PointPillars: Fast Encoders for Object Detection from Point Clouds
참고
CVPR 2019
Introduction
Point Cloud와 computer vision에서 사용하는 image는 비슷한 점이 있지만 크게 2가지가 다름
- Image는 dense representation이지만, point cloud는 sparse representation
- Image는 2D, point cloud는 3D
이러한 점 때문에 point cloud의 object detection에 image convolutional pipeline을 사용하는 것은 쉽지 않음
초기에는 3D convolution이나 point cloud를 이미지로 projection 하는 연구에 집중했으나 현재는 LiDAR point cloud를 bird’s eye view로 보는 방법이 트랜드
이런 방법은 scale의 모호성을 없애고, occulusion을 줄여줌
하지만 BEV는 sparse 하여 CNN을 직접 사용하기 효율적이지 않음
이 방법을 해결하기 위한 일반적인 방법은 ground plane을 regular grid로 나누어 각 grid cell에 존재하는 point들에 대하여 hand crafted featrue encoding을 진행하는 방법이 있으나 일반화 하기 힘듬
VoxelNet은 3D object detection에서 end-to-end 학습이 가능한 첫 모델로 space를 voxel로 나누고 각 voxel에 PointNet을 적용하여 3D convolutional middle layer를 거쳐 RPN을 적용하는 과정을 거침
VoxelNet은 성능은 좋으나 실시간으로 적용하기 추론 속도가 느리다는 단점이 있음
최근 SECOND 이 추론 속도를 올렸으나, 3D convolution의 bottleneck이 됨
이 논문에서는 2D convolution layer만 사용하고 end-to-end 학습이 가능한 3D object detection 모델인 PointPillars을 제시
Pillar에서 feature를 학습하는 새로운 encoder로 3D oriented box를 예측
이 방법은 몇 가지 이점이 존재
- Fixed encoder 대신 feature를 학습하므로, point cloud에 표현된 전체 정보 활용 가능
- Voxel 대신 pillar를 이용하여 vertical 방향을 직접 나누지 않아도 됨
- 모든 중요 연산들이 gpu에 최적화된 2D convolution 사용 가능하므로 효율적
- 학습한 feature를 이용하기 때문에 다른 point cloud configuration을 사용하더라도 hand-tunning 할 필요가 없음
Contribution
- 새로운 point cloud encoder와 network인 PointPillars 제안
- End-to-end로 학습이 가능한 3D object detection 모델
- Pillar에서 모든 계산은 dense 2D convolution을 적용 가능
- 다른 방법들에 비해 2 - 4 빠른 요소
- KITTI dataset으로 실험하여 SOTA 성능 보임을 확인
PointPillars Network
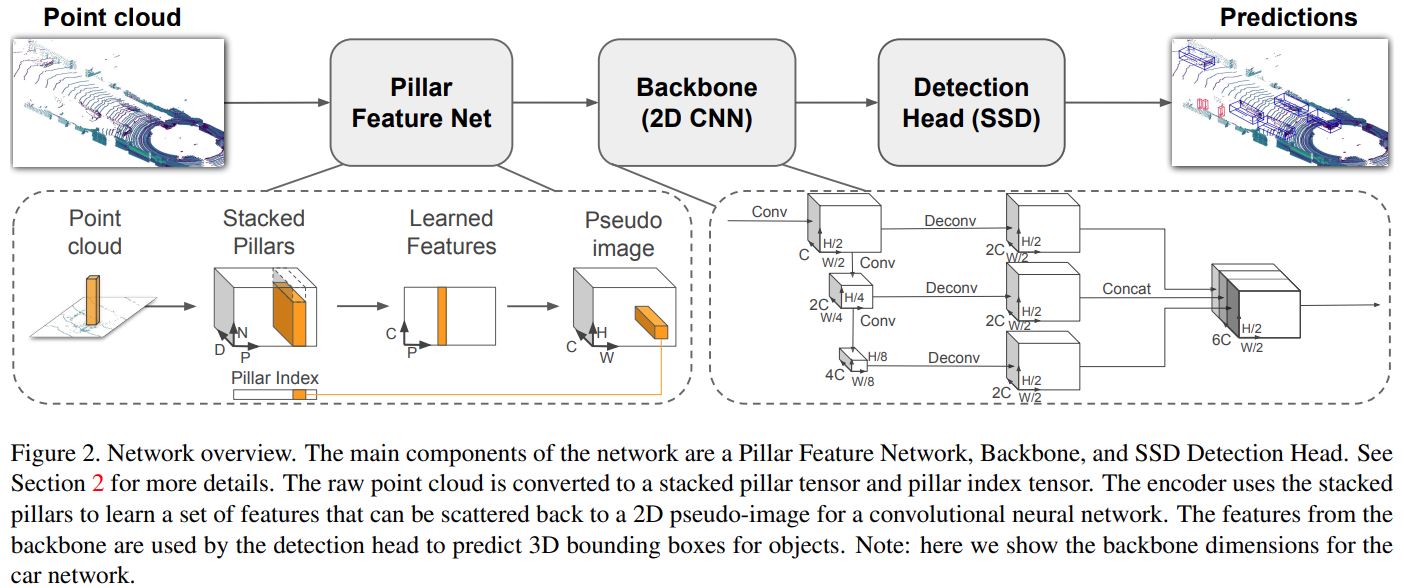
Point cloud를 입력으로 받아 차량, 보행자, 자전거 타는 사람에 대한 oriented 3D box를 예측하는 네트워크
3개의 주요한 단계로 구성
- Feature enocder network
