learning for box proposal refinement
Canonnical 좌표로 변환하면 spatial feature 학습을 잘 할 수 있지만, depth 정보를 잃게 됨
LiDAR를 이용하여 센싱하면 멀리있는 object는 구성하는 point 수가 매우 적음
Depth 정보를 상싱하는 것을 보상해주기 위해서 변경 전 proposal box와 원점 사이의 거리를 1차원 상수로 추가해줌,
- $d^{(p)}=\sqrt{(x^{(p)})^{2}+(y^{(p)})^{2}+(z^{(p)})^{2}}$
Canonical 좌표계로 변환된 $\tilde{p}$와 point의 reflection instensity $r$, stage 1에서 얻은 Segmentation mask $m$, depth 정보 $d$를 concat한 후 몇 개의 fully-connected layer를 통과시켜encoding 하여 local spatial feature 얻음
이는 global semantic feature와 차원이 같음
- Stage 1의 proposal generation 단계에서 PointNet++를 이용해 얻은 feature를 가지고 옴
- Fig 2에서 초록색 점선
- global 좌표를 이용해 얻은 feature이므로 global semantic feature
Local spatial feature와 global structure feature 다시 concat
- Fig 2에서 merged feature
Merged feature를 PointNet++ 통과하게 하여 다시 discritive feature vector 얻음
이 feature vector는 confidnece prediction과 box refinement를 수행하는 network에 입력으로 들어감
Losses for box proposal refinement
Ground truth box와 3D proposal의 3D IoU가 0.55보다 큰 경우는 refine box 학습을 진행
- Confidence prediction에서 GT box가 할당된 proposal은 positive labe할당되지 않은 proposal은 negative label 할당
3D proposal과 대응되는 3D GT box 모두 canonical 좌표게로 변환 한 뒤 진행
\[b_{i}=(x_{i},y_{i},z_{i},h_{i},w_{i},l_{i},\theta_{i})\\ b_{i}^{gt}=(x_{i}^{gt},y_{i}^{gt},z_{i}^{gt},h_{i}^{gt},w_{i}^{gt},l_{i}^{gt},\theta_{i}^{gt})\]- $b_{i}$는 proposal, $b_{i}^{gt}$는 ground truth
- Canonical 좌표계로 변환된 결과
Box refinement