- Point cloud를 sparse pseudo-image 로 변환하는 과정
- 2D convolution backbone
- Pseudo image를 high-level representation 으로 만드는 과정
- Detection head
- 3D box를 검출하고 예측하는 과정
Pointcloud to Pseudo-Image
Point cloud의 한 poin $l$은 $x$, $y$, $z$ 좌표와 reflectance $r$을 가짐
우선 $xy$ 평면 공간을 균등하게 나누어 pillar 집합 $P$
$z$ 차원으로 나눌 필요는 없음
각 pillar에 존재하는 point들은 $x_{c}$, $y_{c}$, $z_{c}$, $x_{p}$, $y_{p}$ 로 변환
- $x_{c}$, $y_{c}$, $z_{c}$ 는 각 pillar에 존재하는 point들의 산술 평균점과의 거리
- $x_{p}$, $y_{p}$ 는 pillar의 중심 $x$, $y$ 좌표로부터 떨어진 거리
이 점들을 추가하여 9차원($D=9$)의 $l$을 만듦
\[l=(x, y, z, r, x_c, y_c, z_c, x_p, y_p)\]Pillar 대부분 비어있고, 비어있지 않은 pillar들은 일반적으로 점이 거의 없음
- Point cloud가 sparse하기 때문
각 Sample의 비어있지 않은 pillar의 수($P$) 각 pillar의 point 수 ($N$) 에 제한을 두어 dense 한 tensor를 생성 ($D, P, N$)
만약 sample이나 pillar가 너무 많은 point를 가지면 random sampling을 하고 너무 적은 경우 zero padding을 적용
위와 같은 과정으로 만든 stacked pillars를 간단하게 변형한 PointNet의 입력으로 넣어 BN, ReLU layer를 지나 $(C, P, N)$ 크기의 tensor를 생성
- Linear layer는 1x1 convolution 처럼 작동
Feature encodeing이 되고 나면, feature들은 다시 원래 pillar 위치로 돌아가 $(C,H,W)$ 크기의 pseudo image가 생성됨
Backbone
2개의 sub-network로 구성
- Top-down Network
- 작은 해상도의 feature 생성
- Secone Network
- 각 convolution을 거친 feature map upsampling 하고 concate
Detection Head
Single Shod Detector (SSD) setup을 사용하여 3D object detection 수행
Bounding box의 regression에 height와 elevation을 추가하여 사용
Implementation Details
Network
Network의 parameter들은 학습된 값이 아닌 uniform 분포를 통한 랜덤한 값으로 초기화
Encoder를 통해 64 차원의 feature 얻음
Car, pedestrain/cyclist는 각각 $S=2$, $S=1$의 stride 가짐
Top Down Network는 Block1(S, 4, C), Block2(2S, 6, 2C), Block3(4S, 6, 4C)
각 block은 Up1(S, S, 2C), Up2(2S, S, 2C) and Up3(4S, S, 2C)로 upsampling
Up1, Up2, Up3은 6C 차원의 feature 가짐
Loss
SECOND 에서 소개된 loss와 같은 loss function 사용