- 중심점 refinement의 경우 proposal의 중심점에서에서 GT box center로의 regression을 stage-1에서의 bin-based localization과 동일한 방법으로 수행
- 크기 역시 동일하게 average object 크기에 대한 residual을 regression
- 방향은 IoU가 0.55이상인 proposal과 매칭한 점을 고려히여 각도 residual을 $[−\pi/4,\pi/4]$로 한정한 뒤 동일하게 bin-based로 regression을 수행
Confidence prediction
- GT box가 할당된 proposal은 positive label을, 할당되지 않은 proposal은 negative label을 할당
- Cross entropy loss
Stage 2의 sub-network의 최종 loss는 다음과 같음
\[\begin{align} L_{refine}&=\frac{1}{||B||}\sum_{i\in B}F_{cls}(prob_{i}, label_{i})\\ &+\frac{1}{||B_{pos}||}\sum_{i\in B_{pos}}(\tilde{L}_{bin}^{(i)},\tilde{L}_{res}^{(i)}) \end{align}\]- $B$ : stage 1에서 나온 3D proposal 집합
- $B_pos$ : regression을 위한 positive proposal
Experimental
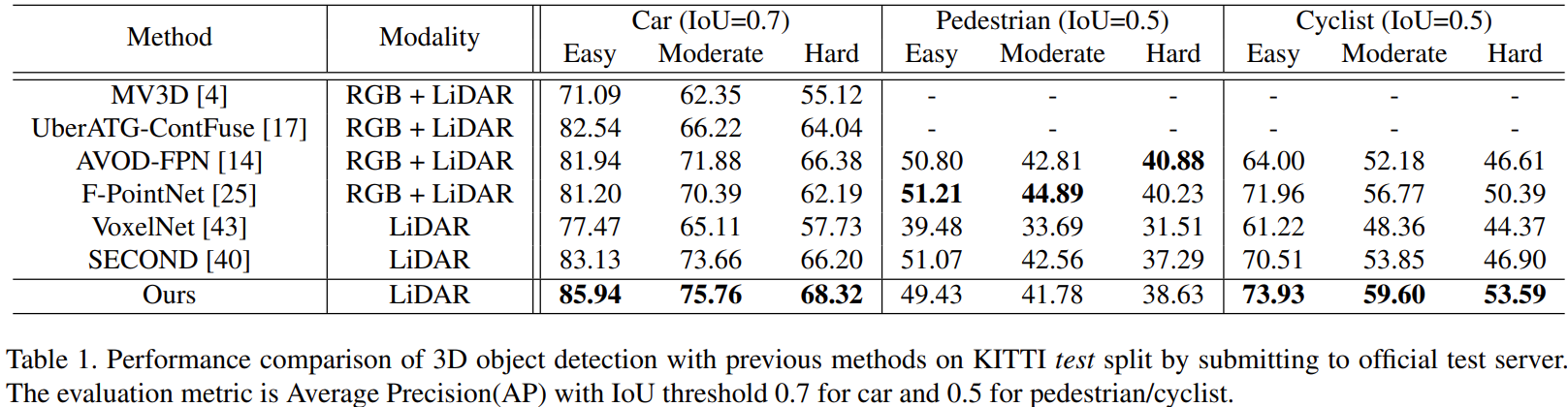
- Car와 Cylist에 대해서는 가장 좋은 성능을 보임
- Pedestrian의 경우는 성능이 비교적 낮지만, SECOND와 비슷
- 하지만 RGB 이미지를 이용한 F-PointNet과 Voxel을 활용한 SECOND와는 다르게 point cloud를 입력으로 좋은성능을 보임
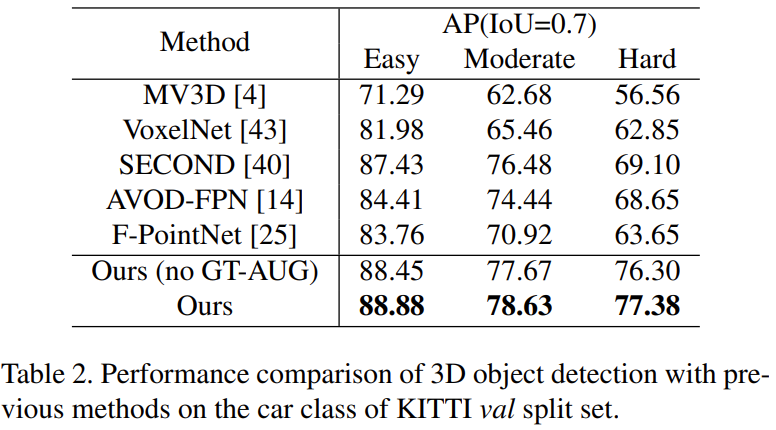
- Car class에 대해 더욱 자세히 보면 Easy, Moderate, Hard 모든 부분에서 PointRCNN의 성능이 가장 좋음을 확인
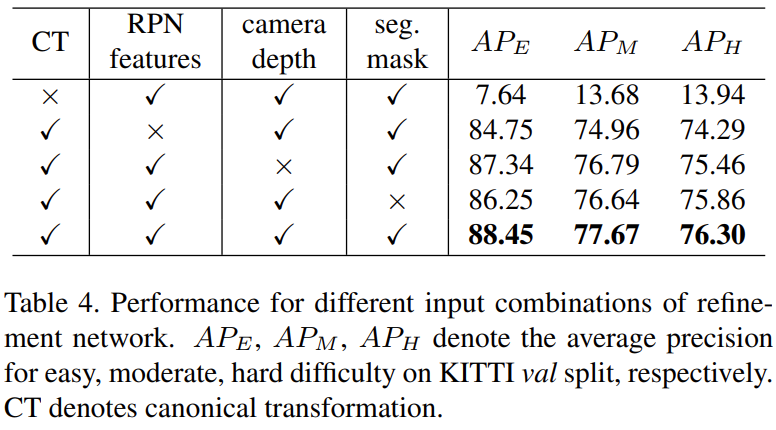
- 4가지 refinement 요소 중 하나씩 빠졌을 때 성능 저하를 확인하여 네 요소의 중요성을 강조
- 모두 사용하는 경우가 성능이 가장 좋고 모든 요소가 성능에 영향을 주는 것을 확인
- Canonical traonsformation이 빠지는 경우는 성능에 많은 영향을 미치는 것을 확인

- 보라색 선이 heading 방향 나타내는 것인데 잘 나타내는 것을 확인
- 자동차 객체를 잘 검출함을 그림으로 증명
Conclusion
Point cloud 입력을 직접 사용하는 네트워크 제안
Point cloud segmentation 기반의 proposal network 제안
정확한 Local Spatial feature 학습을 위한 refinement 방법 제안
기존 연구 대비 좋은 성능 도출