GT box와 anchor는 $(x, y, z, w,l,h,\theta)$ 로 정의
GT와 anchor 사이의 localization regression residual은 아래와 같이 표현
\[\Delta x=\frac{x^{gt}-x^{a}}{d^{a}},\ \ \Delta y=\frac{y^{gt}-y^{a}}{d^{a}}, \ \ \Delta z=\frac{z^{gt}-z^{a}}{d^{a}}\\ \Delta l=log(\frac{l^{gt}}{l^{a}}), \ \ \Delta w=log(\frac{w^{gt}}{w^{a}}), \ \ \Delta h=log(\frac{h^{gt}}{h^{a}}) \\ \Delta \theta = sin(\theta^{gt}-\theta^{a})\]- $d^{a}=\sqrt{(l^{a})^{2}+(w^{a})^{2}}$
종합적인 localization loss 는 아래의 식과 같음
\[L_{loc}=\sum_{b\in (x,y,z,w,l,h,\theta)}SmoothL1(\Delta b)\]Angle localization loss만으로는 flip된 box를 구별하지 못하므로 네트워크가 물체의 heading을 학습할 수 있도록 softmax classification loss를 $L_{dir}$ 에 적용
Object classification loss 에는 focal loss를 사용
\[L_{cls}=-\alpha_{a}(1-p^{a})^{\gamma}log\ p^{a}\]- $p^{a}$ : anchor의 class probability
- $\alpha=0.25$, $\gamma=2$
- Origin paper의 셋팅 값 사용
Total Loss는 아래와 같음
\[L=\frac{1}{N_{pos}}{\beta_{loc}L_{loc}+\beta_{cls}L_{cls}+\beta_{dir}L_{dir}}\]- $N_{pos}$ : positive anchor의 수
- $\beta_{loc}=2$, $\beta_{cls}=1$, $\beta_{dir}=0.2$
Results
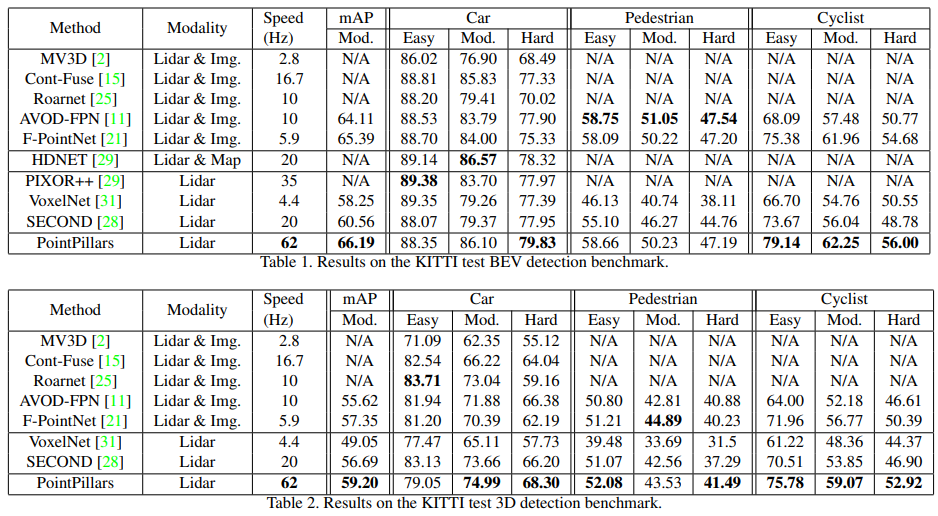
- BEV, 3D detection에서 다른 SOTA 모델보다 더 좋은 mAP 성능을 보임을 확인
- 좋은 성능과 함께 속도가 매우 빠른 것을 확인 가능

- mAP는 객체 방향에 대한 detection 성능 평가하지 못함
- 이를 확인하기 위해서 AOS (Average Orientation Similarity) 지표 활용
- Pedestrian 을 제외하고는 성능이 가장 좋음
- 속도는 다른 방법과 비교하여 매우 빠름을 확인

- Figure 3은 detection 결과를 tight oriented 3D bounding box로 보여줌
- Car에 대한 detection 결과 정확하지만 부분적으로 occlusion이 발생하거나 먼 거리에 있는 object에 대한 예측을 실패 (false negative)
- 또는 van이나 tram 같이 비슷한 class에 있는 경우 예측 실패 (false positive)
- Pedestrian과 cyclist에 대한 detection은 car를 detection 하는 것보다는 더 어려움
Conclusion
PointNet을 활용한 새로운 point cloud encoding 방법 제안
Pillar 단위로 point를 묶어 빠른 속도로 추론하는 것이 가능
Dense tensor 구조로 Pseudo image 도출
속도와 성능 모두 다른 알고리즘보다 뛰어남을 보임